









by Vassilis Pikoulis, Christos Mavrokefalidis (ISI, ATHENA R.C.), Georgios Keramidas (Think Silicon S.A. and Aristotle University of Thessaloniki, Greece), Michael Birbas (University of Patras) and Nikos Tsafas (University of Patras) and Aris S. Lalos (ISI, ATHENA R.C.)
The DEEP-EVIoT project focuses on providing tools to help execute deep multimodal algorithms for scene analysis on embedded heterogeneous platforms (consisting of commercial embedded GPUs as well as dedicated hardware accelerators).
There has been a recent surge in interest in computer vision applications for embedded, portable IoT devices, which satisfy high performance, low computing cost, and small storage requirements. When deep learning (DN) approaches are used, the performance demands and the underlying memory and power requirements of such systems are increased. Furthermore, DN algorithms follow a massively parallel and distributed computation paradigm as they emulate a very large number of neurons operating in parallel.
Deep neural networks (DNNs) have established themselves as prominent tools for solving machine learning (ML) and artificial intelligence (AI) problems (e.g., scene analysis and driver state monitoring), achieving unprecedented results in various applications, and even exceeding the accuracy of human experts in certain classification tasks [1]. However, the quality achieved by DNNs in image/vision applications depends heavily on their size, leading to high computational and storage requirements. This is especially true for DNNs designed to solve demanding image/vision tasks (e.g., 60 million parameters were used in [2])—although these requirements are usually tackled via high-performance computing platforms that include discrete graphical processing units (GPUs). Given the time and computational constraints and the high prediction accuracy required to address potentially life-threatening situations, designing DNNs that can meet the requirements set by the application is not straightforward.
In the DEEP-EVIoT project, we take a twofold approach. First, our target is to design and implement a suite of model compressions and acceleration (MCA) techniques whose goal is to reduce the computational requirements of pre-trained networks, while maintaining their prediction accuracy within acceptable margins. Specifically, we explore techniques based on parameter pruning and sharing, which have been shown to achieve significant MCA with minimal prediction accuracy degradation. Pruning techniques systematically remove unimportant parts of the model (e.g., weights, filters), while sharing techniques reduce the number of operations via subspace clustering and low-rank decomposition, for example, so as to exploit filter redundancies in each DNN layer. Second, we take advantage of the fact that DNNs are very static workloads. Once a DNN has been trained, pruned and quantized, the execution data between the layers remains known and most importantly, is predictable. This characteristic allows hardware and system designers to fine-tune architectures and run-time systems to efficiently execute convolution neural networks (CNNs) (see Figure 1).
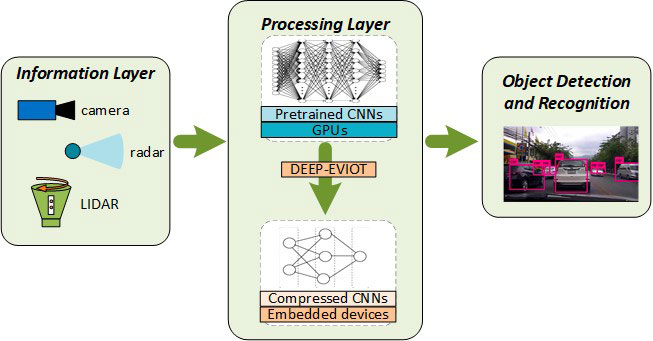
Figure 1: Generation of execution profiles for deep multimodal fusion techniques that trade off performance, energy efficiency, and responsiveness based on hardware availability.
Another goal of the project is to design and implement a heterogeneous platform consisting of multicore and multithreaded embedded, low power GPUs [6] as well as dedicated fixed-logic hardware accelerators with capabilities to efficiently execute CNN algorithms. The prime target is the computations performed by the convolution layers. This is because the convolution layers are more complex than both the classification stages and the layers used to down-sample the visual features (e.g., pooling and RELU layers). However, accelerating CNN algorithms is not an easy task, especially when targeting devices with scarce memory and computational resources (e.g., wearable and IoT devices). As part of the project, the majority of the acceleration capabilities will rely on the embedded GPUs offered by Think Silicon, S.A [L2]. Furthermore, a software SDK for vision applications using optimised deep sparse coding techniques, like those mentioned above, especially designed for the platform, will be provided. The SDK will also help the developers to optimally map the CNN layers in a multicore heterogeneous platform consisting of embedded CPUs, GPUs, and dedicated hardware accelerators.
