









by Enrique Garcia-Ceja, Åsmund Hugo, Brice Morin (SINTEF) and Per Olav Hansen (Unger)
Process optimisation within industry can reduce production times, as well as material and energy consumption, which translates to more efficient use of resources and money. In the chemical production industry, soft-sensing and machine learning technologies can help to optimise processes.
Digitalisation and automation technologies have permeated industrial processes, and are used, for example, to reduce waste and increase product quality and production rates. These benefits, which have huge impacts on user satisfaction and the environment, are achieved largely through “optimisation”; the efficient use of resources such as time, materials and machines.
In recent years, a new approach, “soft-sensing”, has been used to foster optimisation. Soft-sensing uses easy-to-measure variables to predict other variables that are impractical or more expensive to sense (Figure 1). This scenario is common in chemical processes that often take place in harsh environments in which monitoring may be hazardous and require highly specialised and expensive sensors [1]. In this context, soft-sensing technologies can replace expensive monitoring tasks with software algorithms fed from different data sources, for example, sensor readings. Soft-sensing relies on two key ideas: data and prediction. Machine learning is thus an ideal candidate to support soft-sensing operations.
We trialled the use of soft-sensing and machine learning to optimise a chemical process in Unger Fabrikker, a chemical factory in Norway. Unger produces surfactants: compounds used in personal care and laundry products, such as shampoo, toothpaste, soap, detergents and bleach. Unger uses a sulphonation process to produce surfactant variations appropriate for the final product. When transitioning from one product to another, there is a production gap of about 30 minutes, during which waste is produced and an operator needs to take samples and analyse them manually. The output of this analysis is a neutralisation number (NT) that measures the quality of the product.
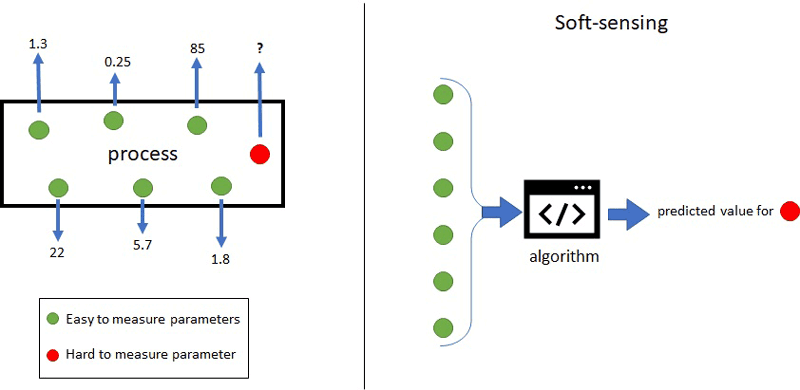
Figure 1: A process with six parameters that are easy to measure and one that is hard to measure (left), and an algorithm that predicts the hard to measure parameter based on the others (right).
Predicting the NT value is an expensive task, so to reduce the 30 minute gap, we used soft-sensing and machine learning as the predictive engine to infer the NT value automatically based on other process parameters, such as amount of air injected to the sulphur oven and converter, current amount of sulphur, quantity of organic material and air temperature. Together with Unger Fabrikker, SINTEF and Østfold University, we conducted experiments where we trained different machine learning regression models including a random forest and a neural network to predict the NT value based on the other process parameters. To evaluate the generalisation performance of the models, we trained them using 70% of the data and evaluated the results on the remaining 30%. The data consisted of 14,252 historical measurements. From our experiments, random forest obtained the best results with a mean absolute error of 0.089 compared to 0.115 with a neural network. It is worth mentioning that the data contains some noisy measurements which were manually identified by an expert and removed before training the models. These results show that the quality control task can be reduced from half an hour to a couple of seconds. The machine learning models have been incorporated into the monitoring system and their results are stored in a database for further validation.
We are currently testing machine learning methods to automatically identify outlier measurements. Preliminary promising results show that it is possible to identify outliers using an ensemble learning approach, that is, combining multiple predictive models. We trained three classifiers that predict whether a point is an outlier or not based on the process parameters. The models were one random forest and two Naïve Bayes classifiers. The final result is obtained by taking the majority vote of the three. This approach was able to detect 82.6% of the outliers. The outlier detector is currently being tested in the real system.
Additionally, we are testing a new near infrared (NIR) sensor developed by Prediktor [L2] to infer the product quality based on its readings. The NIR instrument is installed in the production flow in one of the reactors. Machine learning algorithms are fed with data from the spectrum values captured with the NIR instrument to estimate the product quality. This has the advantage of providing additional information, such as indicating whether the process is in a stable phase or not. Data collected during changeover between products is also analysed. In this changeover phase the NIR instrument provides information that can be used to build a model that could potentially make the changeover between products automatically.
In summary, soft-sensing and machine learning technologies are allowing Unger to perform processes more efficiently and have opened new opportunities to optimise other operations.
The work [2] was conducted as part of one of the use cases of Productive 4.0 [L1], an EU ECSEL project with one of its goals being the design and development of Internet of Things (IoT) technologies, including hardware and software for the digital industry.
Links:
[L1] https://productive40.eu
[L2] https://www.prediktorinstruments.com
References:
[1] S. Zhang, et al.: “Online quality prediction for cobalt oxalate synthesis process using least squares support vector regression approach with dual updating”, Control Engineering Practice, 2013.
[2] E. Garcia-Ceja, et al.: “Towards the Automation of a Chemical Sulphonation Process with Machine Learning”, ICCMA 2019, IEEE.
Please contact:
Enrique Garcia-Ceja, SINTEF, Norway
Per Olav Hansen, Unger, Norway

