









by Matteo Manica, Ali Oskooei, and Jannis Born (IBM Research)
Accelerating anticancer drug discovery is pivotal in improving therapies and patient prognosis in cancer medicine. Over the years, in-silico screening has greatly helped enhance the efficiency of the drug discovery process. Despite the advances in the field, there remains a need for explainable predictive models that can shed light onto the anticancer drug sensitivity problem. A team of scientists at the Computational Systems Biology group within IBM Research has now proposed a novel AI approach to bridge this gap.
Only 10-14 % of drug candidates entering clinical trials actually reach the market as medicine, with an estimated US $2–3 billion price tag for each new treatment [1]. Despite enormous scientific and technological advances in recent years, serendipity still plays a major role in anticancer drug discovery without a systematic way to accumulate and leverage years of R&D to achieve higher success rates in the process. At the moment, a drug is usually designed by considering which protein target might induce signalling pathway cascades lethal for tumour cells. After this initial design phase, the efficacy of a compound on specific tumour types requires intensive experimental validation on cell lines. The costs of this experimental phase can be prohibitive and any solution that helps to decrease the number of required experimental assays can provide an incredible competitive advantage and reduce time to market.
In this context, IBM Research developed PaccMann [2,3], an in-silico platform for compound screening based on the most recent advances in AI for computational biochemistry. The model developed implements a holistic multimodal approach to drug sensitivity combining three key data modalities: anticancer compound structure in the form of SMILES, molecular profile of cell lines in the form of gene expression data and prior knowledge in the form of biomolecular interactions. PaccMann predicts drug sensitivity (IC50) on drug-cell-pairs while highlighting the most informative genes and compound sub-structures using a novel contextual attention mechanism. Attention mechanisms have gained popularity in recent years, since they enable interpretable predictions by using specific layers that allow the model to focus and assign high attention weights to input features important for the task of interest.
PaccMann has been trained and validated on GDSC [L1], a public dataset of cell lines screened with a collection of compounds. The method outperforms a baseline based on molecular fingerprints and a wide selection of deep learning-based techniques in an extensive cross-validation benchmark. Specifically, PaccMann achieves high prediction performance (R2 = 0.86 and RMSE = 0.89, see Figure 1), outperforming previously reported state-of-the-art results for multimodal drug sensitivity prediction.
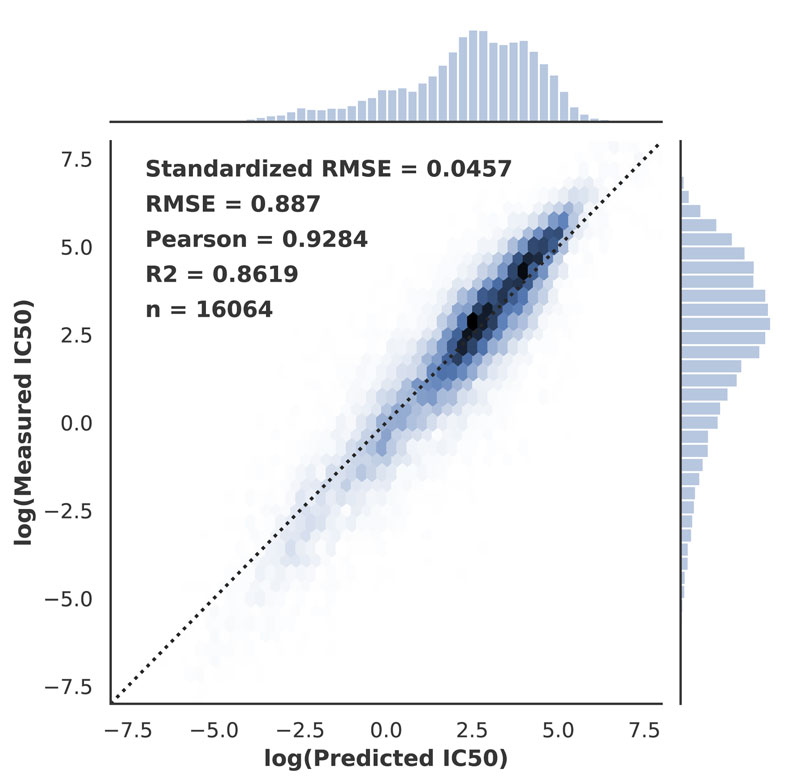
Figure 1: Performance of PaccMann on unseen drug-cell line pairs. Scatter plot of the correlation between true and predicted drug sensitivity by a late-fusion model ensemble on the cross-validation folds. RMSE refers to the plotted range, since the model was fitted in log space.
To showcase the explainability of PaccMann, its predictions on a Chronic Myelogenous Leukaemia (CML) cell line for two extremely similar anticancer compounds (Imatinib and Masitinib) have been analysed. The attention weights of the molecules are drastically different for the compounds’ functional groups whereas the remaining regions are unaffected (see Figure 2, top). The localised discrepancy in attention centred at the different rings suggests that these substructures drive the sensitivity prediction for the two compounds on the CML cell line. On the gene attention level (see Figure 2, bottom) a set of genes has been detected as relevant. Interestingly, the DDR1 protein is a member of Receptor Tyrosine Kinases (RTKs), the same group of cell membrane receptors that both considered drugs inhibit. DDR1 as well as the other highlighted genes have been previously reported in cancer literature, especially in leukaemia. These findings indicate that the genes that were given the highest attention weights are indeed crucial players in the progression and treatment of leukaemia.
