









by Nikhil Kumar Jha, Sebastian von Enzberg and Michael Hillebrand (Fraunhofer IEM)
The use of deep learning algorithms is largely restricted to application domains where a large amount of labelled data is readily available, e.g., computer vision. Thus, applications of deep learning in autonomous systems for Industry 4.0 are rare. The application of deep learning to anomaly detection within autonomous systems for Industry 4.0 is a current research topic at Fraunhofer IEM. Our latest studies deliver some promising anomaly detection models as well as automated configuration of model hyperparameters.
A system is considered “autonomous” when it makes and executes decisions based on its current state to achieve certain goals, without any human intervention. The research project “KI4AS – Validation of Artificial Immune Systems for Autonomous Systems” focuses on the resilience of autonomous systems by adapting self-healing properties. The use case at hand is a prototype of a mobile robotic system deployed in a smart factory, which travels from one checkpoint to another using autonomous navigation algorithms and heterogeneous sensor data. Being critical in the nature of the operation, mechanisms are needed to ensure system’s robustness in unforeseen situations. Data from the onboard sensors can be monitored and analysed in order to detect deviations from normal behaviour. System reconfiguration or recovery methods can be applied subsequently. Anomaly detection methods identify data samples that do not conform with the expected behaviour of the data generating process. These events either implicate immediate serious consequences, or result from a previously unobserved elemental process. Establishing reliable supervised observation rules to detect anomalies is difficult due to the domain complexity and uncertainty. Also, they imply high costs incurred during the modelling of normal behaviour by the domain experts make such model-based solutions obsolete. This work aims at exploring the data-driven methodologies to meet the Industry 4.0 demands of achieving dynamic monitoring of anomalies in real-time autonomous systems while focussing specifically on the deep learning solutions present in the literature.
Recent advances in technology have resulted in an increase in the number of sensors on such autonomous systems, and more frequent sampling. The concomitant increase in the complexity of the underlying patterns in the dataset makes it impossible for conventional machine learning methods to capture the underlying information and structure. Their inability to scale and perform well with the unlabelled, class-imbalanced dataset also poses a serious challenge when it comes to anomaly detection. In this context, we have focused on three areas of research: deep learning methods, feature selection and hyperparameter optimisation.
Deep learning methods are able to robustly learn from large-scale data without needing manual feature engineering. In anomaly detection, they operate with limited label information i.e., knowledge of one-classed “normal” data only. In this case, the deep learning model represents a profile for normal data samples. Patterns that do not conform to the normal behaviour are identified subsequently by explicitly isolating them based on a measure of abnormality (e.g., distance norm). In our current research, we have investigated, evaluated and compared three deep learning models, each offering their own advantages [1]: autoencoder, long short-term memory encoder-decoder [L1], and deep autoencoding gaussian mixture model [L2].
When datasets have high dimensionality and sample-sizes, the model learns from, and is thus negatively affected by, extraneous and insignificant features. Feature selection [3] is a way of identifying a subset of important features that can perform the required prediction task, with similar or better performance. For this use-case, we have researched two methods: weighting K-means and LASSO, with weighting K-means showing more promising results.
Another important aspect governing how efficiently the model can generalise over the given data is the selection of an optimal set of hyperparameter setting. Discrete measures in an algorithm like the learning rate, batch size, size and number of layers in the neural network, etc., need finely tuned values to optimally learn the data patterns and optimise the objective function guiding the learning problem. This is achievable by using hyperparameter optimisation [2]. The hand-designed values have always been susceptible to flaws, so automating this process in this work, is the next step in the direction of making the field of machine learning more prosperous and promising.
Several exhaustive experiments on different operating scenarios were made, they are summarised in Figure 1. The primary objective was to evaluate different state-of-the-art algorithms against the anomaly detection task. Figure 2 shows the results of the validated deep learning methods and signal plots for the winning model. The plots help the user to understand and correlate the system behaviour at the time of anomaly detection. The red vertical line represents a detected anomaly, while its width gives an idea about the duration of the detected anomaly. The last subplot is essentially a depiction of the detected and the ground truth anomaly (blue dots).
