









by Darko Brodić, Sanja Petrovska, Radmila Janković (Univ. of Belgrade, Serbia), Alessia Amelio (Univ. of Calabria, Italy) and Ivo Draganov (Technical University of Sofia, Bulgaria)
The Completely Automated Public Turing Test to tell Computers and Humans Apart (CAPTCHA) test is designed to differentiate between human users and bots. The time spent to find a solution to the CAPTCHA test is correlated with particular demographic characteristics of Internet users. This knowledge can be used to predict which CAPTCHA tests are best suited to different users.
CAPTCHA is an acronym of ‘Completely Automated Public Turing Test to tell Computers and Humans Apart’. It is a test-puzzle verified by computers that has particular characteristics that make it only solvable by humans. Essentially, the CAPTCHA is used to differentiate computer users from bots when they access a particular website. A bot (abbreviation of robot) is a software program that automatically runs tasks on the Internet, which represent a security risk. If a user correctly solves the CAPTCHA task, then the program will recognise it as a human. Hence, the aim of the CAPTCHA test is to identify attacks by bots.
Different CAPTCHA types have been proposed in the literature. The most widespread types are: (i) text-based, characterised by text and/or numbers, and (ii) image-based, related to image recognition tasks. In text-based CAPTCHA types, the user is required to recognise text and/or numbers and report them inside a text field. Figure 1 shows an example of text-based CAPTCHA types.
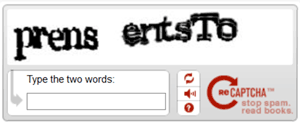
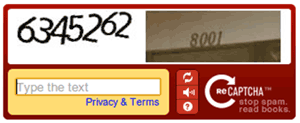
Figure 1: Text-based CAPTCHA samples: only text (left), and only numbers (right).
In image-based CAPTCHA types, the user is required to identify a certain image among a collection of images. It can include the identification of image types in a specific context, i.e. a house with numbers, an animated character, a picture of the CAPTCHA or an old woman, and the identification of images related to psychological states in the context, i.e. a worried face or a surprised face. Figure 2 depicts an example of image-based CAPTCHA types.


Figure 2: Image-based CAPTCHA samples: picture of CAPTCHA (top), and surprised face (bottom).
There has been relatively little research into the usability of the CAPTCHA test: how easy it is for a user to solve the CAPTCHA. The main limitations of the proposed approaches to analysis are: (i) the number of users involved in the analysis, which is quite small (i.e., the statistical significance of the tested population), (ii) the reduced user population features, and (iii) the low number of considered CAPTCHA types [1].
We extend the way of analysing CAPTCHA usability based on the time spent for a user to find a solution to the CAPTCHA. We recruited approximately 200 volunteer users for this study. Each user was interviewed to evaluate their time spent to solve the CAPTCHA test. Each user provided anonymous personal data including: age, gender, education level and Internet experience (in number of years). Users included students, engineers, teachers, and employees, with ages ranging from 18 to 52 years, with different levels of experience in Internet use. Each user was required to solve the text and image-based CAPTCHA types and their response times were recorded.
This data was analysed to determine whether a correlation exists between each demographic variable and the user’s response time to different CAPTCHAs. It is pursued by formulating statistical hypotheses describing such a correlation. Analysis should accept or reject the formulated hypotheses. Accordingly, the correlation coefficient and statistical tests are employed for analysis of this correlation [2]. This allows us to determine whether education level or gender, for example, has an impact on CAPTCHA response time, and the strength of the impact.
Statistical analysis was extended further by investigating the correlation between a set of demographic features and the response time to different CAPTCHAs. It was performed by extracting association rules from the population data [3]. They are rules expressing the dependence of the response time (e.g., high response time) from the co-occurrence of some demographic feature values (e.g., age below 35 years and female gender), and the strength of such a dependence.
The analysis demonstrates that number of years of Internet use, young age and a higher education level help users to quickly solve the CAPTCHA test. Gender also has a small impact on CAPTCHA solving time. Older users require a higher education level to solve the CAPTCHA with surprised and worried faces. Finally, CAPTCHA with only numbers is solved more quickly than CAPTCHA with only text, while image-based CAPTCHA has the lowest resolution time, in particular the animated character images.
This study offers invaluable insights to help predict which CAPTCHAs are best suited to different Internet users. It involves the University of Belgrade, Serbia, the University of Calabria, Italy, and the Technical University of Sofia, Bulgaria.
References:
[1] L. Ying-Lien, H. Chih-Hsiang: “Usability study of text-based CAPTCHAs”, Displays 32(2): 81-86, 2011.
[2] D. Brodić, S. Petrovska, M. Jevtić, Z. N. Milivojević: “The influence of the CAPTCHA types to its solving times”, MIPRO: 1274-1277, 2016.
[3] D. Brodić, A. Amelio, I. R. Draganov: “Response Time Analysis of Text-Based CAPTCHA by Association Rules”, AIMSA: 78-88, 2016.
Please contact:
Darko Brodić
Technical Faculty in Bor, University of Belgrade
E-mail:

