








by Kubilay Atasu, Vasileios Vasileiadis, Michail Vlachos (IBM Research – Zurich)
A significant portion of today’s data exists in a textual format: web pages, news articles, financial reports, documents, spreadsheets, etc. Searching across this collected text knowledge requires two essential components: a) A measure to quantify what is considered ‘similar’, to discover documents relevant to the users’ queries, b) A method for executing in real-time the similarity measure across millions of documents.
Researchers in the Information Retrieval (IR) community have proposed various document similarity metrics, either at the word level (cosine similarity, Jaccard similarity) or at the character level (e.g., Levenshtein distance). A major shortcoming of traditional IR approaches is that they identify documents with similar words, so they fail in cases when similar content is expressed in a different wording. Strategies to mitigate these shortcoming capitalize on synonyms or concept ontologies, but maintaining those structures is a non-trivial task.
Artificial Intelligence and Deep Learning have heralded a new era in document similarity by capitalizing on vast amounts of data to resolve issues related to text synonymy and polysemy. A popular approach, called ‘word embeddings’, is given in [1], which maps words to a new space in which semantically similar words reside in proximity to each other. To learn the embedding (i.e., location) of the words in the new space, those techniques train a neural network using massive amounts of publicly available data, such as Wikipedia. Word embeddings have resolved many of the problems of synonymy.
In the new embedding space, each word is represented as a high-dimensional vector. To discover documents similar to a user’s multi-word query, one can use a measure called the ‘Word-Mover’s Distance’, or WMD [2], which essentially tries to find the minimum cost to transform one text to another in the embedding space. An example of this is shown in Figure 1, which can effectively map the sentence “The Queen to tour Canada” to the sentence “Royal visit to Halifax”, even though (after “stopword” removal) they have no words in common. WMD has been shown to work very effectively in practice, outperforming both in precision and in recall many traditional IR similarity measures. However, WMD is costly to compute because it solves a minimum cost flow problem, which requires cubic time in the average number of words in a document. The authors in [2] have proposed a lower-bound to the WMD called Relaxed WDM, or RWMD, which in practice, retrieves documents very similar to WMD, but at a much lower cost. However, RWMD still exhibits quadratic execution time complexity and can prove costly when searching across millions of documents.
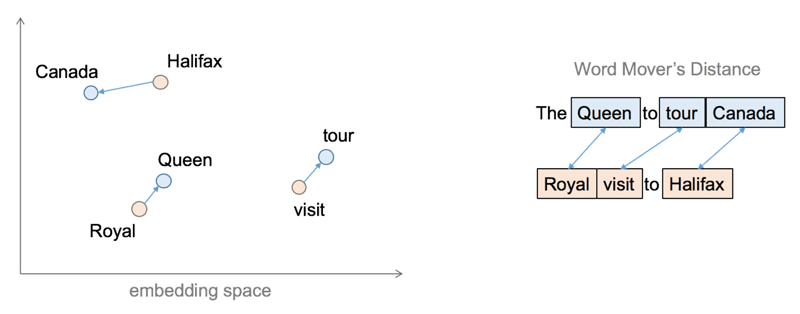
Figure 1: (Left) Mapping of word to a high-dimensional space using word embeddings. (Right) An illustration of the Word Mover’s Distance.
For searches involving millions of documents, the RWMD execution is inefficient because it may require repetitive computation of the distance across the same pairs of words. Pre-computing the distances across all words in the vocabulary is a possibility, but it is wasteful regarding storage space. To mitigate these shortcomings, we have proposed a linear-complexity RWMD that avoids wasteful and repetitive computations. Given a database of documents, where the documents are stored in a bag-of-words representation, the linear-complexity RWMD computes the distance between a query document and all the database documents in two phases:
- In the first phase, for each word in the vocabulary, the Euclidean distance to the closest word in the query document is computed based on the vector representations of the words. This phase involves a dense matrix-matrix multiplication followed by a column- or row-wise reduction to find the minimum distances. The result is a dense vector Z.
- In the second phase, the collection of database documents is treated as a sparse matrix, which is then multiplied with the dense vector Z. This phase produces the RWMD distances between the query document and all the database documents.
Both phases map very well onto the linear algebra primitives supported by modern GPU (Graphics Processing Unit) devices. In addition, the overall computation can be scaled out by distributing the query documents or the reference documents across several GPUs for parallel execution. Figure 2 depicts the overall approach, which enables the linear-complexity RWMD to achieve high speeds.
