








by Balázs Németh and Péter Gáspár (SZTAKI Institute for Computer Science and Control)
Several advanced complex control systems can incorporate learning agents, especially in designing functions in automated vehicles. At the same time, an open problem is to find a systematic design method that is guaranteed to satisfy the performance specifications of the system. This paper presents a possible design method based on robust control theory, which has been developed in the Systems and Control Laboratory of SZTAKI.
Highly complex automated vehicle and transportation technologies are evolving as a means of addressing the problems of traffic congestion, energy consumption and emissions. The increasing complexity of control and decision tasks has resulted in the combined application of various control systems, e.g. model-based robust and optimal control, nonlinear control and machine learning-based solutions. One of the most important fields is related to the control of automated and autonomous vehicles, in which several driving features must be automated to reduce the role of human intervention, e.g. sensing the environment, making decisions, trajectory design, control and intervention with smart actuators [1].
The increasing complexity of the control systems poses the challenge of applying control methods that will guarantee performance specifications. Road stability, manoeuvrability and safety are primary performance requirements in safety-critical systems, which must always be guaranteed by the control during the operation of the system. Other variables, including comfort, energy consumption and emissions reduction are considered “secondary performances”, which must be considered by the control system, but may be violated in critical situations, e.g., if a vehicle collision or pedestrian accident is predicted.
The complexity of the control requires novel analysis, synthesis and validation methods that can guarantee the primary performances and possibly the secondary performances as well. Model-based control design methods have advantages in terms of theoretical guarantees for the performances, but the high complexity of the control-oriented model and the large number of performance specifications in the control design must be limited for numerical reasons in the mathematical computation of the control and the practical implementation possibilities. However, in the case of learning-based techniques the control system may have high complexity, e.g., convolutional neural networks, and there are effective methods for the learning solutions. Although the different types of enhanced learning control methods can solve various control tasks effectively, their achieved performance level is not theoretically guaranteed. The quantity and quality of the learning samples can be selected at any size, but this does not guarantee the avoidance of performance degradation in an emergency scenario or robustness against faults and disturbances. The validation of learning-based automated vehicle control systems poses similar challenges. There exist conventional test scenarios for the validation of the model-based controllers in driver assistance systems, but the evaluation of control systems in automated vehicles may require huge number of scenarios. The problem is to find a theoretically emphasized process for the limitation on the test scenarios, with which the guarantees on performance requirements can be evaluated.
Although learning control can provide partial theoretical results, a general systematic solution does not exist. We aim to provide a design framework based on the robust Linear ParameterVarying (LPV) analysis and synthesis, in addition to learning methods, to guarantee performances [2].
Design framework to achieve guaranteed performances
In the structure of the control system a learning control and a robust LPV control operate together under the monitoring of a supervisor, see Figure 1. The learning control is designed to consider the specifications on primary and secondary performances through its agents. It uses various information sources as measured signals in yL. The robust LPV control guarantees the primary performances, while several secondary performances might not be considered in its design. It uses only onboard signals of the automated vehicle, yK. Its scheduling variable ρL comes from the supervisor, which applies both controllers and monitors both to vehicle motions and the traffic environment. In general, especially under normal travelling conditions, the supervisor uses a control signal which is calculated by machine learning control. However, dangerous situations may occur in which guaranteeing primary performances is essential. In these cases, the supervisor uses the control signal of the robust controller, overriding the current control signal.
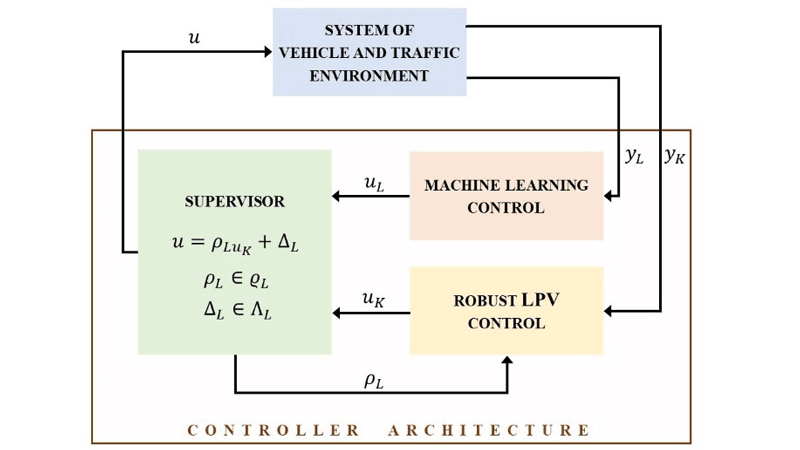
Figure 1: Scheme of the design framework with the control components and the supervisor.
