









by Henry Muccini (University of L’Aquila) and Karthik Vaidhyanathan (Gran Sasso Science Institute)
Software systems are developed following standard architecting practices but are prone to uncertainties that result in suboptimal behaviour in certain unexpected conditions. We humans learn by making mistakes, by adapting to environments, situations, and conditions. What if our software architectures could automatically learn to handle uncertainties? Just like self-driving cars, self-learnable software architectures have the potential to outperform current software in unanticipated circumstances.
It is currently an exciting time for software sciences, with the rapid advances that are taking place in computing. Software has already impacted the lives of billions of people across the world, and with developments in AI, future software is set to solve more complex challenges. However, the more complex challenges they solve, the more challenging it is to architect and maintain these systems. The heterogeneous composition of modern software systems contributes to this complexity. Moreover, these systems are subjected to various uncertainties at run-time such as application downtime due to high CPU utilisation, server outages, etc. These can have a big impact on the quality of service (QoS) offered by the system, thereby impacting the experience of the end-user.
Modern systems mitigate these issues by using AI techniques at the application level or by using “self-adaptation”, which allows these systems to recover quickly in the event of failures/downtime. However, these issues often give rise to costly maintenance works in the system architecture. This calls for better mechanisms that can foresee any possible performance issues and avoid manual maintenance by intelligently modifying the architecture itself at run-time. To this end, our research goal is to create self-learnable software architectures that can foresee possible issues, autonomously perform the required patchwork and learn from the experience to intelligently improve the architecture over time. This shall be achieved using a combination of deep learning and reinforcement learning techniques based on the run-time QoS data. The approach will enable software architects to avoid costly maintenance cycles, thereby allowing them to create reliable and self-sustaining software systems.
Our approach can be integrated with any running software system. Figure 1 shows a high-level process pipeline from our approach.
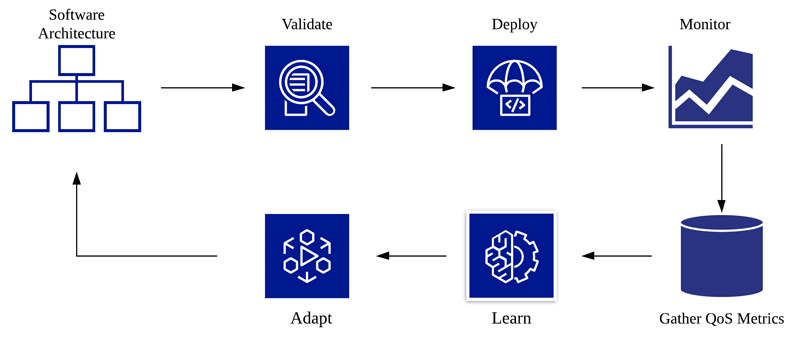
Figure 1: Overall process pipeline of a self-learnable architecture. This process keeps running throughout the software lifecycle to ensure that the architecture is able to continuously learn and improve by itself to handle the different possible uncertainties that might affect the QoS of the system.
Once the architecture has been validated and deployed, at execution time the monitor process keeps a check on the QoS metrics of the system such as utilisation, throughput and response time. This process is accomplished by keeping track of the system execution logs. These real-time data are then stored in a database such as Elasticsearch through a process of gathering QoS metrics with the help of technologies such as Apache Kafka. The gathered data are further processed to extract actionable insights from the learning process. The learning process uses two types of machine learning techniques. It first uses deep neural networks to forecast the expected QoS metrics of the system. Based on this forecast, it uses model-free reinforcement learning techniques like Q-Learning to select the best decision to reconfigure/adapt the architecture. This decision is further communicated to the “adapt” process, which adapts the architecture. The adaptation involves performing actions such as adding/reducing execution memory, replacing faulty components, adding/removing instances in the case of a microservice architecture, reconfiguring various execution parameters, etc. In order to build neural network models to perform forecasts, the learning process keeps training the neural network at regular intervals with the QoS metric data collected. This is done to avoid errors in prediction.
Since no machine learning process is 100% accurate, the adapted architecture undergoes a “validate” process that checks if the modified architecture guarantees the QoS requirements. Furthermore, the deploy process deploys the architecture. After every deployment, the variation in QoS metrics is used to measure the quality of adaptation. This is used as feedback to the machine learning process for further improvement. This process continues throughout the software lifecycle. In this manner, the approach ensures that any possible QoS issues are identified at a much earlier stage and the software architecture is modified so as to prevent any system halts thus ensuring reliability and thereby avoiding any costly maintenance cycles. Moreover, over time, the approach ensures that the architecture automatically learns to better handle uncertainties.
As a first step, we have developed an approach that enables a given IoT architecture to automatically learn and improve its QoS, in particular, energy consumption and data traffic throughout its lifecycle. Further, our experimentation on the simulated version of the IoT system under development for European Researchers Night at L’Aquila, Italy [L1] shows that our approach can improve the energy efficiency of a given IoT system by 20% without affecting the system’s performance [1]. This has also been developed into a tool, Archlearner [L2] [2] using enterprise-grade big data stack. An integrated verification mechanism using probabilistic model checking techniques ensures correctness of the machine learning technique [3].
We are currently extending our approach to traditional microservice-based systems as well as to systems based on serverless computing. This is a step towards our bigger vision of creating self-learnable software architectures. The initial results are promising, giving us confidence that we will be able to make this into working reality.
Links:
[L1] https://nottedeiricercatoriaq.it/
[L2] https://mysat.gitlab.io/archlearner-web/
References:
[1] H. Muccini, K. Vaidhyanathan: “Leveraging Machine Learning Techniques for Architecting Self-Adaptive IoT Systems”, Proc. of the 6th IEEE Int. Conf. on Smart Computing (SMARTCOMP 2020), to appear.
[2] H. Muccini, K. Vaidhyanathan: “ArchLearner: leveraging machine-learning techniques for proactive architectural adaptation”, in Proc. of the 13th European Conf. on Software Architecture (ECSA), 2019.
[3] J. Cámara Moreno, H. Muccini, K. Vaidhyanathan: “Quantitative Verification-Aided Machine Learning: A Mixed-Method Approach for Architecting Self-Adaptive IoT Systems”, in 2020 IEEE International Conference on Software Architecture (ICSA), 2020, pp. 11-22, DOI: 10.1109/ICSA47634.2020.00010.
Please contact:
Henry Muccini
University of L’Aquila, Italy
Karthik Vaidhyanathan
Gran Sasso Science Institute, Italy

