









by Mila Dalla Preda, Niccolò Marastoni, Federica Paci (University of Verona)
Ensuring software security starts with detecting vulnerabilities in the early stages of development: while traditional rule-based and machine-learning methods require expert input, Large Language Models (LLMs) are emerging as powerful, autonomous alternatives that could transform the approach to vulnerability detection.
The detection of vulnerabilities in source code during the early stages of development is crucial for ensuring robust software systems that can resist cybersecurity threats. This is especially true as the number of reported vulnerabilities is dramatically rising every year (see Figure 1). In recent years, several approaches have been proposed to identify security vulnerabilities, but each has its own limitations. Rule-based methods require expert intervention to define rules or patterns indicative of known vulnerabilities. Moreover, the rules must be adjusted to detect new or unknown vulnerabilities. Recently, deep learning-based approaches have emerged as a promising alternative, capable of automatically learning vulnerability patterns without direct expert involvement [1].
Large Language Models (LLMs) have demonstrated significant potential in interpreting and generating code, suggesting the possibility of using them to detect vulnerabilities in code [2]. In this paper, we present the project VULCAN, which aims to investigate whether LLMs, despite not being specifically trained to detect vulnerabilities in code, can effectively identify vulnerabilities in source code.
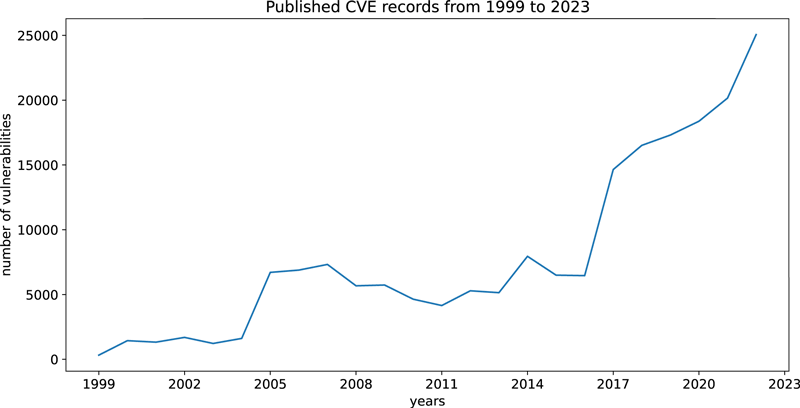
Figure 1: Published CVE records from 1999 to 2023. Source: https://www.cve.org/About/Metrics
While most LLM-based vulnerability-detection approaches rely on fine-tuning, VULCAN leverages LLMs’ in-context learning capability, allowing them to tackle new tasks without specific training. To harness this capability, it is essential to adopt prompt engineering strategies that design effective natural language instructions to guide the models in detecting vulnerabilities in source code.
There are different prompting strategies: zero-shot, few-shot, and chain-of-thought. With zero-shot prompting, the model only receives the description of the new task to be performed. Few-shot prompting includes examples of how the task should be executed. Chain-of-thought prompting gives the model a sequence of steps to execute the task.
VULCAN’s main goal is to develop a framework (see Figure 2) to create effective prompts for different prompt-engineering strategies and to evaluate and compare their impact on the accuracy of LLMs in detecting vulnerabilities. However, designing effective prompts for each strategy and evaluating the accuracy of LLM in detecting vulnerabilities requires addressing several challenges.