The role of the supervisor is to monitor the signals of the control elements and to make a decision about the intervention. The rule of differentiation between nominal and critical scenarios is represented by an optimization process in the supervisor, which is based on its input signals uL and uK as follows. The control signal u is formed as u=ρLuK+ΔL, where ρL elements of ϱL and ΔL elements of ΛL are ρL, ΔL are scalar values and ϱL, ΛL represent their domains. Since ϱL, ΛL are considered in the design of the robust LPV controller as scheduling variable and known uncertainty, u in the environment of uK guarantees the minimum level of the primary performances. Thus, if uL is inside of the environment of uK, u=uL is selected. But, if uL is outside of the environment of uK, then u≠uL and u is computed through the saturation of uL. Thus, the control signal achieves at least the minimum performance level on the primary performances in both cases and, moreover, the secondary performances can also generally be achieved.
The rationale behind the application of the robust LPV formalism is that this method is well elaborated and is used to address various industrial problems [2]. The advantage of the proposed solution is that it is independent of the internal structure of the learning control methods, i.e., it can be used for deep learning, reinforcement learning and other methods. Another advantage is that the negative impacts of the degradation in the external information sources (e.g. loss of internet communication) on the performances can be avoided, since yK contains only onboard measurements.
Applications within automated vehicle control systems
The proposed method has been applied at various levels of automated vehicle control tasks in simulation environments. On the level of local control, the method is applied to the design of steering control. Deep-learning-based end-to-end learning solutions have high impact on automated driving, which uses visual signals for the actuation of the steering system. In practice, the learning can be performed through reinforcement learning or machine learning through the samples of a vehicle driven by an expert driver. As a result, steering control can provide an acceptable path following functionality and traveling comfort, but unfortunately, the performances are not guaranteed theoretically. The robust LPV control can be designed based on a simplified physical vehicle model, in which the path following can be theoretically guaranteed.
On the level of vehicle functionalities, the proposed framework has been applied to cruise control design. Several performances must be involved in the control design, e.g. travelling time, speed limits, vehicle tracking, energy consumption. The control solution can be achieved with complex nonlinear optimization algorithms, but its implementation has numerical limitations. The motivation of learning control is to reduce online computation through neural networks which are trained through supervised learning methods on the offline solutions of the optimization problem. Since keeping speed limits and distances from the surrounding vehicles are safety performances, they can be guaranteed by the robust LPV control, which is designed based on a simplified vehicle model.
On the level of multi-vehicle interactions, the method has been applied to the solution of overtaking tasks of automated vehicles. The role of the overtaking strategy is to find a trajectory for the automated vehicle with which safe motion can be guaranteed. It requires information about the objects in the vehicle’s environment, from which the classification of the objects and their motion prediction can be performed. The learning process has been performed through various multi-vehicle scenarios, whose results are a route and a speed profile. Despite the large training set, there may be multi-vehicle scenarios which result in inappropriate vehicle motion. Figure 2 illustrates an example in which an automated vehicle overtakes a slower vehicle [3]. The highlighted scenarios are related to the same time. The control strategy with guaranteed performance ensures a safe completion of the overtaking manoeuvre, even if the machine learning control provides unacceptable vehicle motion.

Figure 2: Illustration of the overtaking maneuvre in connection with the guaranteed performance.
References:
[1] P. Gáspár, B. Németh: “Predictive Cruise Control for Road Vehicles Using Road and Traffic Information”, Springer Verlag, 2019.
[2] P. Gáspár, et al.: “Robust Control Design for Active Driver Assistance Systems”, Springer Verlag, 2017.
[3] B. Németh, T. Hegedűs, P. Gáspár: “Performance Guarantees on Machine-Learning-based Overtaking Strategies for Autonomous Vehicles”, European Control Conference, pp. 136-141. 2020.
Please contact:
Balázs Németh, Péter Gáspár
SZTAKI, Hungary