









by Diego Collarana, Moritz Busch, and Christoph Lange (Fraunhofer FIT)
Despite the excitement about Large Language Models (LLMs), they still fail in unpredictable ways in knowledge-intensive tasks. In this article, we explore the integration of LLMs with Knowledge Graphs (KGs) to develop cognitive conversational assistants with improved accuracy. To address the current challenges of LLMs, such as hallucination, updateability and provenance, we propose a layered solution that leverages the structured, factual data of KGs alongside the generative capabilities of LLMs. The outlined strategy includes constructing domain-specific KGs, interfacing them with LLMs for specialised tasks, integrating them with enterprise information systems and processes, and adding guardrails to validate their output, thereby presenting a comprehensive framework for deploying more reliable and context-aware AI applications in various industries.
LLMs such as GPT-4 [L1] are a new generation of AI neuronal networks that revolutionised the way we interact with computers. Trained on massive amounts of text data, LLMs exhibit a surprising ability: the larger they get (in terms of artificial neurons), the more capabilities emerge [1]. An LLM solves a variety of NLP tasks, including question answering, machine translation, and even code generation. As a result, enterprises are begging to implement real-world applications powered by LLMs [2]. All big tech companies are in the race to incorporate LLMs into their products, e.g. Microsoft 365 Copilot [L2], for assisted content generation based on instructions (also known as prompts).
While LLMs demonstrate remarkable capabilities, they still face limitations in knowledge-intensive tasks [3], i.e. scenarios where factually correct answers are critical, such as in industrial or healthcare applications. The three main shortcomings hindering the use of LLMs in knowledge-intensive applications are hallucination, expensive updateability and lack of provenance. Hallucination refers to the tendency of LLMs to generate factually incorrect or misleading information. Expensive updateability is the struggle to incorporate new knowledge or adapt to evolving information landscapes. Lack of provenance is the ability to trace the origin of information. These problems remain a challenge for LLMs, making it difficult to assess the reliability and trustworthiness of their output.
To successfully implement LLM-enabled applications, we need to separate two components: one serving as a knowledge storage and the other providing linguistic capabilities. This approach allows us to leverage the complementary strengths of each component, i.e. the knowledge store provides factual accuracy and the linguistic capabilities of the LLM to generate creative and informative text. Figure 1 shows our approach that combines KGs and LLMs. KGs are structured sources of factual knowledge, including ontologies and taxonomies. We use KGs to provide LLMs with access to reliable and up-to-date business information, reducing hallucination and improving the accuracy in the output. We preserve the linguistic capabilities of LLMs, including their ability to understand and generate text. This combination results in a more flexible and adaptable LLM architecture that can incorporate business knowledge as needed.
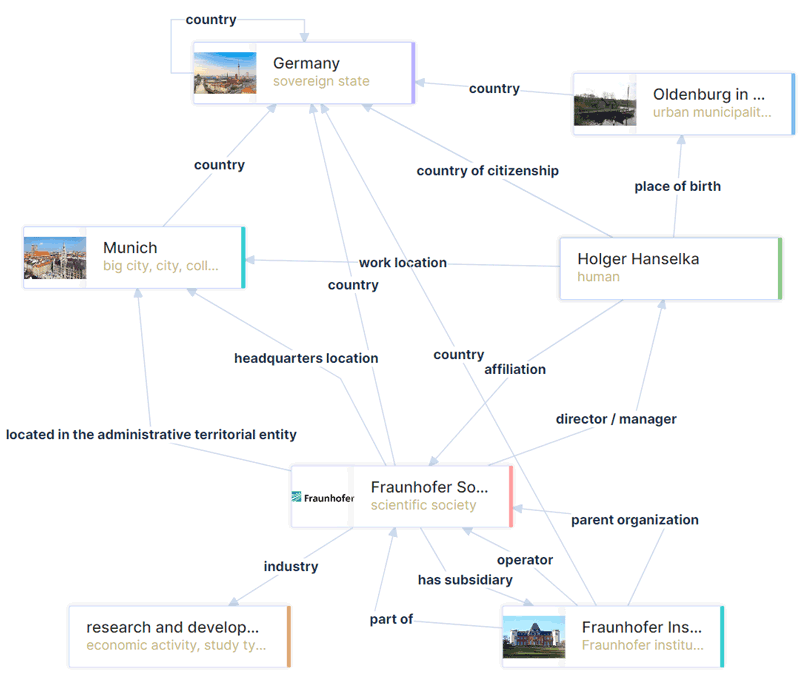
Figure 1: Knowledge Graph encoding the relationship between the Fraunhofer Society and its current president, Dr. Holger Hanselka. GPT-3 Turbo still shows Dr. Reimund Neugebauer as the current president, requiring an expensive retraining process to update this knowledge. Note that either RDF or Neo4j can be used as the technical implementation of the KG. (Source Wikidata).
