









by Leonardo Gutiérrez-Gómez (LIST), Alexandre Bovet and Jean-Charles Delvenne (UCLouvain)
Anomaly detection is an important problem in data mining with diverse applications in multiple domains. Anomalies, also known as outliers, can be defined as individual objects with patterns or behaviours that differ starkly from a background property. Examples of applications include fraud detection in finance, detection of faults in manufacturing, identifying fake news in social media, or web spam detection. Anomalies in real problems may lead to enormous economic, social, or political costs and are often difficult to find, mainly because they are scarce and unknown a priori. Therefore, efficient detection of anomalies may bring significant value to people, companies, and authorities.
In a general form, anomaly detection relies on the ability to characterise and differentiate what is normal from what is unusual or rare. However, such distinction becomes much more challenging when intrinsic interactions between data are present, forming a network of inter-connected data.
A network is a mathematical model used to describe complex phenomena in terms of entities and their relationships. Networks are represented mathematically as graphs, with vertices representing entities such as people, products, mobile phones, cities, or neurons; and edges connecting nodes describing pairwise relationships such as friendship (social networks), purchasing (co-purchasing networks), calling (communication networks), physical connection (transportation networks), or anatomical links (brain networks) respectively. Networks are often enriched with attributes or external meta-data on the nodes or edges. For instance, in a social network, we may know demographic information about the people, such as gender, age, nationality, or height. Therefore, meta-data, together with the network structure, provide a more comprehensive description of the problem at hand at the expense of additional complexity.
Finding anomalies on networks with attributes on the nodes is known in the literature as anomaly (or outlier) detection on attributed networks. Some examples include fake profiles in social media networks, review manipulation in e-commerce networks, super-spreaders of infectious deceases in social networks, and brain damage in brain networks. Because the mechanisms of anomaly generation in real-world networks are usually unknown, characterising "ground truth" anomalies is problematic, and therefore estimating and evaluating anomalies is a challenging problem. Thus, anomalous nodes must be defined against a background of "normal" nodes, i.e., the context relevant for an anomaly.
Although many techniques to find anomalous nodes in attributed networks have been proposed, a complete solution has not yet been found. Some approaches define anomalies in local contexts, i.e., community outliers, and others localise anomalies as global outliers, i.e., the context is the entire network. Other authors do not consider any context at all.
However, real networks are characterised by a modular and multi-scalar structure of its components. That is, in real networks, nodes are organised in modules or clusters of strongly connected nodes, with few inter-group connections, e.g., social networks are organised according to people's interests. Besides, networks have multiple levels of abstraction (like Google maps), allowing the network exploration at different scales of detail. A node may be anomalous in a local context but disappears on a global scale, see Figure 1. Thus, it is crucial to take into account the node attributes spanning across the multi-scale structure of networks to correctly define the contexts of anomalies.
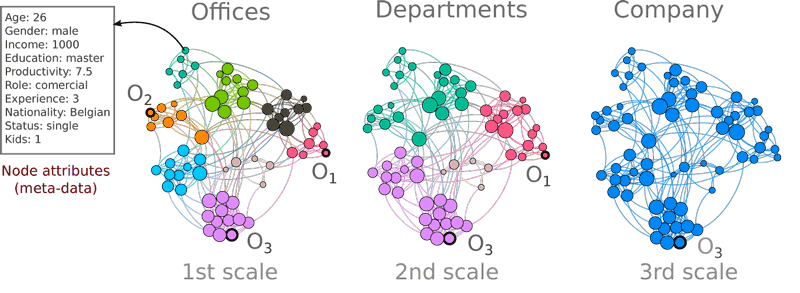
Figure 1: A toy example of a work relation network. Nodes have attributes describing individual features. Node attributes define structural clusters in multiple scales. At the 1st scale, outlier nodes (O1, O2, O3) lie within a local context, i.e., offices. In a 2nd scale, departments emerge as new contexts where O2 is not defined. Finally, at a larger scale, O3 remains as a global anomaly in the context of the whole company.
To this end, in collaboration with researchers of the Université catholique de Louvain, we provide a more general solution to the problem. We propose a principled way to uncover outlier nodes simultaneously with the context in which they are anomalous, at all relevant scales of the network [1].
Our approach is based on graph signal processing tools [2]. Intuitively, anomalous nodes are those whose attributes differ starkly from the attributes of some context nodes. We characterised anomalies in terms of the concentration of “energy” retained for each node after smoothing specially designed signals localised at each node of the graph. This smoothing operation can be interpreted as a heat diffusion process on the network. That is, heat spreads from one node to its neighbours following the network structure. Also, heat spreads faster between nodes with similar attributes than nodes with dissimilar ones. As a consequence, node attributes of anomalous nodes induce bottlenecks for the heat diffusion. At the beginning of the process, each node has maximum heat because nothing has been spread yet. By increasing the time, i.e, the scale, the heat flows from one node to its neighbours with a propagation rate driven by the similarity between the attributes of the adjacent nodes. The flow tends to remain trapped in regions of the graph where nodes are highly similar or strongly connected. In this way, the diffusion flow unveils the modular composition of the network [3], where for small time scales, fine-grained clusters emerge as local contexts for potential anomalies, and larger times uncover coarser clusters as broader contexts for global outliers. Hence, anomalies are scale-dependent, and the time acts as a zooming parameter (as Google maps), to reveal the context in the network where the anomalies make sense.
Our approach has been validated empirically in synthetic and real-life attributed networks (e-commerce and web spam), outperforming many state-of-the-art methods, with the advantage of being highly efficient and parallelisable. Finally, it is worth noting that our approach is applicable on any attributed network independently of its nature or domain. Moreover, we plan to extend this approach in dynamic time-varying networks, where links between nodes change in time or new nodes join the graph dynamically.
Link:
[L1] https://github.com/leoguti85/MADAN
References:
[1] L. Gutiérrez-Gómez et al.: “Multi-scale Anomaly Detection on Attributed Networks”. Proceedings at 34th AAAI Conference on Artificial Intelligence, 2020.
[2] D. Shuman et al.: “The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains”, IEEE Signal Process, 2013.
[3] R. Lambiotte et al.: “Random Walks, Markov Processes, and the Multiscale Modular Organization of Complex Networks”, in IEEE Transactions on Network Science and Eng., 2014.
Please contact:
Leonardo Gutiérrez-Gómez, Luxembourg Institute of Science and Technology (LIST), Luxembourg.

