









by Peter Kieseberg, Edgar Weippl (SBA Research) and Sebastian Schrittwieser (JRC TARGET, St. Poelten University of Applied Sciences)
The information stored in databases is typically structured in the form of ‘B+-Trees’ in order to boost the performance of querying for information. Less well known is the fact that B+-Trees also store information on their actual construction, which permits the detection of manipulation attempts.
The majority of database management systems (DBMSs) are optimised for maximum efficiency in retrieving information from the stored tables. This means that special data structures are required that reduce the number of times that storage needs to be accessed when seeking a specific item. One of these structures is the B+-Tree, which has become the de-facto standard for storing information in most database management systems. It is also used in file storage systems like ReiserFS, NFTS or Btrfs (see [L1]). B+-Trees structure the data into a balanced tree with a maximum of b elements and b/2 to b+1 child nodes per inner node, with b being a natural number selected before the generation of the tree. While typical implementations possess some additional optimization techniques to speed up linear scanning and other operations important in databases, the fundamental structure the same for most current database management systems.
The properties of trees for optimisation of search queries have been studied extensively (see [1] as an example), but one aspect has been widely neglected. The precise structure of the tree for a given set of data elements (hereafter called indices for convenience and because database tables are typically structured along indices) is not unique, i.e. the same set of elements can result in differently structured B+-Trees. This characteristic can be used to gather knowledge about the generation of the tree. More precisely, it is possible to show that trees that are generated by inserting the indices in ascending order have a very specific structure as shown in Figure 1. It must be noted, however, that the index needs to be a unique key and that no deletion is allowed in the tables. While these criteria seem to be rather specific in nature, they are obeyed by many databases, as they typically enforce the existence of such a primary key, at least as internal key unseen to the user. Furthermore, database information in SOX-compliant environments (or other regulations focussing on traceability) is typically not allowed to be changed after insertion, thus resulting in INSERT-only tables.
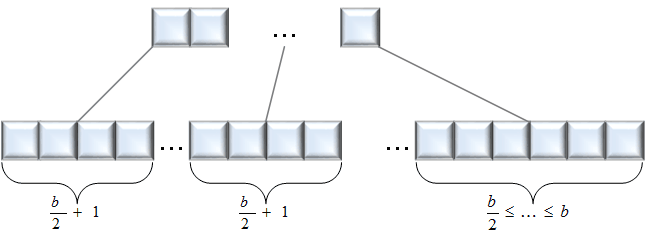
Figure 1: Structure of a B+-Tree generated by insertions in ascending order.
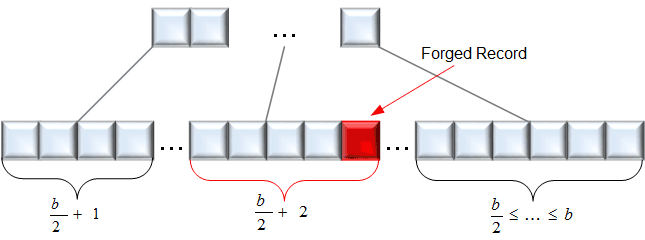
Figure 2: Detection of manipulated records.
This criteria can be used for detecting a certain kind of manipulation, namely a targeted attack, that is problematic for most current detection methods, which typically rely on sanity checks: The attacker, who must have access to the database and knowledge about the internal workflows, manipulates the data just before an important workflow, e.g. a billing process, is started and afterwards restores the original (unmanipulated) version of the information. Thus, the manipulation only exists at the time of the workflow execution, all other workflows, especially those used for cross checking and sanity checks, will work on the unmanipulated data, the manipulation thus solely propagates to the targeted workflow. Such attacks are especially interesting in order to remove information from billing workflows, KPI (Key Performance Indicator) calculations and such. While the manipulation is typically not detectable by countermeasures based on sanity checks, log files might capture the changes. Still, log files are typically only checked when errors or strange results are detected elsewhere, e.g., by cross checks. Furthermore, logs can be manipulated by any user possessing administrator privileges on the database.
In our work (see [2]) we provided a new method for the detection of the aforementioned attack by proofing the structure outlined in Figure 1, as well as showing that typical instances of this manipulation attack result in different tree structures (see Figure 2). Here, nodes suddenly possess too many elements, which can easily be detected in open source databases like MySQL. Still, even in these databases it is virtually impossible for the attacker to remove the traces, even when he/she is has administrator privileges.
While this is an interesting result, we are currently investigating further options for using the underlying tree structure of database tables for manipulation detection. Here, our main interest lies in relaxing the side parameters, for example, by allowing random insertion of a unique index, or some degree of deletion. We are also researching whether more specific information on the development of tables can be extracted from the structure of the underlying search tree. Finally, ‘table reorganisations’ have been identified as a problem for the proposed method, thus we are currently striving to implement measures to keep the structural information preserved.
In conclusion, we can see that the internal structures of databases store interesting information for thwarting advanced manipulation attacks. Still, a lot of additional research is needed in order to (i) make the current approach more resilient against database-internal optimisations and (ii) to develop more general approaches that allow detection under relaxed side parameters.
Link:
[L1] https://btrfs.wiki.kernel.org/index.php/Main_Page
References:
[1] H. Lu, Y. Y. Ng, Z. Tian: “T-tree or b-tree: Main memory database index structure revisited”, in Database Conference, 2000, ADC 2000, Proc., 11th Australasian, pp. 65-73. IEEE, 2000.
[2] P. Kieseberg, et al.: “Trees Cannot Lie: Using Data Structures for Forensics Purposes”, in European Intelligence and Security Informatics Conference (EISIC 2011), 2011.
Please contact:
Peter Kieseberg, SBA Research, Austria