Why KGs [L3] as knowledge store? The answer lies in their ability to drive agile knowledge integration, enabling organisations to seamlessly integrate heterogeneous data from disparate sources (Figure 1). KGs enable us to apply logical rules and reasoning to leverage the collective expertise of an organisation for improved knowledge discovery. KGs also unlock the potential for personalised recommendations, tailoring the user experience to individual interactions and preferences. KGs allow the maintaining of data governance and quality, enabling organisations to enforce data standards, relationships and hierarchies.
Our approach, depicted in Figure 2, focuses on the development of state-of-the-art cognitive conversational assistants, also known as copilots. These intelligent assistants harmoniously fuse KGs and LLMs. This fusion creates copilots that are not only adept at understanding context and providing accurate information, but also capable of engaging in dynamic, human-like conversations. Our approach is composed of the following steps:
1. Knowledge Graph construction: In this step, a domain-specific knowledge graph is constructed from heterogenous data sources. We encourage a pay-as-you-go KG construction, i.e. integrate only the necessary knowledge to implement a use case. The KG can be revisited and extended afterwards, incorporating further data sources if such need arises. Unlike updating knowledge in LLMs, which requires expensive retraining, extending KGs does not require much computational power.
2. Interfacing KG with LLM: As the second and main step, we use techniques, such as retrieval-augmented generation (RAG) and text-to-graph query generation, to connect LLMs bi-directionally with KGs. RAG indexes sub-graphs from the KG into a vector story: using retrieval approaches, the top-k most relevant sub-graphs are transmitted to the LLM as additional context. Text-to-graph query generation components translate natural language queries into structured queries, making it easier to extract precise and relevant information from KGs. This widens the user base of our approach, partially overcoming the necessity for graph query language knowledge.
3. Fine-tuning LLMs for domain-specific tasks: as KGs may not suffice, LLMs themselves can be tailored to specific tasks. Fine-tuning LLMs aims at an enhancement of data-driven decision-making, streamlined processes, and superior results in the field at hand. However, this comes with an increased demand of computing power. Through benchmarking, we assess the performance of LLMs in various contexts, facilitating continuous improvement and fine-tuning to meet the specific needs and standards of the target application.
4. Connecting tools: In this step, we connect existing enterprise tools with the LLM. This connection allows a seamless integration of existing software ecosystem into the copilots, enhancing user interactions and providing innovative conversational experiences.
5. Validation and analysis of outputs: To deploy an LLM-based solution into production, we need guardrails that ensure the accuracy and reliability of the LLM-generated content. In this step, we apply methods to analyse and validate the output against the structured knowledge stored in KGs. These methods allow in-depth examination of the LLM output, providing valuable insights and actionable decisions before the output is released to the user.
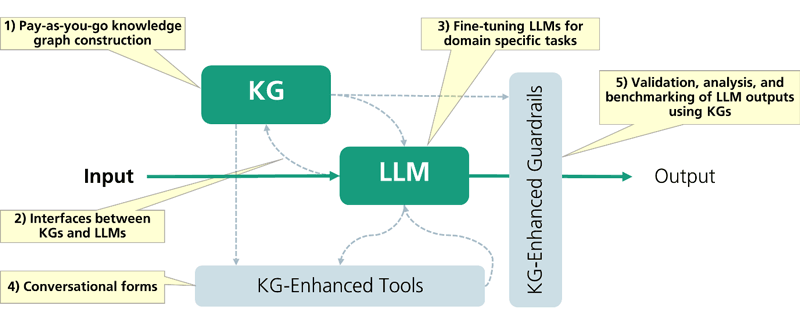
Figure 2: The approach for developing state-of-the-art cognitive conversational assistants: from building a knowledge graph, interfacing it with language models, fine-tuning models for domain-specific tasks, connecting existing enterprise tools to the model, to validating and analysing the output. All these steps are empowered using Knowledge Graphs as knowledge store of the solution.
In conclusion, the integration of LLMs with KGs represents an innovative leap forward in developing conversational assistants that are both knowledgeable and linguistically proficient. By combining the robust, up-to-date knowledge provided by KGs with the advanced text generation capabilities of LLMs, we overcome the existing limitations around factuality, updatability and provenance, enhancing the user experience but also establishing responsible deployment of AI in critical business and knowledge-intensive domains.
Links:
[L1] https://openai.com/gpt-4
[L2] https://blogs.microsoft.com/blog/2023/03/16/introducing-microsoft-365-copilot-your-copilot-for-work/
[L3] https://link.springer.com/book/10.1007/978-3-031-01918-0
References:
[1] T. B. Brown et al., “Language models are few-shot learners,” NeurIPS, 2020.
[2] R. Bommasani et al., “On the opportunities and risks of foundation models,” CoRR abs/2108.07258, 2021.
[3] S. Pan et al., “Unifying Large Language Models and Knowledge Graphs: A Roadmap,” CoRR abs/2306.08302, 2023.
Please contact:
Diego Collarana, Fraunhofer FIT, Germany

