









by Zoltán Ságodi (University of Szeged), Péter Hegedűs (University of Szeged), and Rudolf Ferenc (University of Szeged)
As AI-driven language models increasingly demonstrate their ability to generate and repair source code, the role of human developers faces a profound transformation. This paper explores both the potential and challenges of leveraging these models for programming tasks and vulnerability mitigation, highlighting where human expertise remains essential.
In recent years, Large Language Models (LLMs) such as GPT-4, ChatGPT, and GitHub Copilot have made remarkable strides in various fields, including software development. From generating new code to fixing existing security problems, these models offer promising tools for developers. However, their capabilities are still far from perfect, especially when it comes to real-world applications. We empirically investigated the real-world capabilities of state-of-the-art LLMs in two very common developer tasks: code synthesis and automated vulnerability repair.
We defined and applied a comparison methodology (depicted in Figure 1) to evaluate how state-of-the-art LLMs perform on code synthesis tasks [1]. Code synthesis is the task where, given a natural language specification, a program code is created that implements the defined functionality. Our comparison included ChatGPT and GitHub Copilot, which we evaluated on the Program Synthesis Benchmark [L1]. The functional evaluations showed that out of 25 programming tasks (i.e. algorithmic solutions to a specified problem), ChatGPT could solve 19, while Copilot could solve 13 tasks with a 100% test pass rate on a test suite including 10,000 tests (meaning that a program was considered correct if it passed all the 10,000 tests). Counting the tasks where the generated code achieved at least a 75% test pass rate on the 10,000 cases, we observed that ChatGPT could solve 20, while Copilot could solve 15 programming tasks.
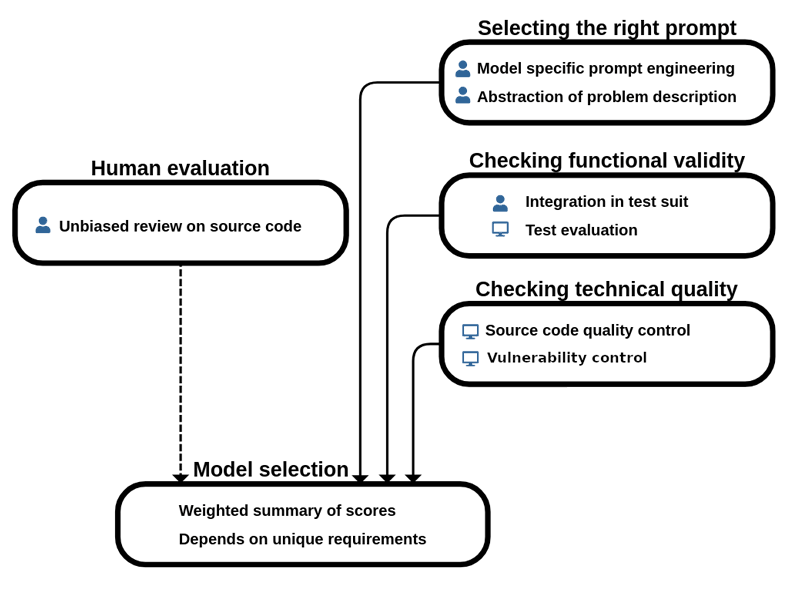
Figure 1: A systematic LLM result comparison methodology.
During the human technical evaluation step, which in simpler terms meant to answer questions like “How good and secure is the code?” or “How many problems are present in the generated code?", the evaluations showed that these models tend to make some minor mistakes, but crucial problems, including potential vulnerabilities, are quite rare. These results are encouraging and might lead to the obvious question: if these models perform so well in synthesising good quality and secure code from human specifications, would they be capable of correcting human-written code as well?
We analysed this question by focusing on how well GPT-4 can fix existing problems in software systems, vulnerabilities (i.e. potential security issues) in particular. Unlike code synthesis, which focuses on generating new code from scratch, this study [2] investigates whether GPT-4 can repair flaws in existing code – an increasingly crucial task in the world of cybersecurity.
Using a dataset of 46 real-world Java vulnerabilities from the Vul4J repository [L2], we tasked GPT-4 with generating mitigation patches for these vulnerabilities. We performed a prompt engineering step to get the most out of the model. We also included the human factor in multiple layers. Firstly, we made evaluations by hand, so there were human ratings of the model’s performance. Secondly, we used a benchmark that contained real-life human errors and their patches. The functional tests were also included, as the benchmark contained unit tests for every vulnerability.
