









by Sónia Teixeira, João Gama, Pedro Amorim and Gonçalo Figueira (University of Porto and INESC TEC, Portugal)
Algorithmic systems based on artificial intelligence (AI) increasingly play a role in decision-making processes, both in government and industry. These systems are used in areas such as retail, finances, and manufacturing. In the latter domain, the main priority is that the solutions are interpretable, as this characteristic correlates to the adoption rate of users (e.g., schedulers). However, more recently, these systems have been applied in areas of public interest, such as education, health, public administration, and criminal justice. The adoption of these systems in this domain, in particular the data-driven decision models, has raised questions about the risks associated with this technology, from which ethical problems may emerge. We analyse two important characteristics, interpretability and trustability, of AI-based systems in the industrial and public domains, respectively.
Data-driven models, as well as other algorithmic systems based on artificial intelligence (AI), must be in accordance with legislation and regulations, upholding the law, values and ethical principles. Unfairness is one of the greatest ethical concerns from the emergence of technological risks. In addition, it is necessary to guarantee the right to explanation, instituted with the GDPR (General Data Protection Regulation). In areas of public interest that use algorithmic systems based on AI, namely, data-driven decision models, we intend that these be fair, effective and transparent when it comes to ensuring the right to explanation.
In this thesis project, three dimensions of risk are being considered from a technological perspective (bias, explainability and accuracy), and two from an ethical perspective (fairness and transparency). The AI process consists of several phases, and it is important to determine whether all phases have the same type of risks. If they do not have the same type of risks, it is important to understand where each type of technological risk under analysis is located in the process. This identification was our first stage of work [1], which currently allows us to easily identify which phase requires our attention when we intend to solve a specific type of risk (whether from the perspective of AI, or from the perspective of political decision-makers). Figure 1 shows our framework for a more trustable system, in the public interest domain.
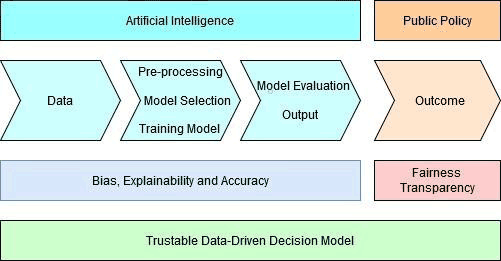
Figure 1: Framework of the risks involved for a trustable system in areas of public interest.
Our approach considers the interconnection between the three dimensions of risk from a technological perspective (bias, explainability and accuracy) together with the ethical risks, all underpinned by our values and law, to obtain more ethical and trustable algorithmic systems. Data-driven decision models can have a bias at several stages of the process, which can contribute to injustices. For this reason, both explainability and the right to explainability are important, in order understand and explain the decisions made by the system. However, sometimes the models are so complex that it is not possible to know whether wrong associations were learned and whether the decision support provided by the system is as good as the accuracy indicates. At the moment we are selecting the most suitable case-study from these hypotheses.
Algorithm/model explainability remains an important unsolved problem in AI. Developing algorithms that are understandable by factory workers, for example, could substantially boost the deployment of such systems. Hence, Explainable AI (XAI) is an emergent research field that may drive the next generation of AI. Most of the existing approaches to tackle XAI start by applying a black-box model (BBM) to the problem at hand. BBMs, such as neural networks and tree ensembles, are well-established machine learning approaches that usually perform well. In a second step an explanator is built to help interpret the results of the BBMs. However, this two-step approach of first learning the BBM and only then building the (global) explanator, has important drawbacks: i) much of the fine-tuning of the first step is lost in the second step, as the explanator does not absorb it all; ii) the explanator will have the biases of the BBM.
Our proposal is to learn directly, in a single, joint phase, a human comprehensible model. This approach will not be possible in every machine learning application, such as those using image or text data (which is predominantly done with deep learning and increasingly already trusted and explainable), but there is wide class of problems that use tabular data, including classification/regression and that leverage this concept. Fundamentally, we propose the use of symbolic learning methods that work with analytical expressions that humans can understand and improve on (c.f. Figure 2).
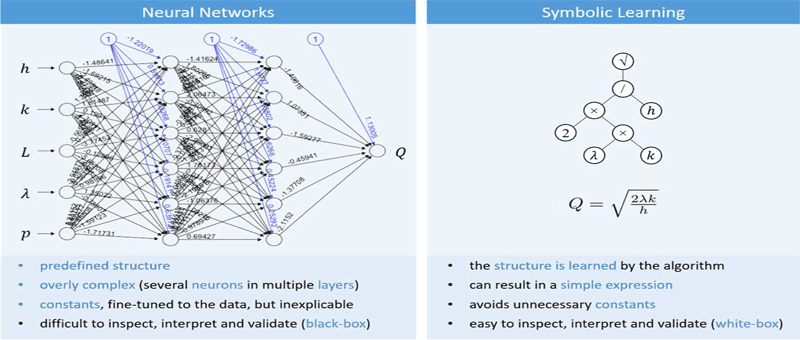
Figure 2: Comparison of a BBM (neural network) and a white-box model (obtained via symbolic learning).
The project regarding trustability in data-driven decision models in the areas of public interest is part of a PhD thesis in Engineering and Public Policy, started in 2019, at the Faculty of Engineering of the University of Porto, with the host laboratory the Laboratory of Artificial Intelligence and Decision Support from INESC TEC, and is supported by Norte Portugal Regional Operational Program (NORTE 2020). The project focussing on interpretability TRUST-AI project, supported by the EU Commission, is starting this year.
Reference:
[1] S. Teixeira, J. Rodrigues, J. Gama: “The Risks of Data-Driven Models as Challenges for Society”, in IEMS ’20 — 11th Industrial Engineering and Management Symposium: The Impact of DEGI Research on Society, Porto, Portugal, 51-53, 2020.
Please contact:
João Gama, INESC TEC, Portugal

