









by Katsumi Emura (Fukushima Institute for Research, Education and Innovation) and Dimitris Plexousakis (FORTH-ICS)
This article provides a brief report on the 4th Workshop jointly organized by ERCIM and the Japan Science and Technology Agency (JST). The workshop, themed “Exploring New Research Challenges and Collaborations in Artificial Intelligence, Big Data, Human-Computer Interaction, and the Internet of Things,” took place in October 2023 in Kyoto, Japan. Hosted by JST as part of the Advanced Integrated Intelligence Platform project, the event offered European and Japanese participants an opportunity to report on recent research results in the aforementioned areas and to explore collaboration prospects within the framework of European Commission programs or corresponding initiatives of JST.

Figure 1: Participants of the 4th Workshop jointly organized by ERCIM and the Japan Science and Technology Agency.
The workshop was co-chaired by Dr. Katumi Emura, Director of the Fukushima Institute for Research, Education and Innovation at JST AIP Network Laboratory, and Prof. Dimitris Plexousakis, Director of the Institute of Computer Science at FORTH. It was attended by 9 researchers from Europe and approximately 20 researchers from Japan. The workshop was structured around four parallel themes, each coordinated and facilitated by one researcher from Europe and one from Japan. The themes were:
1. Trustworthy and Reliable Human-Machine Symbiotic Collaboration,
2. Extracting Actionable Knowledge in the Presence of Uncertainty,
3. Trust in Data-Driven Research: The Role of Actors, Research Infrastructures, and Processes, and
4. Infrastructure and Service Resilience for a Smart Society.
The remainder of this article comprises brief reports on the discussions and outcomes of the respective groups.
Following opening remarks by the co-chairs, the first day’s keynote address was delivered by Prof. Hiroshi Ishiguro of Osaka University on “State-of-the-Art Human-Robot Interaction Research,” highlighting exciting achievements in interaction with robotic avatars and their advanced features. The second day featured a keynote address by Dr. Hiroko Tatesawa, Director of JST’s Department of Strategic Basic Research on Activities for Promoting Basic Research and International Collaboration. Beyond the plenary sessions, the four groups convened in parallel sessions, comprising presentations by members and lively discussions on challenges and topics for joint research
On the last day of the workshop, each of the four groups reported on the outcomes of their discussions with brief presentations on specific research questions and topics for further research. The workshop’s steering committee convened in a closing session to assess the outcomes and discuss plans for the continuation of this series of workshops. The 5th edition of the Joint Workshop will be hosted by ERCIM member SZTAKI (Hungarian Institute for Computer Science and Control) in October 2024 in Budapest, Hungary, as an event collocated with the ERCIM Fall meetings.
Theme 1: Steps towards Trustworthy and Reliable Human-Machine Symbiotic Collaboration
Contributors: Giorgos Flouris, Satoshi Nakamura, Wen Gu, Rafik Hadfi, Loizos Michael, Theodore Patkos, Seitaro Shinagawa, Katsuhito Sudoh, Hiroki Tanaka, Koichiro Yoshino
Robotics is experiencing a paradigm shift from heavy-duty industrial robots towards intelligent agents operating in our homes, interacting with people without technical skills, in environments that are open, complex, and unpredictable. To cope with such environments, AI must address a diverse set of challenges and acquire new skills.
Europe, with its strong capacity in research and academia and a well-established ecosystem of scientists, developers, suppliers, and end-users, has already set these challenges as strategic, short-to-mid-term objectives. This is evidenced by the recently announced Strategic Research Innovation and Deployment Agenda of the ADR Association [L1], and the Statement on the Future of AI in Europe published by the CLAIRE organization [L2]. These objectives are coupled with a clear desire to preserve certain ethical values, such as trustworthiness and transparency, often enforced through regulatory frameworks like the forthcoming AI Act. Similarly, Japan is pioneering the adoption of cutting-edge AI and Robotics research results in the industry, thereby boosting innovation and maximizing economic and societal impact.