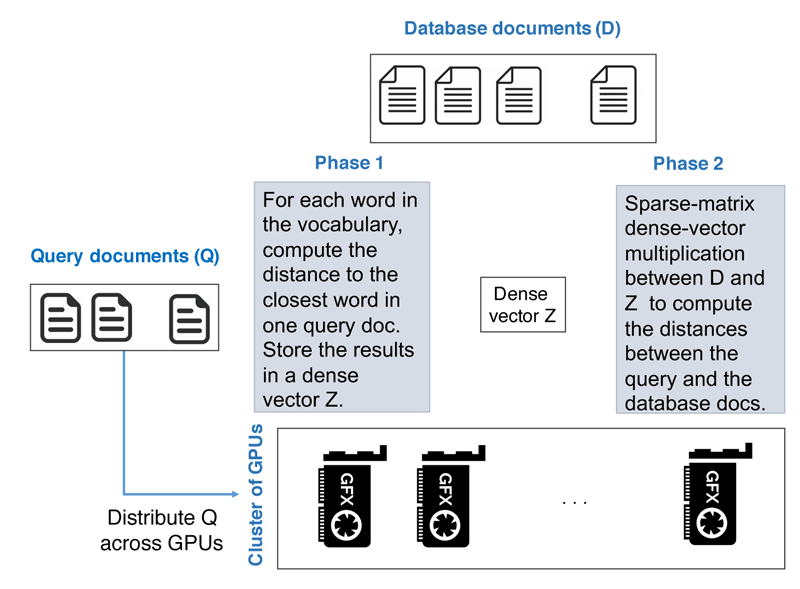
Figure 2: Overview of our approach.
The result is that, when computing the similarity of one document with h words against n documents each having on average h words using a vector space of dimension m, the complexity of the brute-force RWMD is O(nh2m), whereas under our methodology the complexity is O(nhm). The interested reader can find additional technical details about the linear complexity RWMD implementation in [3].
To showcase the performance of the new methodology, we have used very large datasets of news documents. One document is posed as the query and the search retrieves the k-most-similar documents in the database. Such a scenario can be used either for performing duplicate detection (when the distance is below a threshold), or for achieving clustering of similar news events. We conducted our experiments on a cluster of 16 NVIDIA Tesla P100 GPUs on two datasets. Set 1 comprises 1 million documents, with an average number of 108 words per document. Set 2 comprises 2.8 million words, with an average number of 28 words per document. The comparison of the runtime performance between WMD, RWMD, and our solution is given in Figure 3, which shows that the proposed linear-complexity RWMD can be more than 70 times faster than the original RWMD and more than 16,000 times faster than the Word Mover’s Distance.
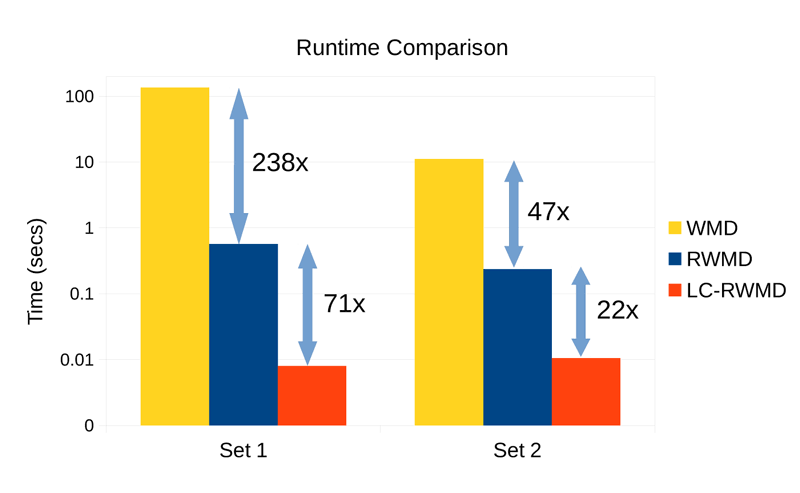
Figure 3: Time to compute the k-most-similar documents using 16 NVIDIA Tesla P100 GPUs.
The results suggest that we could use the high-quality matches of the RWMD to query – in sub-second time – at least 100 million documents using only a modest computational infrastructure.
References:
[1] T. Mikolov, K. Chen, G. Corrado, and J. Dean: “Efficient estimation of word representations in vector space”, CoRR, abs/1301.3781, 2013.
[2] M. J. Kusner, et al.: “From word embeddings to document distances, ICML 2015: 957–966.
[3] K. Atasu, et al.: “Linear-Complexity Relaxed Word Mover’s Distance with GPU Acceleration”, IEEE Big Data 2017.
Please contact:
Kubilay Atasu, IBM Research – Zurich, Switzerland