While processors achieve high speeds in sequential algorithms, they have trouble efficiently managing parallel algorithms. In modern CNNs, convolution layers, which are inherently parallelizable, account for more than 90% of the processing workload. They are, therefore, an ideal candidate for the design of specialised hardware [3]. The proposed design, shown in Figure 2, has been built to benefit from the inherently parallel nature of the convolutional layers. Its purpose is to act as a co-processor (an AXI IP Core) which computes the convolutions while the ARM Processor handles the sequential steps of the algorithm. The system reads from and writes to the main system memory using a DMA architecture. The required data is then stored locally in the programmable logic where an array of systolic kernels computes the convolution in parallel thus drastically accelerating the computation of the CNN convolution layers. Due to the systolic nature of the kernels, computations are performed without the need for large or multiple data buses. Once operations are complete, the DMA is responsible for the write-back of the result in system memory. The systolic kernels are designed to take advantage of the data flow (convolutions are done by “sliding” the window over the data) and the reuse of the data (see Figure 3 for an example of a 3 x 3 kernel). Each of the multiply add elements accumulate the new weight and data product with the sum of the previous element. Once the sums of the filtered rows are computed they are added together and these values can be stored in programmable logic memory for use in subsequent steps, and are ready to be loaded into main system memory via the DMA. The system is controlled by a Mealy state machine to account for pipeline delays, row changes and general algorithmic quirks.
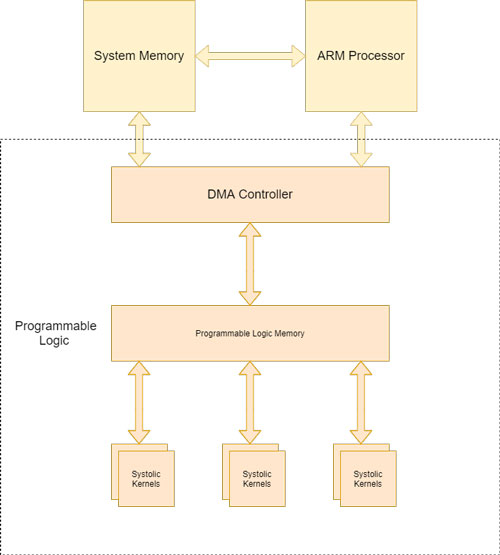
Figure 2: System Level architecture of the proposed solution.
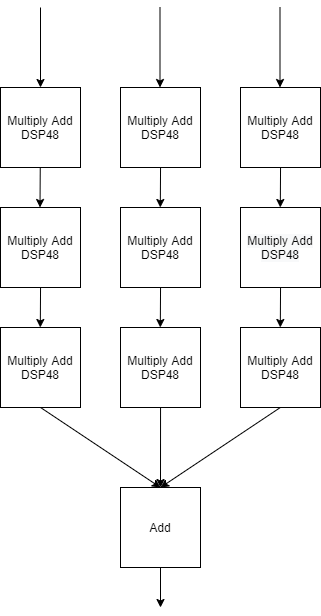
Figure 3: 3x3 Systolic kernel example.
The significant benefits of the proposed system extend to a very wide range of applications, from industrial robotics to autonomous vehicles, smart security cameras and the military.
Links:
[L1] https://www.isi.gr/project/deep-embedded-vision-using-sparse-convolutional-neural-networks
[L2] www.think-silicon.com
References:
[1] V. Sze, et al.: “Efficient Processing of Deep Neural Networks: A Tutorial and Survey”, Proceedings of the IEEE, vol. 105, 12, 2017.
[2] A. Krizhevsky, I. Sutskever, G. E. Hinton: “ImageNet Classification with Deep Convolutional Neural Networks,” in NIPS, 2012.
[3] Y. Umuroglu, et al.: “FINN: A framework for fast, scalable binarized neural network inference”, in Proc. of FPGA, pp. 65–74, 2017.
Please contact:
Aris S. Lalos, ISI, Athena Research Centre, Greece