Research collaboration opportunities between Europe and Japan in human-machine symbiotic collaboration are creating a fruitful ground for yielding positive results for both regions, if structured on top of a well-defined plan. This was the objective of Group 1 at the 4th JST/ERCIM Joint Workshop. Human-machine collaboration can be achieved across various domains, including education, healthcare, business, society, and economics, through the appropriate implementation and deployment of smart assistants. Several examples are illustrated in Figure 2, across different scales and domains.
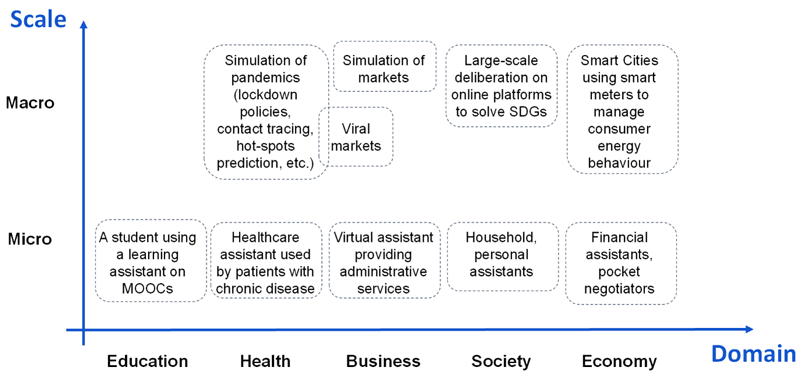
Figure 2: An organisation of the relevant use cases along 5 different domains and for different scale (micro or macro).
To promote trustworthiness and reliability in these domains, machines should be able to explain their actions and the reasons behind them. Contestability, the ability to propose methods, trial and error, and collaboration on par with humans, is also important. Indicators and criteria for quantifying aspects of explainability and contestability are necessary, respecting fairness, bias, and accountability, depending on their purpose.
Socially aware communication and interaction encompass diverse aspects, including cognitive, linguistic, cultural, and social differences that shape human connections. Understanding both verbal and non-verbal communication, such as intentions and emotions, is crucial.
In other words, such systems require cognitive skills that highlight the necessity for reasoning abilities aligned with human thought, particularly in exhibiting a “Theory of Mind,” i.e., understanding others' beliefs, intents, desires, and emotions. These reasoning abilities include the use of common sense and causality to predict human actions in various contexts, especially where implicit knowledge is involved. They also encompass the use of argumentative reasoning for rational discourse and decision-making, along with social cognition to navigate social interactions and norms. Together, these skills are vital for AI systems to integrate effectively into human settings, and are expected to require the adoption of insights from Cognitive Science, Psychology, and the social sciences, despite the anticipated interdisciplinary challenges.
Furthermore, a symbiotic environment highlights the need to integrate contextual information. This environment thrives on the collaboration between humans and artificial agents, augmenting human capabilities and emphasizing the necessity for adaptability. Social and cultural awareness play pivotal roles, necessitating adherence to regulations and social norms to avoid misunderstanding. Establishing common ground through defining, aligning, and using new concepts is pivotal, fostering shared understanding and facilitating smooth interactions across diverse cultural and social contexts, aligned with human societal values.
Human-centric adaptive learning via automatic feature selection with proper learning strategies is also a promising direction to consider. Desired features in these learning strategies should include cognitive development, the ability to learn online, and the ability to make actionable predictions.
Foundation Models and Large Language Models (LLMs) significantly enhance human-machine interaction but face limitations in logical reasoning. Integrating neuro-symbolic methods can address these limitations by enriching the symbolic reasoning capabilities within LLMs.
Multi-agent-based simulations, coupled with agent communication, will fine-tune perceptions and enhance cognitive abilities, facilitating real-world error correction and knowledge emergence.
Overall, the synergy among these technologies is paving the way for more general AI. Each technology offers unique strengths, pushing towards more versatile and efficient systems. This collaborative evolution highlights a trend towards AI that is more context-aware and autonomous, progressively integrating into a unified AI ecosystem.
To promote collaboration between Europe and Japan on the above topics, we have planned activities that take into account the cultural differences and backgrounds, as well as the characteristics of the two research ecosystems, starting with a SWOT analysis (Strengths, Weaknesses, Opportunities, Threats). One aspect of complementarity could be neuro-symbolic AI in the EU and deep learning AI and humanoid robots in Japan. More applications to EU-Japan collaboration calls will be encouraged, as well as tools to improve networking, such as postdoctoral fellowships, professorial sabbaticals, researcher exchanges, or student exchanges/internships. Joint academic ventures such as joint workshops, joint editorship of journal special issues, and joint online degrees (open university style) would also be beneficial in promoting collaboration.
Links:
[1] https://adr-association.eu/
[2] https://claire-ai.org/
Please contact:
Giorgos Flouris, FORTH-ICS, Greece
Satoshi Nakamura,NAIST, Japan,
Theme 2: Extracting Actionable Knowledge in the Presence of Uncertainty
Contributors: D. Laurent, N. Spyratos, Y. Tanaka, H. Tokuda, A. Uchiyama, K. Yamamoto and T. Yoshihiro
The main objective of this group was to study the concept of uncertainty and its impact on actionable knowledge extraction. Our approach considers uncertainty in the context of data pipelines, whose importance and complexity are increasingly significant nowadays. Good service provision by a data pipeline largely depends on data quality, with uncertainty being one of the factors influencing it. Therefore, we decided to pursue two lines of research: (a) identifying the factors that influence data quality in some relevant research areas; (b) attempting to define data quality in each of these areas, potentially revealing commonalities. The following is a brief report of our first meeting’s findings.
Databases
One of the most frequent data quality problems in databases is missing values. Incomplete datasets can disrupt data pipelines and have a devastating impact on downstream results if not detected. Various approaches to impute missing values exist, but comprehensive benchmarks comparing classical and modern imputation approaches under fair and realistic conditions are scarce [L1]. Another common data quality problem is the violation of semantic constraints, such as key constraints. A data table violating these constraints can disrupt data pipelines and cause significant damage in critical applications. Designing algorithms to "repair" such tables before use is a current challenge in the field of databases [L2]. An approach to repairing tables with missing values and violating semantic constraints was presented at the meeting [L3].
Signal Processing
Restoration of observed values, or signal values, is a central part of applications in signal processing. Restoration typically refers to denoising, interpolation, and deblurring. Most restoration problems can be formulated as inverse problems with appropriate regularization terms. Extracting features and discovering knowledge from observations requires more than just signal processing; the pipeline includes sensing, signal processing, database creation, and machine learning. To improve data quality for downstream tasks, integrating sensing, signal processing, and databases should be considered. While a similar approach, known as ISAC (integrated sensing and communications), has been considered in telecommunications [1], its concept needs to be extended to broader applications.
Data Quality and Trust
Data is a spatio-temporal reflection of the real world. In this sense, data has a scope, and reality within this scope can be projected into the data. The scope can be objectively described and defined as a data profile. Data quality expresses how accurately and precisely reality within the frame was projected, representing the uncertainty of reality mapping. Data quality is crucial because it affects the performance of the data processing pipeline [2]. However, defining it is challenging due to numerous metrics, including accuracy and missingness. People will trust data if its quality ensures the data pipeline's performance. A definition of data quality and a systematic quality assurance methodology are necessary to establish trust.
Reliability of Labels
Label reliability is crucial for AI model development [3]. Definitions of activities may differ by context, and privacy concerns often require subjects to self-label activities, potentially leading to inaccuracies that compromise AI model reliability. To mitigate this, large data volumes are collected under the assumption that most labels are correct, although this approach is labor-intensive. Clarifying labeling instructions can reduce ambiguity, and employing multiple annotators is another strategy. This approach is commonly used in computer vision due to the ease of distributing image and video data. However, privacy-sensitive data, such as in-home activity recognition, cannot be easily multi-annotated, presenting a persistent challenge that requires further research to improve annotation accuracy.
