









by Giovanni Ciaramella (IMT School for Advanced Studies Lucca and CNR-IIT), Fabio Martinelli (CNR-IIT), and Francesco Mercaldo (University of Molise and CNR-IIT)
The academic and industrial research community is exploring various machine learning methods to detect malware, particularly ransomware. However, real-world adoption is hindered by privacy concerns, as malware detection typically requires sending applications to a centralised model. To address this, we propose a privacy-preserving ransomware detection method using federated learning, which trains models locally on edge devices without transferring data. Preliminary experiments on a dataset of 15,000 real-world applications confirm the method’s effectiveness.
Over the years, the number of cyber-attacks has increased drastically. As shown in a report published by Statista, approximately 65% of financial organisations worldwide reported experiencing a ransomware attack in 2024, an increase from 64% in 2023 and 34% in 2021 [L1]. For many years, experts and researchers identified various solutions to protect users from attacks. Another issue in recent years is keeping personal data safe. To address that, the European Union introduced the General Data Protection Regulation (GDPR) in 2016 to regulate personal data usage. Nowadays, each technological device needs to handle personal data for several reasons. In 2017, to address the privacy issue, Google introduced the concept of federated machine learning [1]. This consists of training a model using local data, keeping raw data decentralised, and only sharing the model updated to the server.
In this article, we propose a method based on federated learning to classify malware, ransomware, and trusted applications belonging to the Windows environment. We assessed the effectiveness of the proposed approach by exploiting over 15,000 samples divided into ransomware (5,000), generic malware (5,000), and trusted samples (5,000). The generic malware and ransomware samples were sourced from the VirusShare repository [L2] while trusted samples were collected from libraries (such as DLL files) and executable files from a Microsoft Windows 10 machine. To verify the maliciousness or trustworthiness of the samples, we submitted them to the VirusTotal [L3] and Jotti [L4] web services. As the next step, all executable files were transformed into text files containing the opcodes obtained using the objdump disassembler. To create an image representation, we assigned an RGB value to each opcode within the file and used these values to fill each matrix’s pixel. Specifically, we assigned a distinct colour to each opcode for all the applications involved in the experimental analysis. After creating the complete dataset of images, we divided it into training, validation, and testing sets using an 80-10-10 split (12,000-1,500-1,500).
We started the experiment leveraging federated learning adopting the clipping norm aggregator, which limits the influence of individual data points by capping their gradients’ norms before averaging them during model training, helping to reduce the impact of outliers. Moreover, in federated learning it is necessary to use a distribution because of the number of clients involved, and to recreate a real-world scenario we used non-IID data, i.e. Dirichlet distribution as shown in Figure 1. This type of distribution turns out to be different from the IID data [2] because it uses different statistical properties for each client, thus recreating a real-life scenario. After deciding on the norm type and distribution type to use, we began conducting experiments, employing a state-of-the-art architecture, i.e. MobileNetV3 [3]. To train our model, we used the “sgdm” optimiser, 15 clients, 20 rounds, and 15 epochs per round on each client. At the end of the experiments, we obtained a model with an accuracy value of 0.824 and a loss of 0.438 during the test phase.
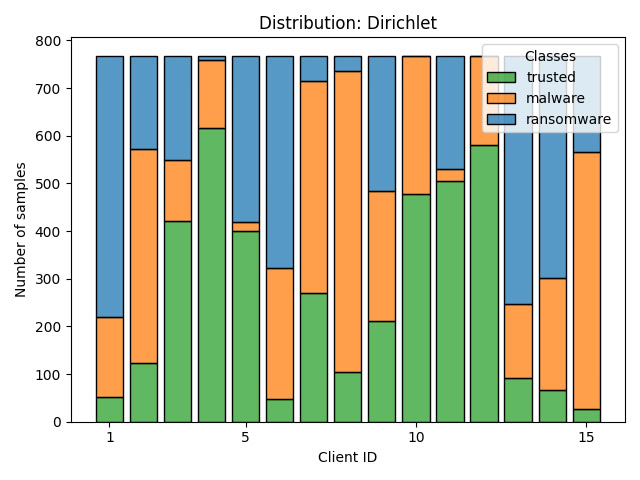
Figure 1: The Dirichlet distribution obtained among 15 different clients.
To evaluate the model’s performance we computed the confusion matrix shown in Figure 2. The model was able to correctly identify 392 samples as “Trusted”, though it misclassified 108 instances, mistakenly labelling 9 as “Malware” and 99 as “Ransomware”. In the category named “Malware” the model achieved 435 correct predictions, with minor errors resulting in 13 instances being labelled as “Trusted” and 52 as “Ransomware”. The “Ransomware” category also performed strongly, with 390 accurate classifications. However, 110 samples were incorrectly categorised, with 60 samples classified as “Trusted” and 50 as “Malware”.
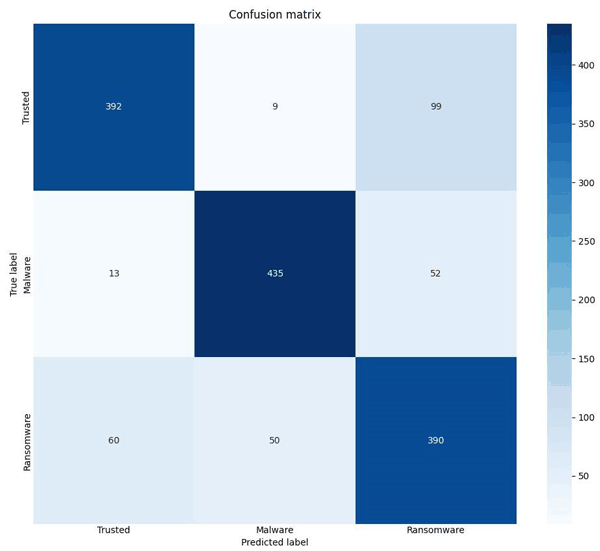
Figure 2: The Confusion matrix.
In conclusion, the federated learning application in the malware detection field can be crucial in enhancing detection capabilities by guaranteeing the respect of user privacy. We demonstrated that a model trained and tested by exploiting federated learning can identify malware, ransomware, and trusted Windows applications with interesting performance accuracy. As future work, we plan to consider model explainability with the aim to pinpoint which area of images related to applications are most distinctive for a given prediction.
This work has been partially supported by EU DUCA, EU CyberSecPro, SYNAPSE, PTR 22-24 P2.01 (Cybersecurity) and SERICS (PE00000014) under the MUR National Recovery and Resilience Plan funded by the EU - NextGenerationEU projects.
Links:
[L1] https://www.statista.com/statistics/1460896/rate-ransomware-attacks-global/
[L2] https://virusshare.com/
[L3] https://www.virustotal.com/
[L4] https://virusscan.jotti.org/
References:
[1] B. McMahan et al., “Communication-efficient learning of deep networks from decentralized data,” in Proc. of Artificial intelligence and statistics, pp. 1273–1282, PMLR, 2017.
[2] G. Ciaramella et al., “An approach for privacy-preserving mobile malware detection through federated machine learning,” in Proc. of 26th International Conference on Enterprise Information Systems, pp. 553–563, 2024.
[3] A. Howard et al., “Searching for mobilenetv3,” in Proc. of the IEEE/CVF International Conference on Computer Vision, pp. 1314–1324, 2019.
Please contact:
Giovanni Ciaramella, IMT School for Advanced Studies Lucca, Italy and CNR-IIT, Pisa, Italy

