









by Keith G Jeffery
Research Infrastructures and their research communities are heterogeneous. This is a barrier to one community (re-)using the assets of another. VRE4EIC aims to overcome this heterogeneity.
Research has increasingly become specialised into communities such as oceanography, ecology, geology, materials science. However, many phenomena can only be understood by bringing together the research activities of several communities. Examples include the relationship between shellfish pollution, algal blooms and agricultural use of nitrates or the relationship between health problems, climate and social conditions. Recently, many communities have developed pan-European research infrastructures (RIs) bringing together several national research teams and assets such as datasets, software, publications, expert staff, sensors and equipment. One way to assist and encourage interdisciplinary research is to bring together the communities and assets of the RIs.
However, this collaboration comes with complications. Each community has developed its own standards for research methods, data formats, software to be used, etc. This makes it difficult for an ecologist, for instance, to utilise oceanographic data. The heterogeneity is especially evident in digital representations of data, software, people, organisations, workflows and equipment. However, many of these assets are represented digitally by metadata providing a succinct description of the asset. The metadata standard chosen varies from community to community. On the other hand, there is a limited set of basic things (entities or objects) that are involved in research (for example, data, people, samples) and so the various metadata standards have some commonality in the things they represent – although they do so in different ways.
Thus, the ‘line of attack’ to provide multidisciplinarity for researchers is to try to harmonise the metadata and thus gain access to – and (re-)utilisation of – the assets. There are two basic approaches: the software broker approach provides mapping and conversion between pairs of metadata standards. This results in n(n-1) convertor pairs. The alternative approach is to choose a canonical superset metadata standard and convert each metadata standard to/from that. This results in n convertor pairs. This metadata-driven brokering is now regarded as the best approach [1]. However, again we have two choices; the canonical superset may be realised physically – so providing an ‘umbrella’ consistent metadata resource or catalog over all the participating RIs or the superset metadata may just be a reference syntax (structure) and semantics (meaning) and each RI provides its pair of convertors. The latter approach leads to an architecture with peer RI to RI communication, requiring quite some software at each RI to interact with the other RIs and generate appropriate workflows. The former leads to a system over the RIs – linked to them via Application Programming Interfaces (APIs) – commonly named a Virtual Research Environment (VRE), which has the advantage of a ‘helicopter view’ over the participating RIs and so can generate workflows optimally. Either way, the core of a VRE is the superset catalog (whether conceptual or physical).
VRE4EIC [L1] aims at providing a model for such VREs, which includes requirements, reference architecture and implementation on two use cases to demonstrate its feasibility and innovative impact. VRE4EIC has chosen CERIF (Common European Research Information Format: an EU recommendation to Member States) [L2] to denote the superset catalog.
In fact, a VRE provides more than access to the assets of RIs; it also provides researcher intercommunication through various means and software to generate workflows to harness the available analytics, visualisation and simulation capabilities of the RIs. Ideally the VRE workflow should be optimised to ensure co-location of data and software which means moving data to the software from the various RIs participating or – especially as datasets become larger – moving the software to the data. This has implications in terms of access rights, privacy and security and in finding an equitable method of ‘payment’ for use of the RI assets. The VRE may also use e-Is (e-Infrastructures) such as eternal curated storage or supercomputing services with the requirement to manage the deployment of (parts of) the workflow to these e-Is. The VRE should assist the researcher with research management; assisting in finding relevant research, assisting in research proposals, tracking research portfolio and cataloguing research outputs (such as scholarly publications, patents, datasets, software) since increasingly funding organisations utilise such information in planning future research programmes and in evaluating the quality of research proposals.
VRE4EIC has undertaken a considerable amount of requirements collection and analysis, and has characterised many RIs to understand their available interfaces. The architecture has been designed (Figure 1) and construction is underway. The prototype will be evaluated by the RIs that are in the project first, and then other RIs will be invited to evaluate the system.
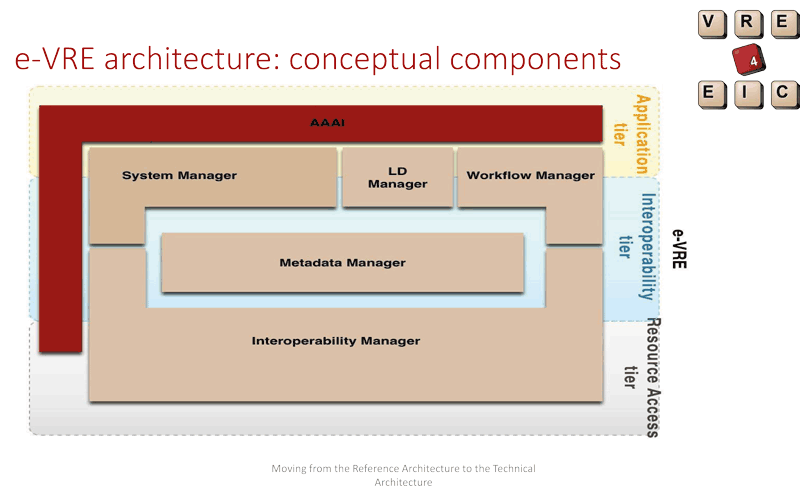
Figure 1: e-VRE architecture coneptual components.
In parallel, VRE4IC has been cooperating with other VRE projects, notably EVER-EST in Europe but also – via the VRE Interest Group of RDA (Research Data Alliance) – SGs (Science Gateways) in North America and VLs (Virtual Laboratories) in Australia. In parallel, the various metadata groups of RDA, coordinated by Metadata Interest Group (MIG), are working on a standard set of metadata elements – to be used to describe RI assets in catalogs -– which are not simple attributes with values but will have internal syntax and semantics [2].
Links:
[L1] https://www.vre4eic.eu/
[L2] http://www.eurocris.org/cerif/main-features-cerif
References:
[1] Stefano Nativi, Keith G. Jeffery, Rebecca Koskela: “Brokering with Metadata”, ERCIM News 100, http://kwz.me/W1
[2] Keith G Jeffery, Rebecca Koskela: “The Importance of Metadata”, ERCIM News 100, http://kwz.me/W2
Please contact:
Keith G Jeffery
ERCIM Scientific Coordinator of VRE4EIC