Links:
[1] https://www.frontiersin.org/articles/10.3389/fdata.2021.693674/full
[2] https://marceloarenas.cl/publications/pods99.pdf
[3] https://link.springer.com/article/10.1007/s10844-022-00700-0
References:
[1] F. Liu, et al., “Integrated sensing and communications: Toward dual-functional wireless networks for 6G and beyond”, IEEE journal on selected areas in communications. 2022;40(6):1728-67.
[2] J. Byabazaire, et al., “Using Trust as a Measure to Derive Data Quality in Data Shared IoT
Deployments” ICCCN2020, 2020, pp. 1-9, doi: 10.1109/ICCCN49398.2020.9209633.
[3] A. Olmin and F. Lindsten, “Robustness and Reliability When Training With Noisy Labels”’, in Proc. of the AISTATS 2022, vol. 151, pp. 922–942.
Please contact:
Nicolas Spyratos, Universite Paris Saclay and FORTH-ICS
Yuichi Tanaka, University of Osaka
Theme 3: Trust in Data-Driven Research
Contributors: Andreas Rauber, Satoshi Oyama, Hisashi Kashima, Naoto Yanai, Jiyi Li, Koh Takeuchi, Akiko Aizawa, Dimitris Plexousakis, Katharina Flicker
Research in virtually all disciplines is increasingly reliant on data collected from a variety of sources, pre-processed, and analyzed through complex processes by numerous stakeholders. The complexity of processing pipelines, the multitude of actors and steps involved, and the extensive reuse of code from diverse sources pose numerous challenges regarding the trust we can place in the correctness of the processing applied. A critical question arises: how much trust can we place in our own research outputs (and those we reuse from others) when we cannot verify every single data instance, code, and processing step applied?
This leads to questions about what constitutes trust in data and code quality, the processing applied, the differences between scientific disciplines and cultures, the necessary understanding of trust to make it measurable, and the activities required to build and maintain trust long-term. Additionally, it's important to consider how research infrastructures meeting specific trustworthiness criteria can assist in this process. Answers to these questions are essential for determining the trustworthiness of research outcomes and, consequently, the degree of accountability we can accept for our findings, i.e., the quality of our research.
Elements and Facets Influencing Trustworthiness
We explore trust through a simplified research process (Figure 3) consisting of defining research questions, which drive a loop of data and code feeding into processing that produces an output, ultimately leading to insights or knowledge. This process is embedded in the contexts of principles and expectations of Communities of Practice, human stakeholders, the organizations they are embedded in, and the technical infrastructures within which the research is conducted.
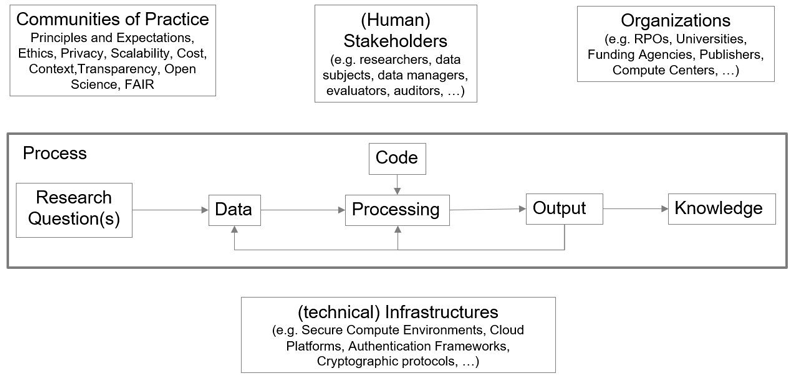
Figure 3: (Selected) Elements participating in the Trust Network.
