









by Peter Kieseberg, Simon Tjoa (St. Pölten UAS) and Andreas Holzinger (University of Natural Resources and Life Sciences)
The burgeoning landscape of AI legislation and the ubiquitous integration of machine learning into daily computing underscore the imperative for trustworthy AI. Yet, prevailing definitions of this concept often dwell in the realm of the abstract, imposing robust demands for explainability. In light of this, we propose a novel paradigm that mirrors the strategies employed in navigating the opaqueness of human decision-making. This approach offers a pragmatic and relatable pathway to cultivating trust in AI systems, potentially revolutionising our interaction with these transformative technologies.
During recent years, and especially since the stunning results Chat-GPT brought to the general public, the discussion on how to secure society against drawbacks and dangers resulting from the ubiquitous use of AI has gathered momentum. In addition, the AI Act by the European Union, which has been in the making for a while already, is on the home straight. It will not only set the stage for a common market regarding AI-driven systems in the EU but will also set the rules on putting AI into the market, especially concerning forbidden and high-risk AI applications. In order to mitigate potential risks of these applications, distributing companies will need to be able to conduct risk management and make their AI transparent.
In order to align AI development with these requirements, the term “trustworthy AI” was defined, although different expert groups arrived at different definitions. The two most noteworthy are those of the High-Level Expert Group (HLEG) [L1] of the EC and the NIST [1], which have a lot of overlap, but also some distinct differences. While the HLEG speaks about so-called “key requirements”, the NIST uses the notion of “characteristics”. Figure 1 gives a short overview on both definitions and outlines similarities between them and here you get an overview [2].
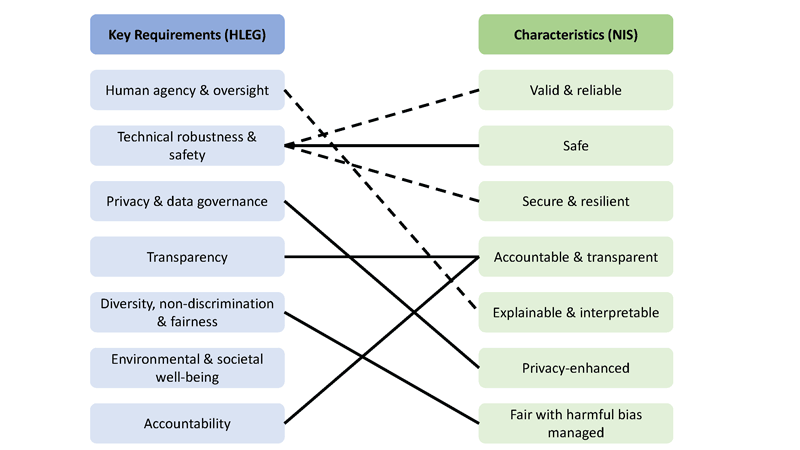
Figure 1: Comparing definitions for Trustworthy AI according to HLEG and NIST.
Both definitions work in the same direction, while the one devised by the HLEG also includes environmental and societal wellbeing as a requirement, which needs to be discussed, as this requirement is not a technical but a moral/philosophical one, and makes it hard to, e.g. define trustworthy military applications. Still, the major issue in both definitions is the requirement for explainability, as stated explicitly in the fifth characteristic in the NIS definition and several other requirements/characteristics, especially those concerning biases, non-discrimination, accountability and transparency. Also, the issue of providing security is difficult for many machine learning algorithms, as issues of emergence and non-explainability make standard tools for security testing difficult. Thus, developing trustworthy AI-based systems must be considered as difficult to impossible for many applications, especially those sporting large and complex networks with reinforcement components like a doctor in the loop in cancer detection. Still, these are the interesting applications for AI that will be the technological drivers for the coming years, yet the requirements for trustworthy AI are very demanding.
This is in stark contrast to how we deal with human decision-making. Typically, we are not able to explain our own decision-making process, as many decisions are derived subconsciously. Thus, we are actually asking more from AI than from humans, as for the latter, we typically only want to control whether a decision-making process is more or less correct and, if it is not, we want to make sure it is either corrected or the defaulting person faces consequences This we can easily transform into the notion of “Controllable AI” [3] with the two main requirements:
1. We need to establish controls to detect when an AI system deviates too much from the target/typical behaviour.
2. We need to introduce methods for recalibrating or shutting down the system when such misbehaviour is detected.
Thus, the core idea behind Controllable AI is the assumption that no AI system should be deemed reliable, and it is essential to establish mechanisms for detecting malfunctions and reasserting control. This definition does not call for explainability, as it is not required to be able to explain how and why a correct or incorrect conclusion was reached by the system; it only requires the detection of conclusions that are too far off the correct behaviour. As a comparison, many functions of the human digestive system are still not understood by science, and even less by the common person, but many severe malfunctions are easily detectible by everybody based on body reaction.
The methods required for achieving Controllable AI are diverse and need to be tailored to the specific system in question. Some examples for techniques that could be facilitated:
- Sanity Checks that bound the correct results and are obtained by knowledge or far simpler, explainable models.
- Critical data surveys that find biases and data poisoning in the training/reinforcement data instead of having to disassemble a complex model.
- Backdoors that allow control over a system that does not correctly react on input.
- Explicitly training the network for neglecting invalid decisions.
- Divine rules used for cross-checking the result of the decision-making process, e.g. rules that drop decisions that result in human harm, even if they are considered to be the best solution by the neural network.
- Non-AI alternatives for a process, or alternatives that, while providing less exact results, can be explained easily and in short time.
Furthermore, it is especially important to put the assumption of failure into the system design itself, i.e. Controllable AI is not a set of techniques that can be slapped onto the finished product, but constitutes a design philosophy for AI systems, much like privacy by design or cyber resilience.
In our future work, we plan to delve deeper into concrete measures and technologies for achieving Controllable AI, as well as providing respective design patterns. Furthermore, the concept will be included in our procurement guide for secure AI systems [L2], which is available for free.
Links:
[L1] https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
[L2] www.secureai.info
References:
[1] E. Tabassi, “Artificial Intelligence Risk Management Framework (AI RMF 1.0),” 2023.
[2] A. Holzinger et al., “Information fusion as an integrative cross-cutting enabler to achieve robust, explainable, and trustworthy medical artificial intelligence,” Information Fusion, vol. 79, no. 3, pp. 263–278, 2022. doi:10.1016/j.inffus.2021.10.007
[3] P. Kieseberg et al., “Controllable AI-An Alternative to Trustworthiness in Complex AI Systems?,” in International Cross-Domain Conference for Machine Learning and Knowledge Extraction, pp. 1–12, Springer Nature, 2023.
Please contact:
Peter Kieseberg, St. Pölten University of Applied Sciences, Austria

