









by Leon Gorissen, RWTH Aachen University) and Philipp Brauner (RWTH Aachen University) Germany)
Open Science promises better, faster, and more trustworthy research and benefits arise if data can be shared, aggregated, and reused. We present data-to-knowledge pipelines in an engineering context as a practical way to turn open research data into additional insights and tangible benefits across organizations. Drawing on shared data from industrial robots across organisations, the work illustrates how open infrastructures can enable collaboration at scale.
Open Science has become a strategic priority for the European Commission and other funding agencies, with the aim of making research more transparent, reusable, and collaborative. A key element of this vision is the effective use of open data: not only by publishing datasets, but by enabling data to be combined, interpreted, and transformed into knowledge across disciplines and institutions. We present a framework that addresses this challenge through data-to-knowledge (D2K) pipelines (Figure 1), providing a practical approach to implementing Open Science in a complex, collaborative research cluster focused on the digital transformation of production [1].
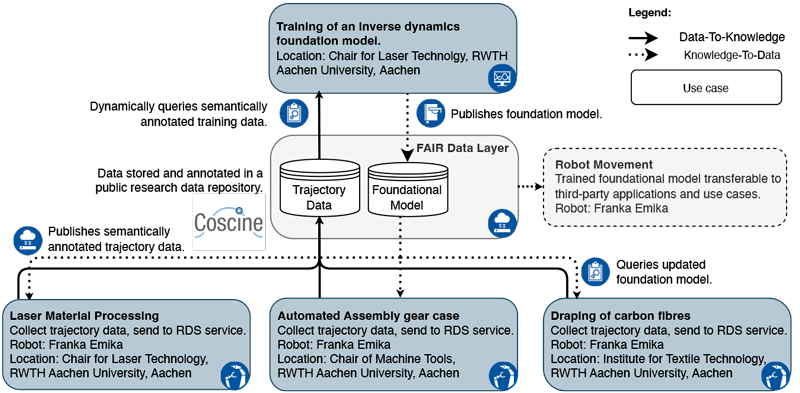
Figure 1: Data-to-knowledge pipeline illustrating how shared production data are transformed into reusable models and insights across organisations.
The article shows how openly shared research data from different organisations can be systematically transformed into insights that benefit multiple stakeholders. Instead of treating data publication as an end point, the proposed pipelines emphasize continuous processes in which data is produced, shared, enriched with meaning, analysed, and then fed back to inform new experiments, models, or decisions. This approach aligns with the principles of Open Science, particularly reuse, transparency, and reproducibility.
A central concept in the work is the use of Digital Shadows [1]. These extend the idea of Digital Twins by providing context- and task-dependent, purpose-driven representations of real-world entities such as machines, processes, or experiments. Digital Shadows capture both data and its contextual meaning. By standardizing how data is described and linked to real-world objects, they make shared data easier to understand and reuse, even beyond its original application. This is particularly important for interdisciplinary research, where data often needs to move across domain boundaries.
We demonstrate the data-to-knowledge pipelines through an industrial case study involving robotic production systems operated at different sites and by different organisations. Trajectory data from identical robot models, used independently by each organisation, is shared through a common open research data infrastructure (the open source framework Coscine [L1]). Because the data is described in a consistent, reusable way and follows the FAIR principles, it can be easily identified and queried by other processes. This enables an independent second process to query the shared data and train a more robust base model for robot control, benefiting from increasingly diverse trajectory data aggregated across sites without additional effort. The resulting model is equally openly available and improves robotic operation across sites, illustrating how open data can create collective benefits without requiring full centralisation of resources or expertise.
Importantly, the framework respects organizational autonomy while enabling collaboration. Each participant retains control over its own data and systems, while contributing selected data to a shared environment under mutually agreed conditions. This federated approach represents a highly relevant model for Open Science infrastructures, where legal, ethical, or commercial constraints often preclude full data openness. In this setting, data sharing yields reciprocal benefits: contributors and the broader community gain access to a more robust shared base model for robot control, which can in turn enhance local operations while supporting collective advancement. More broadly, the framework enables a “world-wide lab” (WWL) paradigm in which production environments function as distributed experiments, contributing empirical evidence toward a deeper understanding of factors influencing performance, quality, and safety [1,2]. Crucially, participation requires only limited additional effort while offering tangible gains through collaboration.
From an Open Science perspective, the proposed data-to-knowledge pipelines support several key goals. They improve reproducibility by making data findable, accessible, and interoperable, and reusable as data is publicly available and transformations explicit and traceable. They enhance reuse by providing semantic descriptions that allow data to be understood beyond its original project. They also encourage collaboration, as shared pipelines and models create incentives for participants to contribute data and expertise.
The article also looks ahead to future research infrastructures. As scientific data volumes continue to grow, simply storing open datasets will not be enough. Especially in the domain of resource intensive training of machine learning models, researchers will need shared tools, pipelines, and services that help turn data into knowledge efficiently and responsibly. The presented framework offers a blueprint for such infrastructures, building on open standards and tools, using modular components, and demonstrating real-world applicability.
In summary, the work shows how Open Science can move beyond ideals toward implementation and applicability. By focusing on data-to-knowledge pipelines, it demonstrates how open data can become a living resource, continuously reused, enriched, and transformed, supporting transparent and collaborative research across disciplines and sectors.
Acknowledgements: Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy - EXC-2023 Internet of Production - 390621612.
Link:
[L1] https://coscine.rwth-aachen.de/
References:
[1] P. Brauner et al., “A Computer Science Perspective on Digital Transformation in Production,” ACM Trans. Internet Things, vol. 3, no. 2, 2022, doi: 10.1145/3502265.
[2] M. Behery et al., “Vision Paper: Leveraging Industrial Big Data – Past, Present, and Future of the World Wide Lab,” in Proc. IEEE Int. Conf. on Big Data, 2023, doi: 10.1109/BigData59044.2023.10386257.
[3] L. Gorißen et al., “Demonstrating Data-to-Knowledge Pipelines for Connecting Production Sites in the World Wide Lab,” , arXiv preprint arXiv:2412.12231, 2024. [Online]. Available: https://arxiv.org/pdf/2412.12231.
Please contact:
Leon Gorißen, Chair for Laser Technology
RWTH Aachen University, Germany

