









by Michael Eickenberg, Gaël Varoquaux, Bertrand Thirion (Inria) and Alexandre Gramfort (Telecom Paris)
Recently, deep neural networks (aka convolutional networks) used for object recognition have shown impressive performance and the ability to rival the human visual system for many computer vision tasks. While the design of these networks was initially inspired by the primate visual system, it is unclear whether their computation is still comparable with that of biological systems. By comparing a deep network with human brain activity recordings, researchers of the Inria-CEA Parietal team (Saclay, France) show that the two systems are comparable.
How might we analyse and understand visual experiences from a cognitive neurosciences standpoint? Such an endeavour requires piecing together three parts of a puzzle: visual stimuli, brain measurements, and a model of natural images. First, the set of visual stimuli must be rich enough to both probe human vision in many ways and be similar to daily experience, unlike synthetic stimuli used by traditional vision neurosciences. Second, one needs a window to the brain’s activity: in humans, the most accessible measurement is functional magnetic resonance imaging (fMRI), which captures the blood oxygen-level dependent (BOLD) contrast, a vascular response following neural activity at the scale of mm and seconds. Third, one needs a high-capacity model that can analyse the information in the presented natural images: such models have recently emerged from the application of deep learning to object recognition, namely convolutional networks.
A large stimulus/response collection
We considered datasets of BOLD fMRI responses to two very different types of visual stimulation: still images and videos. In the still images dataset, 1,750 grey scale images were presented at an inter-stimulus interval of four seconds. The video stimulus set consists of movie trailers and wildlife documentaries cut into blocks of 5-15 seconds and randomly shuffled. The dataset corresponded to about five hours of acquisition. Subjects fixated a central cross while passively viewing these stimuli. The data were recorded at UC Berkeley and shared publicly [1].
Predicting the brain response with a high-capacity model
We built a model predicting brain activity from visual stimulation described by the layers of an object-recognition convolutional network [2]. Specifically, in each brain location, a linear combination of the outputs of such a network was used to fit the BOLD signal recorded with fMRI from several hours of simultaneous experimental stimulation and data acquisition.
We found that well-chosen combinations of the artificial neuron activations explain brain activity in almost all visual areas, ranging from the early ones, which are sensitive to image contrasts (such as edges), to the high-level areas which respond selectively to particular semantic information, typically object categories [3]. The linear model that encodes stimulus responses into brain activity can serve as a reliable predictor of brain activity for previously unseen stimuli.
We demonstrated this prediction with images from a left-out sample of the initial study, then with images from a different study. We synthesised the brain activity corresponding to two classical fMRI experiments: a ‘faces – places’ contrast, which depicts the activity difference between watching a face and watching a place image, and a retinotopic angle mapping: the brain response to a wedge-shaped visual pattern that slowly sweeps the visual field through a rotation.
Brain-activation maps resulting from the artificial-neuron-based predictions are compared to known maps obtained on real BOLD data and show a strong correspondence to their ground-truth counterparts. By studying the retinotopic mapping and faces versus places contrasts, we span a range of feature complexity: from topographical receptive field mapping to high-level object-recognition processes. A crucial observation is that all the layers of the deep network are needed to accurately predict those latter high-level processes: while prediction fails when a simple contour-extraction model is used instead.
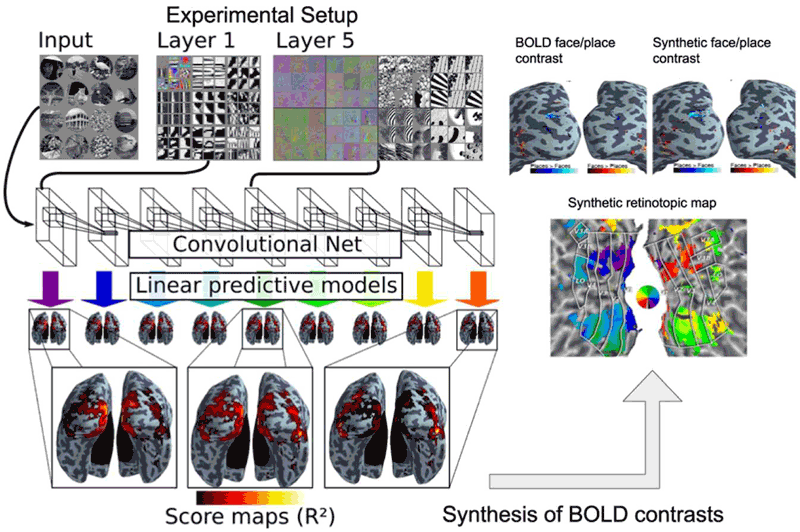
Figure 1: Convolutional network image representations of different layer depth explain brain activity throughout the full ventral visual stream. This mapping follows the known hierarchical organisation. Results from both static images and video stimuli. A model of brain activity for the full brain, based on the convolutional network, can synthesise brain maps for other visual experiments. Only deep models can reproduce observed BOLD activity.
The artificial network and the brain
To further understand the model, we assess how well each contributing layer of the convolutional net fits each region of the brain image. This process yields a characterisation of the large-scale organisation of the visual system: the lower level layers of the convolutional deep architecture best predict early visual areas such as V1, V2 and V3, while later areas such as V4, lateral occipital and dorsal areas V3A/B, call for deeper layers. The beauty of this result is the continuity in the mapping between brain activity and the convolutional network: the layer preference of brain locations is a smooth mapping, suggesting that the artificial architecture is a relevant abstraction of the biological visual system. This is not unexpected, since convolutional networks have partly been designed as a model of the visual cortex, but it is also known that the wiring of the visual cortex in humans and animals is very different from the purely feedforward model used in artificial networks.
Importantly, this finding is not tied to the experimental data used, but it transposes to a different dataset with different experimental settings: natural video stimulation.
References:
[1] K. N. Kay et al.: “Identifying natural images from human brain activity”, Nature 452: 352–355, 2008.
[2] P. Sermanet, et al.: “OverFeat : Integrated Recognition, Localization and Detection using Convolutional Networks” arXiv preprint arXiv:13126229 : 1–15, 2013
[3] M. Eickenberg, et al.: “Seeing it all: Convolutional network layers map the function of the human visual system”, NeuroImage, Elsevier, 2016.
Please contact:
Bertrand Thirion
Inria, France