For each of these elements, an extensive (though not exhaustive) set of attributes or facets influencing perceptions of trust can be identified. "Quality" is interpreted as "fitness for purpose" in a given setting. This implies that there are no absolute indicators of quality that justify trustworthiness for any element in this setting. Quantification of trustworthiness needs to be contextual to the activity being performed. Figures 4 and 5 provide examples of attributes and facets identified for the elements Data and Code, respectively, as well as their connections to their context.
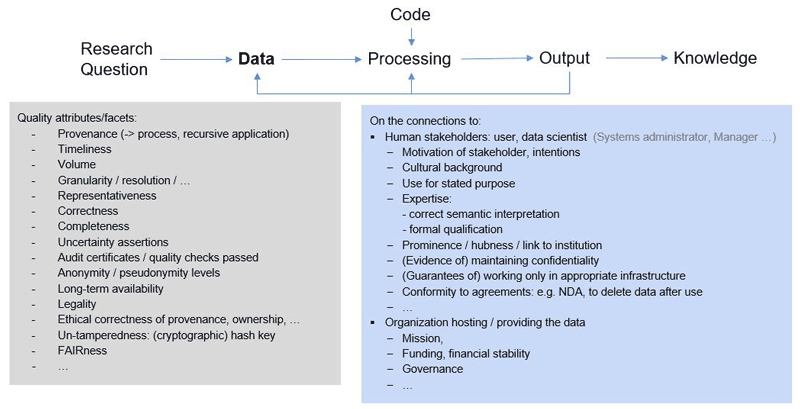
Figure 4: (Selected) quality attributes / facets influencing trustworthiness on the Data element and its connections.
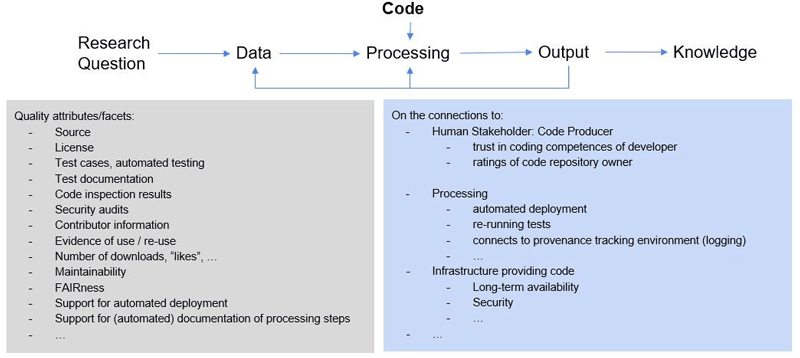
Figure 4: (Selected) quality attributes / facets influencing trustworthiness on the Data element and its connections.
Planned Activities
The initial “trust diagram” outlined in Figure 3 will be expanded through user studies, interviews, and questionnaires to provide a more comprehensive picture of the facets influencing trust, potential indicators, and guidance on how to explore thresholds that may indicate sufficient fulfillment to merit trust. Focusing on specific settings, such as secure computing environments, will allow for a more comprehensive evaluation. Additionally, exchange visits will help in eliciting cultural differences across regional and disciplinary boundaries.
Please contact:
Andreas Rauber, TU Vienna, Austria,
Theme 4: Infrastructure and Service Resilience for Smart Society
Contributors: Chrysostomos Stylios, Takuro Yonezawa
The group consisted of eight individuals (two in person and six remotely) from Europe and four from Japan who met both physically and virtually during the 4th JST & ERCIM Joint Workshop 2023. This group is dedicated to investigating existing challenges and new research missions to achieve integrated and harmonized resilience, utilizing state-of-the-art technologies such as AI, Robotics, Big Data, Human-Computer Interaction (HCI), and the Internet of Things (IoT). The group also aims to tackle emerging ethical, legal, and social issues (ELSI), as well as challenges related to responsible research and innovation (RRI).
