









by Christopher Ganz (ABB Future Labs)
In recent years AI has rapidly developed across many fields, finding its way into applications where it hasn’t succeeded previously, and reaching into areas that were unthinkable even a few years ago.
AI and machine learning (ML) have found their place in industry. With machine learning showing its particular strength in areas that map an input data set to an output set or conclusions, its predominant applications are becoming those of classification or perception. Current success stories around ML applications often focus on condition monitoring: determining the current health status of an asset, based on a given set of measurements. The inclusion of data that led to a failure not only allows diagnosis of failures, but also prediction of failures, giving the operator a chance to reduce or stop production and resolve the issue.
Perception applications that have been widely used in consumer goods (e.g., image, video and voice recognition and natural language processing) are now being adapted to industrial settings. Whether it is video-based quality control, voice-controlled equipment, or other means of assessing plant status through sound, image, or video analysis, consumer algorithms are improving the overall performance of the plant in industrial settings.
In many cases, key performance aspects are not defined during operation, but earlier in the design process: the engineering phase. Design decisions influence the subsequent performance of a plant.
Industrial value chains
Process industries vs. discrete
Figure 1 shows a simplified view of the value chain, from raw material extraction through to a finished product in the hands of the consumer. The requirements for the engineering process to build the plants along that value chain vary. In raw material extraction and process industries, as well as utilities, continuous production of material prevails. Material is mostly transformed in a continuous process, which in some cases can run uninterrupted for days, months or even years. The production process varies little. Required adaptations, largely due to input material variations or variants produced, can mostly be handled through parameter variations in the production process. The process generally remains as engineered for very long periods, even for the entire plant lifecycle.
As the production process progresses towards the customer, it moves from a continuous flow of material to the production of individual devices (discrete manufacturing) in distinct production steps. Capital goods are mostly built to order based on customer specifications, and consumer products vary along fashion trends, prompt introduction of new technologies, and other driving factors that require frequent changes in production. This may include changes in the production process that require new production technologies with corresponding new machines. In the engineering phase, the plant is given the flexibility to react to variations in the process, but very often the process is (partly) re-engineered when new products enter production.
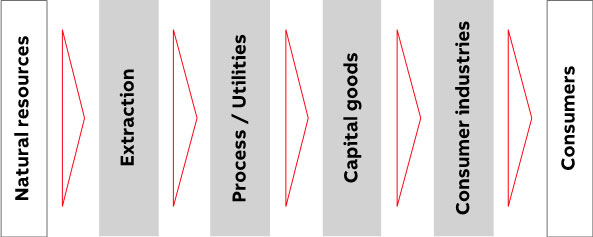
Figure 1: Value chain across industries.
Plant construction value chain
Engineering as we cover it here has many different facets. From the moment a company decides to produce a particular range of products to the point at which they emerge from the factory is a long journey, involving many stakeholders. Many companies do not build the factory themselves; they employ an EPC (engineering procurement construction) company to design the factory and procure the machines that go into it. The machine builder then orders components from another supplier. The equipment that makes up a plant is a hierarchical structure of systems and sub-systems, that all interact to fulfill the purpose of the plant. The engineering steps involved along the plant value chain are quite diverse. System integration engineering at plant level requires different skills and methods from the design of a product, e.g. a motor. Such a motor, once designed, is again produced in a factory, that in turn was built earlier using the very same process. When discussing engineering, the system level and the stage in the plant construction value chain determine the optimal approach.
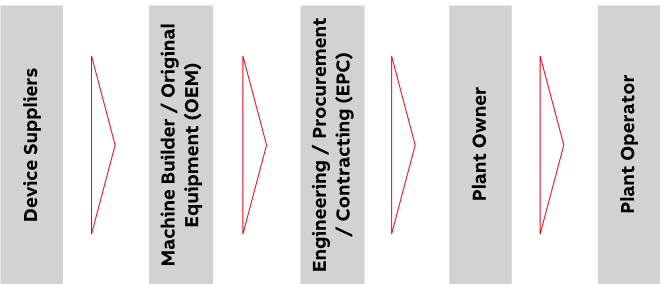
Figure 2: Plant construction value chain.
Plant lifecycle
The value chain described above explains how a plant is planned and built, but once it exists, it must be operated and maintained. Even in operation, the products that are being produced are engineered, sometimes to produce new product families, sometimes to produce according to customer specifications. In the plant value chain, it may be necessary to design some equipment specifically for a particular purpose (in size, performance, or special industry requirements). Changes in the product engineering may then result in a re-engineering of the plant, i.e. in a change of its production sequence or machining instructions.
But even the most reliable components may fail from time to time. Without proper maintenance, they fail even earlier. The maintenance tasks themselves may require some engineering, since a component may no longer be available, or a newer, better component may require an adaptation of the production process as well, i.e. it requires re-engineering.
