









by Théophile Gaudin, Oliver Schilter, Federico Zipoli and Teodoro Laino (IBM Research Europe)
In many material manufacturing processes nowadays a large amount of data is created and stored, often without utilizing them to the full potential because of their complexity. Applying state of the art deep learning techniques can be a powerful tool to extract knowledge out of them allowing to get useful insights. In this work we present autoencoder-based machine learning models to find links among composition, properties and processes applied to two prototypical industrial applications.
In any modern industrial plant, a myriad of data is generated by sensors or by the recording of various input parameters. This stream of data is important for various reasons, including reproducibility and quality control. With abundant and diverse data, machine learning can be used to extract information about the process itself, allowing us not only to predict outcome properties, but also to improve manufacturing parameters. In most cases, some of the input parameters are independent. For instance, a formulation (alloy or polymeric material) with a specific composition can undergo various processes and one single process can be applied to various formulation compositions. Here, we present variational autoencoders to generate continuous representations of the independent parameters in a reduced space, which is called latent space. We use the latent space to perform an optimisation of the parameters that can be conditioned on part of the input (i.e., given the composition of a formulation, finding the parameters that would yield the highest tensile strength). Our framework is illustrated in Figure 1.
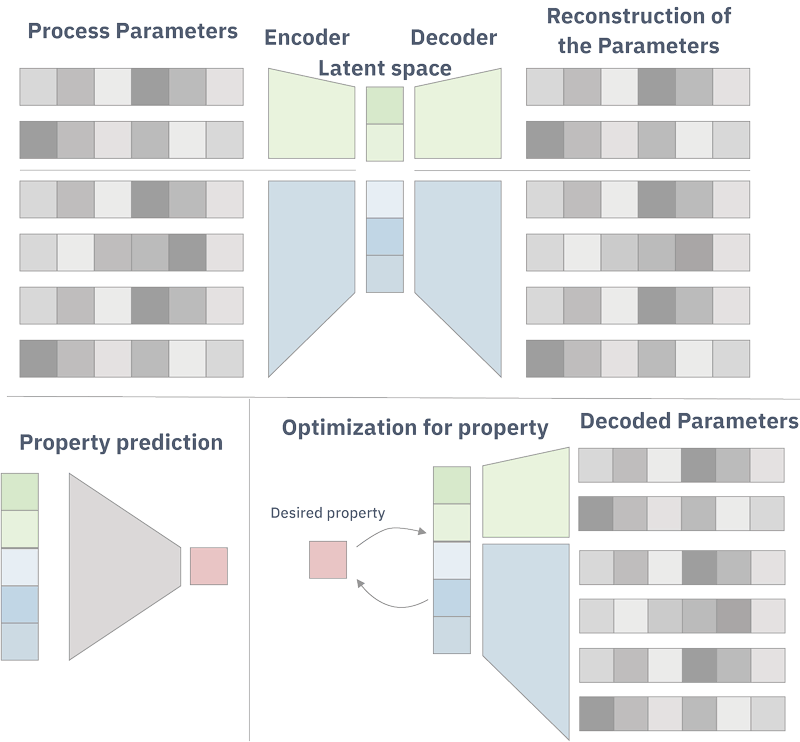
Figure 1: Overview of the model. Process parameters are encoded to the latent space and then reconstructed by a decoder. From the trained latent space, the property can be predicted by an additional neural network. It is also possible to search the latent space to optimise the parameters using a Gaussian process.
An autoencoder consists of two neural networks: an encoder and a decoder. The encoder converts an input into a fixed sized vector called latent representation. The decoder reconstructs the input given the latent representation. Autoencoders are usually trained to minimise the reconstruction error. Kingma and Welling [1] introduced a variational autoencoder where an additional constraint is added to the encoder so that it produces a more robust representation.
The proposed method uses different autoencoders, one for each group of independent parameters. Going back to the formulation example and its characteristic processes, we have an autoencoder for the composition of the formulation and another to encode the sequence of processing steps. From these autoencoders we constructed a latent representation from which we can predict various properties (in the case of an alloy, these may be mechanical properties and for polymeric materials, physico-chemical properties) using an extra neural network. For a mere prediction of the formulation properties one could directly use a neural network that takes process parameters as input and outputs the properties values. Instead, inspired by the work of Gomes-Bombarelli et al. [2] in the domain of molecular structure prediction, we opted for the construction of latent spaces, enabling the use of Gaussian processes to identify points that have certain desired properties. These points are then decoded back to the input parameter space. This approach has three advantages. Firstly, it allows mapping a discrete parameter space to a continuous one. Secondly, the latent space has fewer dimensions than the parameter space, making it easier to search. And finally, this approach could lead to solutions that have not yet been observed in the dataset. This flexible framework with different autoencoders also allows the search to be conditioned on a part of the parameters. For instance, we can look for a specific process yielding the highest tensile strength given an alloy composition.
The presented structure is general enough to be adaptable to a variety of material design problems. For example, in addition to modelling the alloying process of metals, the same approach can be used to model an extrusion process for polymers. In this case, our training data consists of formulations and processes, and in some cases also aging conditions. The data was encoded into three latent representations, one for each data type. The trained model for polymers makes it possible to optimise the composition of a recipe for a known process to get a desired property value; analogously, the same model could also optimise a set of processing condition parameters for a given composition. After the optimisation of a property, the model returns points in the latent space representation, which can be decoded either to the corresponding chemical composition of the polymer or to process parameters. These results can be utilised to optimise recipes and fine-tune process parameters.
In conclusion, this data-driven approach to the design and fabrication of novel materials via encoder-decoder based models offers a promising way to compress the data into a reduced latent space to improve the material design task. The benefit of this framework is its general applicability to any kind of data.
References:
[1] D. P. Kingma and M. Welling: “Auto-encoding Variational Bayes”, ICRL 2014. https://arxiv.org/abs/1312.6114
[2] R. Gómez-Bombarelli, et al.: “ACS Central Science”, 2018, 4, 268–276.
Please contact:
Théophile Gaudin
IBM Research Europe, Switzerland