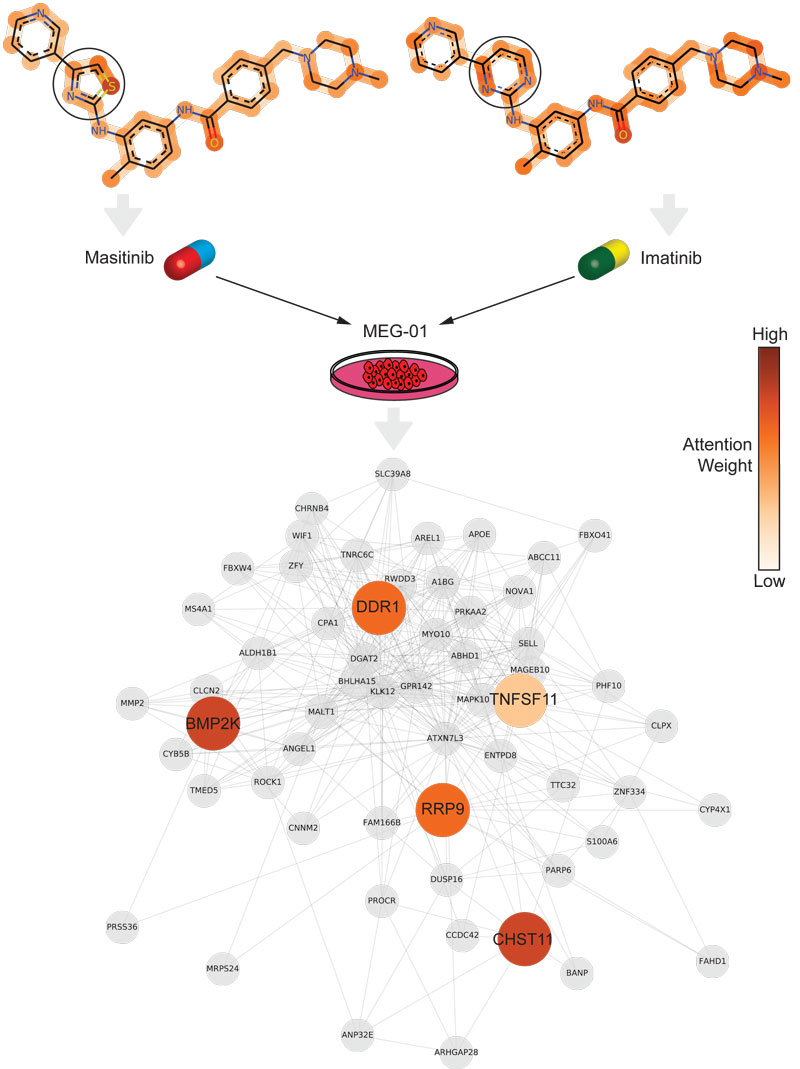
Figure 2: Neural attention on molecules and genes. Top: The molecular attention maps on the top demonstrate how the model’s attention is shifted when the Thiazole group (Masitinib, left) is replaced by a Piperazine group (Imatinib, right). The change in attention across the two molecules is particularly concentrated around the affected rings, signifying that these functional groups play an important role in the mechanism of action for these Tyrosine-Kinase inhibitors when they act on a CML cell line. Bottom: The gene attention plot depicts the most attended genes of the CML cell line, all of which can be linked to leukemia.
To quantify the drug attention on a larger scale, a collection of screened drug-cell line pairs has been considered. For each drug, the pairwise distance matrix of all attention profiles was computed. Correlating the Frobenius distance of these matrices for each pair of drugs with their Tanimoto similarity (established index for evaluating drug similarity based on fingerprints) revealed a Pearson coefficient of 0.64 (p < 1e-50). The fact that the attention similarity of any two drugs is highly correlated with their structural similarity demonstrates the model's ability to learn insights on compounds’ structural properties. As a global analysis of the gene attention mechanism, a set of highly attended genes has been compiled by analysing all the cell lines. Pathway enrichment analysis [L2] on this set identified a significant activation (adjusted p<0.004) of the apoptosis signalling pathway [L3]. IC50 prediction is in essence connected to apoptosis (cell death) and the attention analysis suggests that the model is focused on genes connected to this process, thus confirming the validity of the attention mechanism.
PaccMann paves the way for future directions such as: drug repositioning applications as it enables drug sensitivity prediction for any given drug-cell line pair, or leveraging the model in combination with recent advances in small molecule generation using generative models and reinforcement learning to design novel disease-specific, or even patient-specific compounds. This opens up a scenario where personalised treatments and therapies can become a concrete option for patient care in cancer precision medicine.
An open source release of PaccMann and the related codebase can be accessed on GitHub [L4]. A version of the model has been trained on publicly available data for the prediction of drug sensitivity (IC50) and has been deployed on IBM Cloud [L5]. The model predicts drug response on a set of 970 cell lines generated from multiple cancer types given a compound in SMILES format.
Links:
[L1] https://www.cancerrxgene.org/
[L2] http://amp.pharm.mssm.edu/Enrichr/
[L3] http://pantherdb.org
[L4] https://kwz.me/hyS
[L5] https://ibm.biz/paccmann-aas
References:
[1] G. Schneider: “Mind and Machine in Drug Design”, Nature Machine Intelligence.
[2] A. Oskooei, J. Born, M. Manica et al.: “PaccMann: Prediction of anticancer compound sensitivity with multi-modal attention-based neural networks”, WMLMM, NeurIPS.
[3] M. Manica, A. Oskooei, J. Born et al.: “Towards Explainable Anticancer Compound Sensitivity Prediction via Multimodal Attention-based Convolutional Encoders”, WCB, ICML.
Please contact:
Matteo Manica
IBM Research, Switzerland