Technology challenges
The engineering processes discussed above pose a few technological challenges. Industrial applications typically require high capital investment for the equipment, and many processes handle high energy (electrical, thermal, mechanical, etc.). In short: industrial applications are expensive and dangerous. Failures not only reduce the production of the plant through outages, but they can cause injuries and fatalities, or even major environmental damage with long-lasting consequences.
Industrial AI
When looking into machine learning in engineering, we first need to consider a few boundary conditions that are imposed by the nature of industrial applications.
Safety
Industrial applications are very often dangerous. Safety regulations require the equipment to meet reliability requirements in order to be applied in certain industries. Today’s neural networks, however, cannot guarantee a reliable reaction in a given situation. At times even a well-trained system responds incorrectly. In situations where the AI system supports the human, any correct conclusion is adding to the human’s performance. False negatives may still be caught by the human, but if not, the performance is not worse than the human’s. However, false positives reduce the trust in the system and should be avoided. In a safety environment, false negatives are not acceptable. Any situation not properly caught may lead to damage. False positives, however, are accepted: an industrial safety system shuts down in order to absolutely not miss a safety incident. This also relates to engineering. A wrong decision in the engineering process may reduce the reliability of the equipment in the field, without being discovered. Hopefully this would get detected in acceptance tests, but by that stage it is already produced, and the mistake results in delays and quality costs.
Data
Compared to consumer data, industrial data is sparse. There are probably more industrial machines than consumers, but data (measurements or engineering data) of an electrical breaker cannot be compared to data from a motor or a welding robot. The data-hungry ML algorithms that are fed with millions of images or text samples starve on the data available from industry. Compared to real-time plant measurements, engineering data is even more scarce. Some equipment is designed and produced once for one individual customer. Good industrial use cases may produce thousands or even millions of products, but they are only engineered once. ML in engineering therefore is challenging to train using consumer ML methods. Furthermore, engineering data contains all the intellectual property that went into designing a product. Industrial customers are very reluctant to share measurement data from the factory floor and engineering data is shared even less. To train an ML system compiling similar engineering data from a variety of companies is even less desirable.
Simulation & digital twin
A part of the data challenge can be addressed by using simulation to generate the data. Like reinforcement learning algorithms that played Go until they mastered it, a simulator can provide the data to learn how to build a product. But while Go is played along a limited set of rules on a limited board, a design simulator (product or plant level) follows the more complex laws of physics. The complexity of such an approach is much higher than winning a board game.
Given the challenge of getting enough engineering data from real plants, simulation is probably one of the few promising approaches to solve the engineering challenge using ML. However, a good simulator that properly reflects reality is expensive and not easy to build. Furthermore, a simulator that properly reflects the true plant’s behavior, i.e. its behavior mapped to measured values, is hard to achieve: mapping the parameters is difficult, but mapping them repeatedly over time, factoring in wear and ageing, makes this task a continuous challenges. To map those aspects that are difficult to model through physics, adding ML to map the difference between the ‘as built’ behavior and the operation over time is one approach that has been tried successfully. Once a good simulator is available, the choice between a good optimiser and an ML system needs to be considered.
In today’s digitalised industrial environment, simulation is seen as an important component of a digital twin. The digital variant of a product or system, that behaves exactly like the real plant, has its benefits in designing the plant, but when extended with other digital aspects of a component, e.g. real-time measurements, or maintenance records, can serve many more business models along the plant lifecycle. In the context of a digital twin, simulation capabilities may therefore be worth developing beyond the ML-based engineering stage and may make a business case valuable
Autonomous industrial systems
As we discussed engineering, it reflects the approach to design, build and operate equipment, e.g. a plant. Changes in the plant’s purpose, e.g. to build a product variant or optimize production, requires re-engineering of part of the process, and it’s adaptation on the plant floor. An alternate approach could be envisioned: a plant that reacts to a change of its purpose, and autonomously finds a way to produce what it is asked for. Such a plant requires capabilities that go beyond current engineered systems. To pre-engineer all possible variants into the system and program it’s automation system accordingly exceeds the scope of today’s automation system in size as well as complexity.
Such a system would need to have a basic understanding of its own capabilities, and the proper knowledge of how its capabilities could be employed to produce what it is asked for. Engineering of such a system is then an inherent, AI-supported capability of the system itself. Such systems re-define engineering and operation, and provide a flexibility in production that is today unseen.
Conclusions
The complex and diverse nature of the engineering tasks applied in various industries provides many areas where adding machine learning to the processes helps improving the overall processes. Intelligent plants may even require less engineering than what is applied today. Thorough understanding of the engineering tasks and the capabilities of ML are required to provide value to the users and augment human’s capabilities. Whether ML will provide all the value, or whether other approaches in artificial intelligence are required, remains to be seen. The field is still in its early stages, and is expected to see a lot of progress in the near to mid-term future.
Please contact:
Christopher Ganz
Head of Solutions & Standards ABB Future Labs