We tested the vulnerability-fixing capabilities of the model, and we also tested if the model could be used as a code review assistant. We evaluated how well the model can fix vulnerabilities by providing our predefined prompt with the vulnerable code, and we requested the generation of its fixed version. At this point, we applied the changes and ran the tests. The results (see Figure 2) show that, on average, the model can fix 33.33% of the real vulnerabilities.
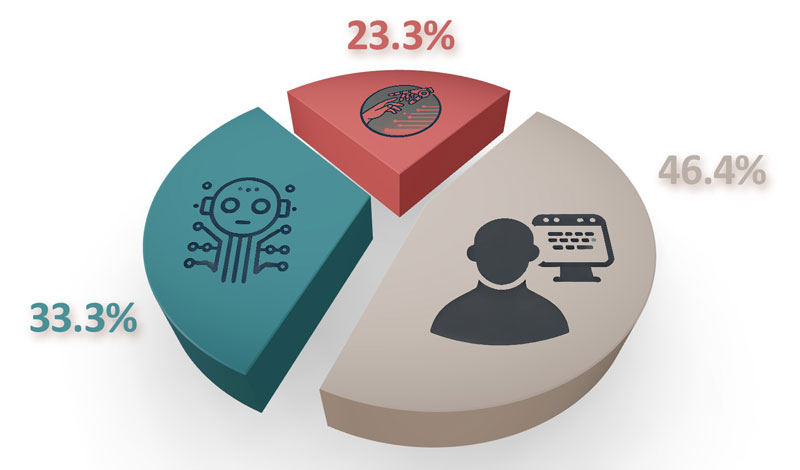
Figure 2: Distribution of vulnerabilities (i) fully fixed (green); (ii) useful fixing guidelines generated (red); (iii) cannot be fixed (grey) by GPT-4.
We also investigated the use case where we do not ask for a full fix, but only a suggestion. In this case, we asked the model to provide us with textual hints on how to fix a problem besides generating a mitigation patch. We evaluated these suggestions with multiple developers and found that, on average, in 56.6% of the cases, GPT-4 could give developers useful hints on how to fix the source code.
While these two studies focus on different aspects of secure software development – code generation and vulnerability repair – they share a common theme: the importance of human oversight. Both studies make it clear that LLMs like ChatGPT, Copilot, and GPT-4 are not yet capable of replacing human developers. Instead, they serve as powerful assistants that can help automate repetitive tasks, which eventually can lead to higher quality and more secure source code.
Looking at the broader picture, LLMs are making impressive strides in automating software development tasks, but there is still a long way to go. While ChatGPT and Copilot show promise in generating new code, and GPT-4 demonstrates potential in repairing vulnerabilities, neither is ready for full autonomy in real-world software development.
One key area for future research and development is improving the functional and technical validity as well as security of LLM-generated code. As the studies suggest, more sophisticated evaluation frameworks are needed to ensure that the code generated by these models meets both functional requirements and technical best practice. This will likely involve integrating automated tools for static analysis, as well as enhancing the models’ understanding of complex software engineering tasks.
Another important direction for future work is better integrating LLM-generated code into existing development and security operations (DevSecOps) workflows. Right now, the code produced by these models often requires significant refinement before it can be deployed. Finding ways to streamline this process – either by improving the models’ output or by developing tools that assist with post-processing – will be critical to making LLMs more useful in real-world development environments.
This research received support from the European Union project RRF-2.3.1-21-2022-00004 within the framework of the Artificial Intelligence National Laboratory.
Links:
[L1] https://www.cs.hamilton.edu/~thelmuth/PSB2/PSB2.html
[L2] https://github.com/tuhh-softsec/vul4j
References:
[1] Z. Ságodi, I. Siket, R. Ferenc, “Methodology for code synthesis evaluation of LLMs presented by a case study of ChatGPT and copilot,” IEEE Access, vol. 12, pp. 72303–72316, 2024. doi: 10.1109/ACCESS.2024.3403858
[2] Z. Ságodi, et al., “Reality check: assessing GPT-4 in fixing real-world software vulnerabilities,” in Proc. of the 28th Int. Conf. on Evaluation and Assessment in Software Engineering, pp. 252–261, 2024.
Please contact:
Péter Hegedűs, University of Szeged, Hungary