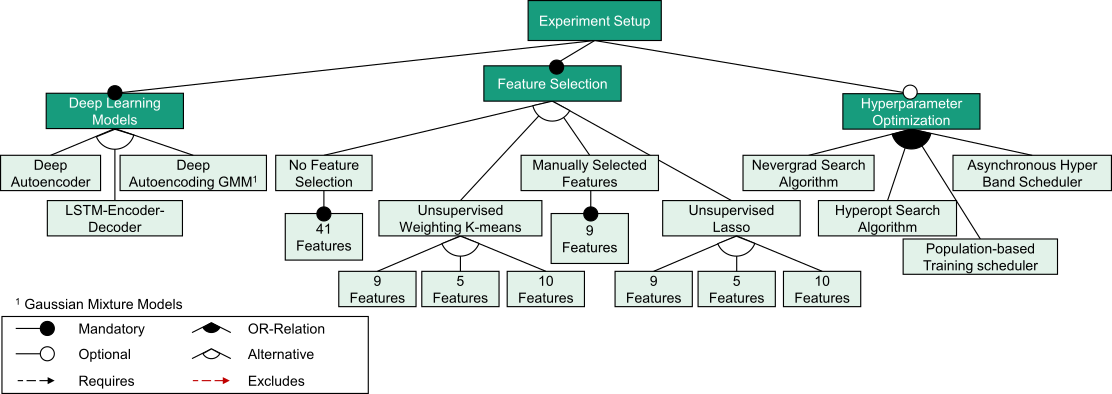
Figure 1: The figure summarises the experiments to evaluate the performance of the models. It drafts the different scheduling and search algorithms used for the hyperparameter optimisation task, and also accounts for the various feature subsets created using the feature selection techniques.
The LSTM-ED model performed best with an F1-measure of 0.751. Not only did it have the best classification performance, but it is also promising in terms of resource consumption and model inference time. While several state-of-the-art models were evaluated in this work, to our knowledge, no previous study has dealt specifically with the task of anomaly detection using deep learning methodologies on a real-world autonomous system use case. Our work also took the research to a deeper level by combining the unsupervised feature selection techniques along with hyperparameter optimisation performed to determine the best configuration settings and procure competent models.
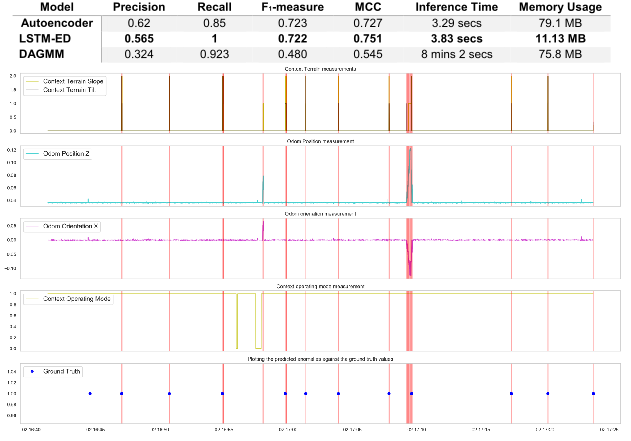
Figure 2: The table shows the quantitative comparison between the most promising configurations for the three deep learning models by using different metrics for classification performance, resource consumption and time taken for inference. Owing to heavy class-imbalance, the metric Matthews correlation coefficient (MCC) is preferred for a reliable statistic. For the best-performing LSTM-ED, the detected anomalies (red vertical lines) are plotted against anomaly ground truth (blue dots) and system signals. Anomalies visibly correlate with the spikes or the irregular behaviour in individual signals.
Links:
[L1] https://arxiv.org/abs/1607.00148
[L2] https://sites.cs.ucsb.edu/~bzong/doc/iclr18-dagmm.pdf
References:
[1] Chalapathy et al.: “Deep Learning for Anomaly Detection: A Survey” https://arxiv.org/abs/1901.03407
[2] Liaw et al.: “Tune: A Research Platform for Distributed Model Selection and Training” https://arxiv.org/abs/1807.05118
[3] Alelyani et al.: “Feature Selection for Clustering: A Review” http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.295.8115&rep=rep1&type=pdf
Please contact:
Nikhil Kumar Jha, Sebastian von Enzberg, Michael Hillebrand, Fraunhofer IEM, Germany

