









by Gábor Berend (University of Szeged)
The use of transformer-based pretrained language models (PLMs) arguably dominates the natural language processing (NLP) landscape. The pre-training of such models, however, is known to be notoriously data and resource hungry, which hinders their creation in low-resource settings, making it a privilege to those few (mostly corporate) actors, who have access to sufficient computational resource and/or pre-training data. The main goal of our research is to develop such a novel sample-efficient pre-training paradigm of PLMs, which makes their use available in the low data and/or computational budget regime, helping the democratisation of this disruptive technology beyond the current status quo.
Masked language modelling (MLM) is a frequently used pre-training objective of PLMs, enjoying its popularity due to its ease of implementation and its ability to produce pre-trained models that can achieve state-of-the-art models given that the pre-training was conducted over a sufficient number of training steps on a sufficiently large and diverse pre-training corpus.
Traditional MLM pre-training works similarly to fill-in-the-blank tests, i.e. the neural language models are expected to develop an ability to insert the correct substitute in a partially given sentence, where the missing words are indicated by a special MASK symbol. For example, given the input sentence “Sarah is eating a peach.”, with the word “peach” being the word that was randomly chosen for masking, a neural model would be expected to output such a probability distribution for the potential substitutes of the token [MASK] in a sentence “Sarah is eating a [MASK].”, which puts all the probability mass to the token “peach” (see Figure 1). Expecting the neural model to assign all the probability mass to a single word seldom constitutes a plausible behaviour from a common-sense perspective, since there exists a handful of other words besides the single word “peach” that would serve as a cognitively sound replacement of the [MASK] token, including words like “pizza”, “croissant”, “soup”, etc. The reason why this kind of pre-training still works is because pre-training is conducted over a large and diverse enough collection of pre-training corpus, which makes the behaviour of the pre-trained language model make sense in the long run, making its outputs acceptable to humans.
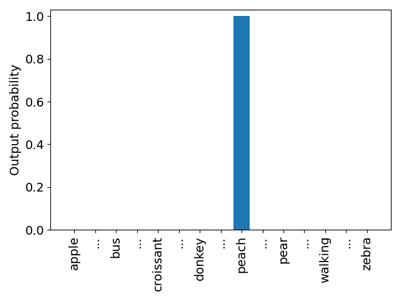
Figure 1: The kind of distribution expected during Masked Language Modelling pre-training.
Arguably, we could enjoy a more sample-efficient pre-training if the target distribution of potential substitutes would involve an actual distribution over the words such that it puts a nonzero probability to more than just a single-word form (see Figure 2). It is nonetheless unrealistic to have access to such a pre-training corpus, which contains all the possible replacements of any arbitrarily chosen word in it. Enhancing pre-training with the semantic properties of the masked words could also improve the sample efficiency of the pre-training (see Figure 3); however, the availability of a pre-training corpus that is annotated with the semantic properties of the words even at a moderately large scale is equally unrealistic.
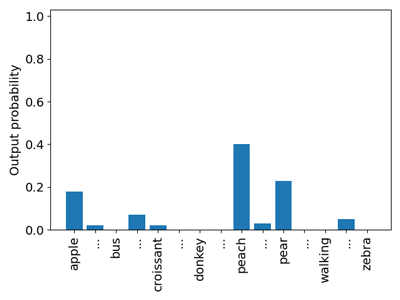
Figure 2: The kind of distribution expected during idealised pre-training.
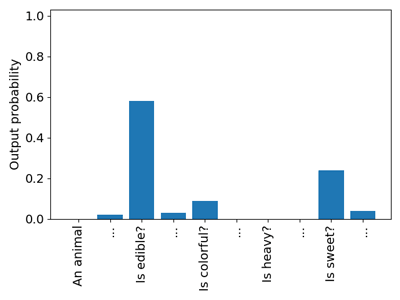
Figure 3: The kind of distribution expected during semantically enhanced pre-training.
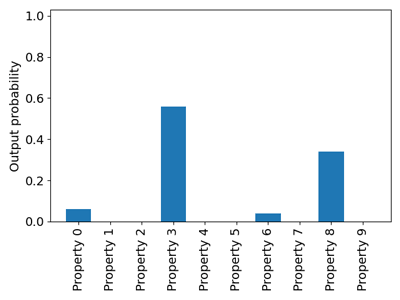
Figure 4: The kind of distribution expected during MLSM pre-training.
To improve the sample efficiency of the pre-training – without the need for any additional annotation of the pre-training corpus – we introduced a novel unsupervised pre-training objective, masked latent semantic modelling (MLSM) [1]. Our approach performs a context-sensitive multi-clustering of the masked words, based on their neural representation, and we use the cluster membership of the words in their context as the target distribution to perform the pre-training on. When comparing this kind of pre-training with traditional MLM and other forms of knowledge distillation (KD) methods, we have seen vast improvements in sample efficiency, i.e. the pre-trained language models have reached much better downstream performance at much earlier stages of the pre-training process. We have demonstrated the utility of the proposed pre-training objective for multiple PLM architectures. While our primary focus of investigation was English so far, we have also successfully used the proposed pre-training objective for pre-training language models in Hungarian [2]. As the entire approach is unsupervised, it can be conveniently applied to any language without the need for any modification in the methodology. Due to its favourable sample efficiency, MLSM pre-trained PLMs can be especially useful in scenarios when the pre-training corpus size is limited for some reason.
Most recently, we also participated at the BabyLM Challenge [L1], where the goal was to build PLMs over a pre-training corpus consisting of no more than 10 million words (in contrast, the Chinchilla model was trained over more than 100,000 times as many, 1.3 trillion words). The challenge has also attracted media attention [L2] as well as that of academic participants, as more than 120 models were submitted by more than 30 participating teams. Our submission, which was based on MLSM, got ranked 2nd, indicating its applicability in low-resource scenarios. We made the model that we submitted to the challenge publicly available [L3].
We are currently experimenting with new variants of the previously proposed MLSM approach that can yield further improvements in sample efficiency. Additionally, we would like to expand our results to additional (low-resource) languages and investigate these models from an interpretability point of view in the future.
This research received support from the European Union project RRF-2.3.1-21-2022-00004 within the framework of the Artificial Intelligence National Laboratory. Additionally, we are grateful for the support from the HUN-REN Cloud infrastructure.
Links:
[L1] https://babylm.github.io/
[L2] https://www.nytimes.com/2023/05/30/science/ai-chatbots-language-learning-models.html
[L3] https://huggingface.co/SzegedAI/babylm-strict-small-mlsm
References:
[1] G. Berend, “Masked Latent Semantic Modeling: an Efficient Pre-training Alternative to Masked Language Modeling,” In Findings of the Association for Computational Linguistics: ACL 2023, pp. 13949–13962, Jul. 2023.
[2] G. Berend, “Látens szemantikus eloszlások használata a nyelvi modellek előtanítása során,” XIX. Magyar Számítógépes Nyelvészeti Konferencia.
[3] G. Berend, Better Together: Jointly Using Masked Latent Semantic Modeling and Masked Language Modeling for Sample Efficient Pre-training, Association for Computational Linguistics, 2023.
Please contact:
Gábor Berend, University of Szeged, Hungary

