









by Artur Rocha, José Pedro Ornelas, João Correia Lopes, and Rui Camacho (INESC TEC)
Novel data collection tools, methods and new techniques in biotechnology can facilitate improved health strategies that are customised to each individual. One key challenge to achieve this is to take advantage of the massive volumes of personal anonymous data, relating each profile to health and disease, while accounting for high diversity in individuals, populations and environments. These data must be analysed in unison to achieve statistical power, but presently cohort data repositories are scattered, hard to search and integrate, and data protection and governance rules discourage central pooling.
In order to tackle data integration and harmonization challenges while preserving privacy, we adopted an approach based on an open, scalable data platform for cohorts, researchers and networks. It incorporates the FAIR principles (Findable, Accessible, Interoperable, Reusable) [1] for optimal reuse of existing data, and builds on maturing federated technologies [L1][L3], where sensitive data is kept locally with only aggregate results being shared and integrated [3], in line with key ELSI (Ethical, Legal and Societal Issues) and governance guidelines.
Since the measurement and observation methods used by cohorts to collect exposures and outcomes are often highly heterogeneous, using these data in a combined analysis requires that data descriptions are mapped onto subsets of research-ready core variables, and it must be clear if measurements are similar enough to be integratively analysed. The implemented platform not only facilitates the process of duly curating cohort data, but also helps preserve knowledge about the original methods used in the scope of each data collection event, thus providing valuable insight and a systematic framework to decide if and how data can be made interoperable [2]. Although expert knowledge is key to drive the harmonisation process, to some extent data harmonisation procedures are also supported in the scope of the platform.
Physically, the deployed platform maps down to a network of distributed data nodes, each of them in full control over their local users and study data, while the software allows data managers to curate, describe and publish metadata about selected datasets. New datasets can also be derived according to agreed harmonisation dictionaries.
From a high-level perspective, data nodes can be organised in large-scale, dynamically-configured networks, with the potential to be used in different setups. In a federated setting, the network can take form by simply interconnecting data nodes that collaborate towards a common goal, such as taking part in a network of cohorts or large harmonisation studies. Since each of the nodes includes all the functionality to operate on its own, including a public catalogue, one of the nodes can also undertake the role of gateway to other nodes, allowing more centralised governance policies to be implemented (e.g. a common catalogue entry point).
Each data node is composed of four separate software components acting together, whose purpose is as follows:
- The Data Repository is the central data storage component at each data node. All data operations take place here;
- The Study Manager is where the studies’ metadata is structured, characterised and eventually published;
- A Catalogue provides browsing and querying capabilities over the published metadata;
- An Authentication Server that centralises the authentication process for each data node and provides an interface to manage users, groups and their interrelationships, as well as a role-based access control to the remaining components of the system.
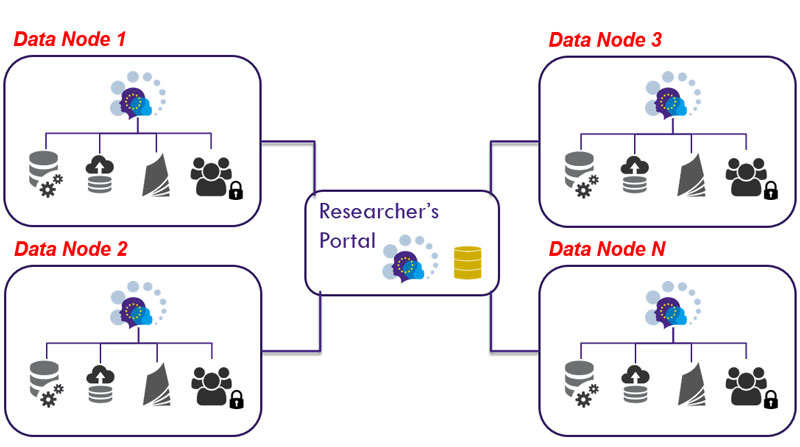
Figure 1: High-level view of the infrastructure used in RECAP Preterm.
One of the projects implementing this approach is “RECAP Preterm – Research on European Children and Adults Born Preterm” [L4], a project having received funding from the European Union’s Horizon 2020 research and innovation programme (grant agreement No 733280) under the “networking and optimising the use of population and patient cohorts at EU level” topic of the “personalised medicine” call. RECAP Preterm includes 20 partners [L5] and is coordinated by TNO (NL, ERCIM member), having INESC TEC as leader of the work package responsible for implementing the data infrastructure. The project’s overall goal is to improve the health, development and quality of life of children and adults born very preterm (VPT) or with a very low birth weight (VLBW). In order to achieve this goal, data from European cohort studies and around the world will be combined, allowing researchers to evaluate changes in outcomes over time while providing important information on how the evolution in care and survival of such high risk babies has changed their developmental outcomes and quality of life. Figure 1 presents a high-level view of RECAP Preterm network of data nodes [L6] that is being used to study developmental outcomes as well as more effective, evidence-based, personalised interventions and prevention.
Also using a similar approach, the recently started EUCAN-Connect [L7] is a project having received funding from the European Union’s Horizon 2020 research and innovation programme (Grant Agreement No 824989) under the topic: “International flagship collaboration with Canada for human data storage, integration and sharing to enable personalised medicine approaches”. EUCAN-Connect, led by UMCG (NL) has 13 partners [L8] and aims to promote collaborative and multidisciplinary research in high-value cohort and molecular data on a large scale in order to improve statistical power with the aims of making new discoveries about the factors that impact human life course and facilitating their translation into personalised diagnostics, treatment and prevention policies.
The outcome of this work will be a FAIR-compliant, federated network of data nodes to make cohort data findable, accessible, interoperable and reusable and enable large-scale pooled analyses with privacy-protecting features [L3] that account for ethical, legal and societal implications.
Links:
[L1] https://www.obiba.org/
[L2] https://kwz.me/hyA
[L3] http://www.datashield.ac.uk/
[L4] https://recap-preterm.eu/
[L5] https://kwz.me/hyD
[L6] https://recap-preterm.inesctec.pt
[L7] https://www.eucanconnect.eu/
[L8] https://kwz.me/hyF
References:
[1] M.D. Wilkinson, et al.: “The FAIR Guiding Principles for scientific data management and stewardship”, Scientific Data 3 (2016).
[2] I. Fortier, et al.: “Maelstrom Research guidelines for rigorous retrospective data harmonization”, International Journal of Epidemiology 46.1 (2017): 103-105.
[3] A. Gaye, et al.: “DataSHIELD: taking the analysis to the data, not the data to the analysis”, International Journal of Epidemiology 43.6 (2014): 1929-1944.
Please contact:
Artur Rocha, INESC TEC, Portugal

