









by Michalis Mountantonakis and Yannis Tzitzikas (FORTH-ICS and University of Crete)
Since it is challenging to combine ChatGPT (which has been trained by using data from web sources), with popular RDF Knowledge Graphs (that include high quality information), we present a generic pipeline that exploits RDF Knowledge Graphs and short sentence embeddings for enabling the validation of ChatGPT responses, and an evaluation by using a benchmark containing 2,000 facts for popular Greek persons, places and events.
The novel Artificial Intelligence ChatGPT chatbot offers detailed responses and human-like answers for many domains of knowledge; however, it can produce erroneous facts even for popular entities, such as persons, places and events. On the other hand, there are several RDF Knowledge Graphs (KGs) containing high-quality data and their provenance is recorded; however, it is difficult for non-expert users to query such data. Therefore, one challenge is how to combine GPT with popular RDF KGs for enabling the validation of ChatGPT responses with justifications and provenance. For this reason, the Information Systems Laboratory of the Institute of Computer Science of FORTH has designed a pipeline [1,2] for enabling the validation of ChatGPT facts from RDF KGs, and has created a benchmark containing 2,000 ChatGPT facts for enabling the evaluation of the mentioned pipeline [2].
Concerning the pipeline, which is also used in the online research prototype called GPT•LODS [L1], its steps are depicted in the left side of Figure 1. Moreover, in the right side of Figure 1, we show a real example for a question about “Marcell Jacobs”, the gold medallist of the 2020 Summer Olympics in the men’s 100 metres (one of the most popular events of the Olympic Games). In particular, as a first step we can ask ChatGPT a question (e.g. see Figure 1) and as a second step we can send a new prompt for asking ChatGPT to convert its textual response to RDF N-triples. As we can see in Figure 2, ChatGPT can produce syntactically valid RDF triples by using a given model/ontology (e.g. DBpedia model) [1, 2]. However, in that example, we observe some errors in the ChatGPT facts for that person (e.g. his birth date). For correcting such errors, or/and for confirming correct ChatGPT facts, the third step is to search in one or more KGs to find the corresponding facts. In particular, we use either DBpedia (by accessing its SPARQL Endpoint), or LODsyndesis KG (by accessing its REST API), which has integrated the contents of 400 RDF KGs including DBpedia, by having pre-computed the transitive and symmetric closure of their equivalence relationships.
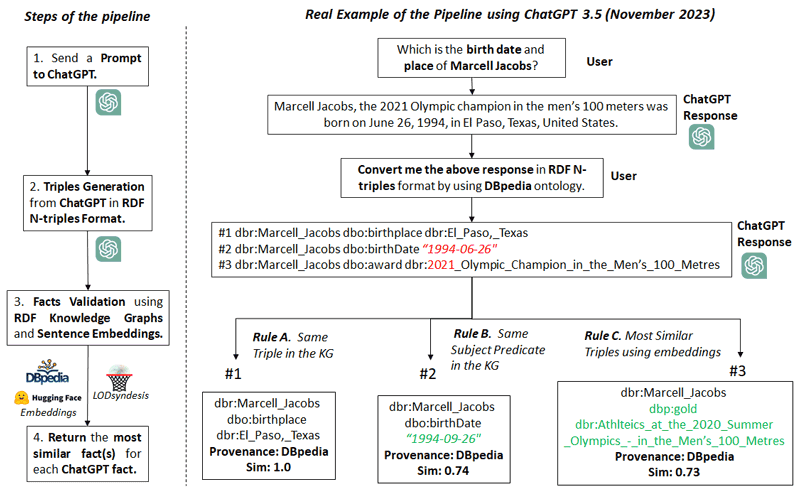
Figure 1: The steps of the pipeline and a running example.
For each fact we use an algorithm with three different rules [1, 2]. Specifically, we first search for the exact or a semantically equivalent triple in the KG (rule A). Afterwards, we search to find triples having the same subject-predicate or subject-object (rule B). Finally, (if the previous two rules failed) we search for the K most similar triple(s) by first collecting all the triples for the entity (the subject) of the triple, and by computing the cosine similarity of the embeddings between the ChatGPT fact and each triple (rule C). As a final step, the pipeline produces the K most similar triples from the KGs (and their provenance) to each ChatGPT fact and their cosine similarity score, offering to the user a kind of support for the returned facts from the KG. Concerning the example of Figure 1, for the birthplace of Marcell Jacobs, rule A was executed since we found the exact triple in DBpedia. Regarding his birthdate, rule B was executed, i.e. we found the same subject-predicate but a different object in DBpedia (i.e. the correct birth date), since his birth date was erroneous in ChatGPT. Finally, for the third fact, rule C was executed, where we found the most similar fact from DBpedia (by using embeddings and cosine similarity), and we returned it to the user (by also providing information about the provenance).
