









by Aradina Chettakattu and Denis Havlik (AIT Austrian Institute of Technology GmbH)
Building and using a common terminology is of great importance for all collaborative work. On the other hand, well implemented tagging of documents by several “orthogonal” vocabularies provides a concise representation of context and topics of a textual data, which facilitates search and retrieval, as well as automated matching of “similar” documents in knowledge management systems. Manually finding relevant keywords for documents is a daunting task, time-consuming and prone to errors. Our “Voctractor” (from “Vocabulary Extractor”) application prototype [L1] addresses this challenge by streamlining both the vocabulary design and the keyword extraction workflow.
Technology
Voctractor is implemented in Python, using the flask framework, and utilieses KeyBERT [L2] for keyword extraction. According to the KeyBERT documentation, “KeyBERT is a minimal and easy-to-use keyword extraction technique that leverages BERT embeddings to create keywords and keyphrases that are most similar to a document.” [1]. It calculates cosine similarity between word embeddings and document embeddings, providing a list of suggested keywords. Simple graphical user interface has been implemented in HTML5 (Figure 1).
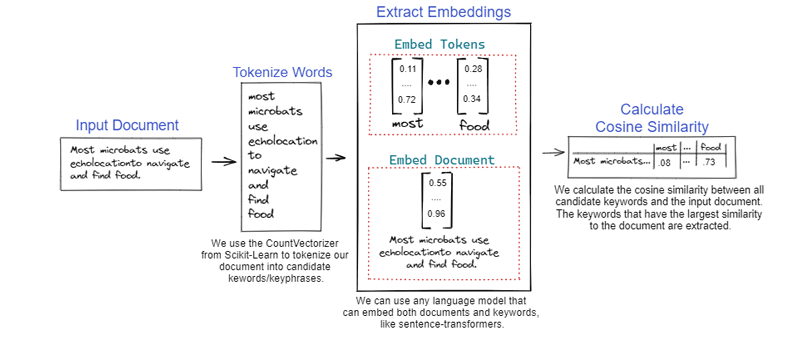
Figure 1: KeyBert diagram.
Functionality
The prototype enables a user to upload one or more documents along with initial list of “stop words” that will be ignored during the keyword extraction process and a list of “candidate” words and phrases. For each uploaded document, the program generates following three lists: (1) suggested keywords, (2) suggested keyphrases, and (3) suggested keywords and keyphrases from the “candidates” list. The first two lists can contain arbitrary words and phrases that were discovered in the document(s) by KeyBert, whereas the third is already limited by the controlled vocabulary provided by the user. For each word or phrase in these lists, two buttons are displayed: (1) cross button to reject the word and add it to the “stop words” list, and (2) check button to accept the word and save it in the “accepted” list (Figure 2).

Figure 2: Example of Voctractor keyword lists.
The prototype also presents the document text with all identified keywords/phrases highlighted (Figure 1). This feature empowers users to effortlessly identify where and how often each of the keywords and keyphrases appear in the document, thus enhancing the overall accessibility and usability of the extracted information. To diversify the results, we can use Maximal Margin Relevance (MMR) to create keywords/keyphrases which is also based on cosine similarity [2].
Intended Use
Voctractor application prototype has been designed to aid users in the process of defining controlled vocabularies that are appropriate for use in their knowledge domain and tagging the documents with the terms and phrases from such vocabularies. Recommended method for using the tool is the following:
- Decide which knowledge domain you wish to address and choose a representative sample of documents to work with.
- Choose a small number of facets that you wish to generate the (sub-) vocabularies for. For example, for the Climate Change domain, the facets could be: “document type”, “hazards”, “activity domain”, “adaptation type”, “mitigation type”, “location” etc.
- For each facet, choose a relevant (potentially very long) starting vocabulary. For example, the IPCC dictionary may be a good starting point for the “candidates” list in Climate Change Adaptation and Mitigation domain, EU Taxonomy for related activity domains, etc.
- Upload one of the files and run the program to generate the lists, then start selecting the words that you wish to supress.
- Repeat this several times, first with individual documents, and then by uploading several documents simultaneously. As a rule of thumb, a word that appears in most of the documents is not likely to be very useful for search and matching and probably shouldn’t be used in tagging.
- Repeat the process again, this time concentrating on choosing the words that you want to add to facet-specific keyword list.
- Repeat the whole process for each facet, while iteratively refining the facet definitions if necessary. Words previously added to one of the facet-specific vocabularies can (should) be immediately added to the stop word list for other dimensions.
Conclusions and Future Scope
The Voctractor application prototype was developed in the MAIA project, as a tool to help us streamline the process of discovering relevant and useful keywords and keyphrases for annotating the documents pertinent to Climate Change Adaptation and Mitigation in a way most useful for later document search and retrieval.
One feature that is currently missing is the fourth list extracting the relevant keywords and keyphrases from the “accepted” list. In addition, some simple way should be designed to test how often the words from each of the faceted dictionaries appear in a larger set of test documents and indicate if there are anomalies such as words appearing in too many or too few documents or discovering correlations between presumably independent facets.
Voctractor has been designed and developed in the EU-funded project, MAIA, under the grant agreement ID: 817527 and facilitated by numerous discussions with Kate Williamson and Sukaina Bharwani from the Stockholm Environment Institute, Andrea Geyer-Scholz from Smart Cities Consulting and Marcelo Rita-Pias from the Federal University of Rio Grande -FURG, Brazil.
Links:
[L1] https://github.com/ChettakattuA/Voctractor
[L2] https://github.com/MaartenGr/KeyBERT
References:
[1] M. Grootendorst, “KeyBERT,” https://maartengr.github.io/KeyBERT/ [online].
[2] M. Grootendorst, “KeyBERT- Maximum Marginal Reference (MMR),” https://maartengr.github.io/KeyBERT/guides/quickstart.html#maximal-marginal-relevance [online].
Please contact:
Aradina Chettakattu, AIT Austrian Institute of Technology, Austria
Denis Havlik, AIT Austrian Institute of Technology, Austria

