









by Victoria Ruiz, Jorge Sueiras, Ángel Sánchez and José F. Vélez (Rey Juan Carlos University)
The ATRECSIDE research project is investigating applications of deep learning models to automatic handwritten recognition problems, such as non-constrained extraction of text from document images, handwritten text recognition, and summarisation and prediction of texts.
There has been much research on a range of complex problems related with document image analysis, such as document classification and handwritten text recognition. Recently, deep learning models [1] have gained the attention of researchers for many computer vision and pattern recognition applications, due to its impressive performance. convolutional neural networks (CNN) and recurrent neural networks (RNN) are some of the most commonly applied deep learning models. A CNN consists of one or more convolutional layers (often each of these is followed by one subsampling layer), and then one or more fully connected layers as in a standard multilayer perceptron network. Figure 1 shows an example of possible CNN architecture for recognising handwritten words. A RNN allows connections between units to form directed cycles and these networks can use their internal memory to process arbitrary sequences of inputs.
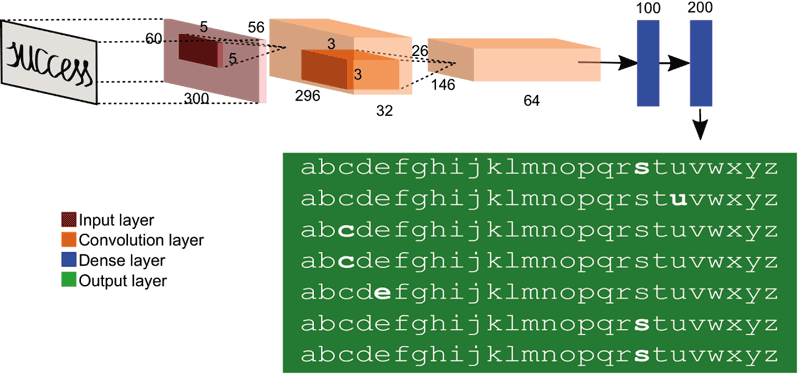
Figure 1: Possible structure of layers corresponding to a Convolutional Neural Network (CNN) trained to recognize handwritten words like: “SUCCESS”.
Handwritten text recognition is still an open problem despite of the significant advances carried out in recent years [2]. To work in practical conditions, while maintaining high recognition results, there are still several related problems to be resolved, such as: the presence of noise which makes text segmentation difficult, the high interpersonal and intrapersonal variability in handwritten text, and how to get a computational system to efficiently predict at the level of characters, words, lines or, even, paragraphs.
These problems can be managed by using deep learning techniques and related computational models like CNN or RNN. On the other hand, there exist several standard datasets [2], like MNIST, IAM and UNIPEN, which are used by scientists to report their results on these problems. The impact of recognition errors on the summarisation process is also an open problem. Some researchers have performed text summarisation from documents using deep learning techniques, but these studies do not consider the noise introduced by the recognition process.
ATRECSIDE is a project funded by the Spanish Ministry of Economy and Competitiveness under the RETOS Programme, a complementary action that encourages research on challenge areas identified by the Science and Technology Spanish Strategy. This project, which is operating between 2015 and 2017, aims to investigate problems related to the extraction of semantic content of images scanned from documents using deep learning approaches. In the ATRECSIDE project, we are working on three main problems: (1) non-constrained segmentation of handwritten text from document images (including historical manuscripts), (2) handwritten text recognition, and (3) automatic summarisation and prediction of texts from recognised documents. Three Spanish companies, namely Investigación y Programas, S.A., Graddo, S.L., and Bodegas Osborne, have expressed their interest in the development and results of this project.
More specifically, in the context of the abovementioned second and third problems, we are working on text recognition from image documents in two complementary directions.
First, we are using character and word-level image recognition models that we have created [3] to perform a first identification of the text content that appears in the images. Next, we use language models to complete the identification of the correct text based on the own system’s context. This is similar to human behaviour: when we read a ‘difficult’ handwritten text, we first try to visually recognise each word in the text and if we are not sure about the meaning of a given word, we try to identify it using the context provided by its neighbour words.
To this end, we are applying deep CNN and deep RNN to evaluate different strategies to recognise the word images. We first defined character-level image models, and applied them with a sliding window over the word images. Good recognition results were achieved with this approach, obtaining an accuracy of 87.5% for the handwritten char-level model with a new synthetic database built in the ATRECSIDE project. We are now working with word-level models that combine deep recurrent and convolutional networks and use of a novel loss function called the connectionism temporary classification (CTC) [3]. Our first experiments with random sequences of 10 digits built with the MNIST database achieved recognition accuracy by 99% when identifying the correct character sequence.
Second, we are also using two approaches in working with language models: one is defined at character-level and the other at word-level. For the former, our models can predict the next character after a sequence of previous characters. These models, which used long short term memory (LSTM) recurrent networks, were tested over the book ‘Don Quixote’ by Miguel de Cervantes and achieved an accuracy of 58.9% when predicting the next character based on the 20 previous characters.
Future work within the ATRECSIDE project will focus on developing more advanced word-level language models to predict the next word based on previous and next words and combine the two approaches to build a complete system for the handwritten recognition problem.
Link:
http://atrecside.visionporcomputador.es
References:
[1] I. Goodfellow, Y. Bengio, A. Courville, “Deep Learning”, The MIT Press, 2016.
[2] L. Kang, et al.: “Convolutional Neural Networks for Document Image Classification”, Proc. Intl. Conf. Pattern Recognition (ICPR), Stockholm (Sweden), 2014.
[3] J. Sueiras, et al.: “Using Synthetic Character Database for Training Deep Learning Models Applied to Offline Handwritten Character Recognition”, Proc. Intl. Conf. Intelligent Systems Design and Applications (ISDA), Springer, Porto (Portugal), 2016.
Please contact:
José F. Vélez, Rey Juan Carlos University, Spain
+34 91 4887489

