









by Sebastian Schrittwieser (University of Vienna)
Software protection has evolved over the past three decades, but ensuring the correctness of protective code transformations remains a challenge. Our novel approach breaks down complex obfuscation techniques into smaller, manageable components and implements them as compiler passes. By using translation validation, the correctness of each transformation is ensured, resulting in more reliable and robust software protections.
Over three decades of software protection research and development have brought various protection techniques against code analysis, modification, and theft of binary code. However, a significant challenge is verifying the correctness of protective code transformations. While a lot of basic research has been done in the past in compiler correctness to ensure that functionality in binary programs matches the functionality described in the source code, there is no methodological basis for ensuring the correctness of code transformations for software protection.
Usually, software protections, such a code obfuscation, are applied at source code stage. However, in 2015 it was first shown that applying software protections directly in the compiler is feasible. Using compile-time obfuscation, we are able move the question of correctness of code transformations into a research area where we can build on a substantial body of prior work and methodologies. With Alive [L1] Lopes et al. introduced a refinement checker for the LLVM compiler infrastructure in 2015. The basic idea of so-called translation validation [1] is to compare an unoptimised code block with an optimised version and either prove that the optimised version is a refinement of the unoptimised one, or that the refinement fails in at least one particular case using concrete input values as a counterexample. In the past, Alive was successfully used to identify several bugs in optimisation passes of LLVM, and developers of optimisations are encouraged to validate them before committing them to the LLVM code base.
In our research at the Christian Doppler Laboratory for Assurance and Transparency in Software Protection [L2], we build upon this solid foundation for translation validation to verify the correctness of obfuscating passes in LLVM. One major research challenge is reducing the complexity of transformations. While, in theory, Alive covers a large number of language constructs of the LLVM intermediate representation (IR), there are certain language constructs that are known to prevent the underlying SMT solver from solving the query in a reasonable time frame. These include floating points, wide integer divisions, and some complex memory operations. Thus, atomic implementations of typical real-world obfuscation techniques such as virtualisation or control flow flattening would generate code transformations that are too complex for translation validation. For this reason, we deconstruct complex software protection methods into their fundamental protection principles, which can be implemented as separate compiler passes for which translation validation is feasible. Nagra and Collberg [2] have defined eleven software protection primitives that formalise basic protection principles. These primitives range from covering an object worth protecting with another one (cover primitive) to duplicating an object to artificially increase the set of objects to be analysed (duplicate primitive) to detecting and responding to code tampering (detect-responds primitive). Starting from these eleven primitives, we create a set of basic obfuscation passes for LLVM and use a refinement checker for translation validation. Each pass can be parameterised to concretise its functionality. For example, for the detect-responds primitive different methods for the detection of code tampering can be selected such as calculating hash values of code sections.
These compiler passes can now be combined in any way to construct strong software protections. Figure 1 shows the basic concept using the example of the control flow flattening obfuscation technique. In this technique, the control flow graph of a program is modified so that all basic blocks are at the same hierarchical level. After executing a basic block, the control flow is directed to a central dispatcher, which determines the next basic block based on the current state of the program and jumps to it. Rather than implementing this technique atomically, we assemble it from a combination of small compiler passes whose functionality is further specified by parameterisation. The indirect primitive is used to construct the dispatcher. The reorder primitive changes the order of the basic blocks so that no conclusions can be drawn about the functionality of the compiled binary based on local proximity of basic blocks in the code. Finally, the split/merge and duplicate primitives can be used to further split larger basic blocks and duplicate blocks to increase the total number of blocks and thus make reverse-engineering more time consuming.
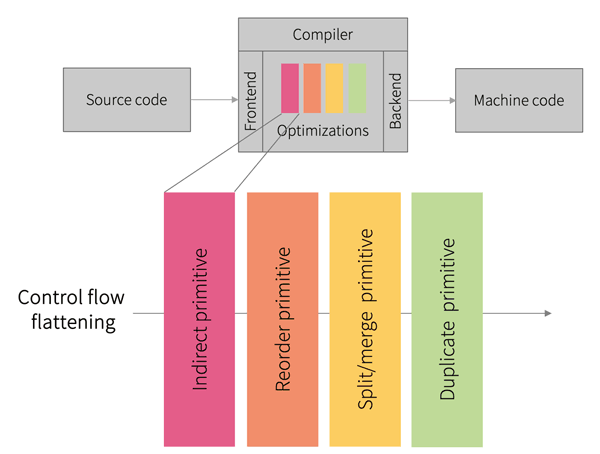
Figure 1: Control flow flattening obfuscation constructed from multiple compiler passes.
Currently, most of our transformations are deterministic, with the notable exception of the reordering primitive, which allows the target structures to be randomly shuffled. Usually, determinism is a desirable goal for compilers. However, for binary software protections that do not perform inherently irreversible code transformations, it may be useful to promote code diversity through randomness. The verification of code correctness is not affected by the use of randomness, since translation validation always validates concrete instances of code transformations using refinement checkers instead of validating the implementation of the transformation pass. In our future work, we thus intend to investigate which forms of code diversity can be implemented and what effect they have on the strength of the resulting software protection.
Links:
[L1] https://alive2.llvm.org
[L2] https://cdl-astra.a t
References:
[1] A. Pnueli, M. Siegel, and E. Singerman, “Translation validation,” in Tools and Algorithms for the Construction and Analysis of Systems: 4th International Conference, TACAS'98, held as part of the ETAPS'98 Lisbon, 1998, Proc. 4, pp. 151–166, Springer.
[2] J. Nagra and C. Collberg, “Surreptitious software: obfuscation, watermarking, and tamperproofing for software protection,” Pearson Education, 2009.
Please contact:
Sebastian Schrittwieser, Christian Doppler Laboratory for Assurance and Transparency in Software Protection, Faculty of Computer Science, University of Vienna, Austria