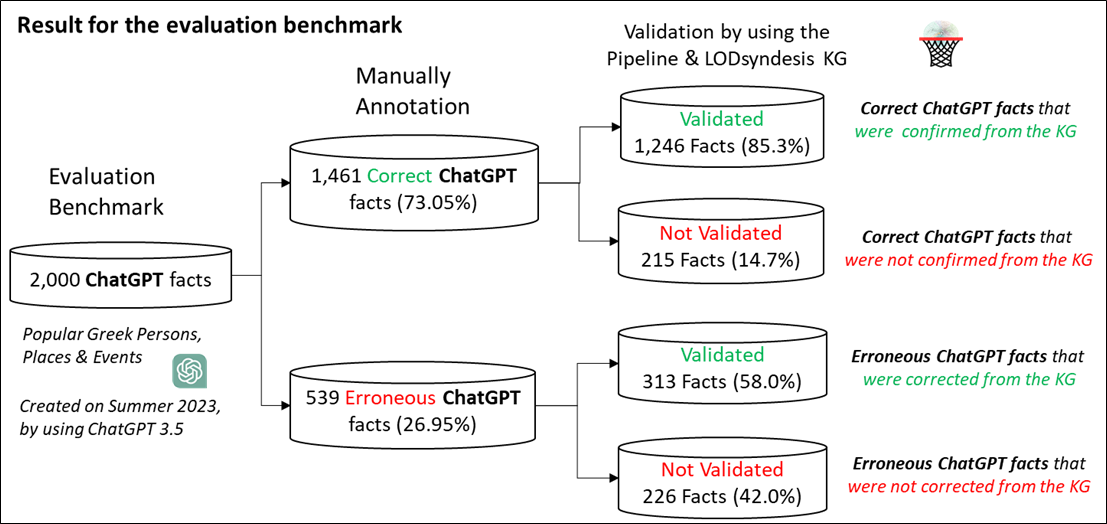
Figure 2: The evaluation benchmark and the corresponding results.
Concerning the evaluation setup, we have created a benchmark (see Figure 2) that includes 2,000 ChatGPT facts for popular Greek persons, places (including cities, mountains, lakes, heritage sites and islands) and events (including battles, sports, earthquakes and elections). The benchmark is available in a GitHub page [L2], and was created in August 2023, by using the ChatGPT 3.5 model. Regarding the collected ChatGPT facts, we manually annotated each fact as either correct or erroneous, by checking online trusted sources. Indeed, from the 2,000 ChatGPT facts, approximately 73% of them were annotated as correct and 27% as erroneous. Concerning the erroneous facts, they mainly included dates and numbers, such as birth dates, population of places, length, height and others.
Concerning the evaluation results, by using the mentioned pipeline and LODsyndesis KG (see the right side of Figure 2) we managed to confirm 85.3% of the correct ChatGPT facts (+6.2% compared to using only a single KG, i.e. DBpedia), and to find the correct answers to the 58% of erroneous ChatGPT facts (+2.6% compared to using only DBpedia). Concerning cases where the pipeline failed to find the corresponding answer in the KG(s), it included incompleteness issues, i.e. cases where the KG(s) did not contain the fact, contradicting values between different KGs and cases where the answer was included in large literals.
To tackle the above limitations, as a future work, we plan to (i) further extend the benchmark with more entities, facts and domains, (ii) evaluate the pipeline in other Large Language Models, and (iii) extend the algorithm for supporting answer extraction from large literals.
Links:
[L1] https://demos.isl.ics.forth.gr/GPToLODS
[L2] https://github.com/mountanton/GPToLODS_FactChecking
References:
[1] M. Mountantonakis and Y. Tzitzikas, “Real-time validation of ChatGPT facts using RDF Knowledge Graphs,” ISWC Demo Paper, 2023.
[2] M. Mountantonakis and Y. Tzitzikas, “Validating ChatGPT facts through RDF Knowledge Graphs and sentence similarity,” arXiv preprint arXiv:2311.04524, 2023.
Please contact:
Michalis Mountantonakis, FORTH-ICS and University of Crete, Greece
Yannis Tzitzikas, FORTH-ICS and University of Crete, Greece