All participants presented their interests, experiences, and expectations, focusing on the challenges they anticipate in the future. They decided to concentrate on new use cases such as mobility issues, Federated Smart Cities, Industry-Society 5.0, the Internet of Realities, and education. The group discussion led to three main directions, each with a specific focus:
1. An Integrated Framework for Scalable and Secure Device Onboarding, Identity Management, and Context-Driven Trust in IoT Networks (Prof. Okabe, A. Fournaris, Prof. Teruya, K. Stefanidis, I. Politis, and V. Liagkou): This direction focuses on investigating advanced authentication mechanisms to ensure secure access to digital services, efficient encryption techniques to protect sensitive data, developing intelligent AI-based systems capable of detecting and mitigating cyber threats in real-time, and proposing new protocols that integrate security measures at every layer of the digital infrastructure to mitigate vulnerabilities and minimize the impact of potential breaches.
2. Cooperative, Trustworthy, and Data-Efficient Intelligence for Dynamic Groups of Robots/UVs (Prof. T. Yonezawa, A. Lalos, Prof. Yamada, Prof. Haber): This direction investigates a holistic framework for collaborative, efficient, and trustworthy AI-empowered intelligence in dynamic groups of connected robots/UVs across various modalities and scales. It includes developing APIs that ensure a seamless cloud-edge and active information continuum, designing, training, and deploying robust AI models in robotic agents that require less data and energy for trustworthy and adaptable high-level performance. This direction is based on cooperative, active, transfer, and federated learning paradigms, explainability principles, model compression, acceleration tools, and data and resource-aware learning orchestrators.
3. Connected, Personalized Human-Centered AI Technologies for Facilitating Service Resilience in Smart Societies (Prof. Iwata, Prof. Stylios and Prof. T. Yonezawa): This direction will investigate advanced AI technologies that foster an integrated environment between humans and machines, enhancing social resilience by detecting conflicts among people and suggesting resolution methods. The aim is to create opportunities for new human interactions, with AI acting as a mediator. This includes exploring XR technologies and integrating avatars in smart societies, designing life cycles for AI avatars in the metaverse, and considering issues of acceptability. Specific research objectives include investigating the effects of immersive technologies on cognitive states to assess their applicability in educational settings and refining such technologies based on cognitive state assessments to improve educational engagement and outcomes.
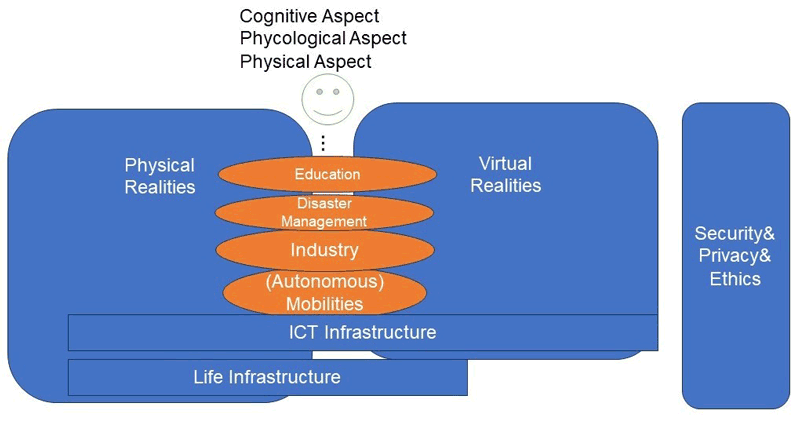
Figure 6: Illustrative overview of the contributions made by the Working Group.
The group continues to discuss, exchange ideas, and investigate open research questions for the future. The planned next steps include preparing a white paper, conducting an assessment to measure the social, economic, and environmental impacts of the collaboration's activities using key performance indicators (KPIs), designing specialized training and upskilling courses, organizing multi-layered, cross-disciplinary workshops, forming strategic alliances with industrial partnerships, and establishing a knowledge exchange program targeting young researchers, professionals, and policymakers.
Please contact:
Chrisostomos Stylios, ISI, Greece,
Takuro Yonezawa, University of Nagoya, Japan,