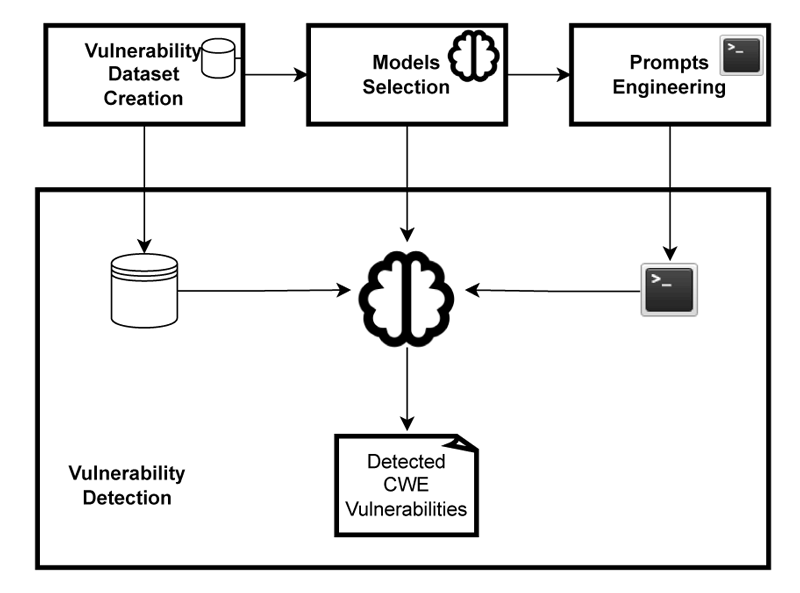
Figure 2: VULCAN framework components.
The first challenge is the limit on the number of input tokens for LLMs, which means that programs with many lines of code cannot be directly included in the prompts. It is therefore necessary to design a concise representation of the code that preserves the semantic relationship between the program’s instructions, which is crucial for detecting vulnerabilities.
The second challenge is related to designing prompts for few-shot prompting, which requires adopting strategies to select examples that are relevant for identifying vulnerabilities. Inspired by the recent success of using retrieval modules to augment large-scale neural network models, VULCAN will adopt Retrieval-Augmented Generation (RAG) to select semantically similar examples to a test program to be included in the few-shot prompt. VULCAN will employ different code similarity measures to select the nearest neighbours of a given test program from a dataset of vulnerable programs.
Then, to verify the effectiveness of this method, we will investigate the impact of different code similarity measures, the order of examples, and the number of examples included in the prompt on the accuracy of LLMs in detecting vulnerabilities. On the other hand, the chain-of-thought strategy requires generating prompt models with specific steps to identify vulnerabilities, which differ for each vulnerability type. Therefore, we will explore how the steps for identifying a specific vulnerability type can be automatically generated.
Finally, a main challenge is related to the datasets of vulnerable code to use to assess LLMs’ accuracy in detecting source code vulnerabilities. Indeed, existing vulnerability datasets suffer from many issues that impact their usability to assess the accuracy of LLMs in detecting vulnerabilities, including: 1. an unbalanced number of vulnerable and non-vulnerable programs, 2. inaccurate vulnerability labelling, and 3. data duplication [3]. SVEN [L1] is a notable exception; security experts manually labelled the vulnerabilities present in the code samples, but the number of samples is relatively small, which makes it inadequate to properly assess the accuracy of LLMs in vulnerability detection. Therefore, VULCAN will create a new, larger, balanced dataset of vulnerable programs with an accurate vulnerability labelling process.
The VULCAN’s framework aims to address the above challenges to allow security analysts and software developers to harness the in-context learning capability of LLMs in detecting software vulnerabilities. As part of the framework, various experiments will be conducted to compare the effectiveness of the prompting strategies with general-use and code LLMs on the created dataset containing vulnerable programs. The VULCAN project will also develop a tool that leverages the LLM and prompting strategy that proves to be the most effective based on experimental results and will integrate it as a plug-in into the Eclipse development environment.
Links:
[L1] https://github.com/eth-sri/sven
References:
[1] Z. Li, et al., “Vuldeepecker: a deep learning-based system for vulnerability detection,” in: 25th Annual Network and Distributed System Security Symposium (NDSS), 2018.
[2] Y. Guo, et al., “Outside the comfort zone: analysing LLM capabilities in software vulnerability detection,” in Proc. of ESORICS, 2024.
[3] Y. Ding, et al., “Vulnerability detection with code language models: how far are we?,” arXiv preprint arXiv:2403.18624, 2024. https://arxiv.org/abs/2403.18624
Please contact:
Mila Dalla Preda, University of Verona, Italy
Federica Paci, University of Verona, Italy

