









by Chara Tsoukala, Georgios Paraskevopoulos and Athanasios Katsamanis (Athena Research Center)
The Greek National Theatre has introduced an advanced chatbot based on Large Language Models (LLMs) as a novel means of accessing the content of the digital archive on the web. This state-of-the-art chatbot, which utilises Text2SQL conversion through LLMs, offers a more intuitive user experience, enabling complex searches with simple natural language. This addition marks a significant step forward in making theatrical performance data accessible in a more interactive way.
Large Language Models (LLMs) have emerged as transformative tools, revolutionising the way that we interact with complex data systems. These advanced AI models are known for their ability to understand and generate human-like text, making them ideal for a range of applications. The Greek National Theatre (GNT) has leveraged this technology to revolutionise access to its extensive digital archive content. By implementing a sophisticated chatbot that utilises Text2SQL conversion through LLMs, the Greek National Theatre has made its vast collection of past performances, theatrical works, and multimedia content accessible through a simple, natural language interface. This approach not only enhances the user experience by simplifying the interaction with the theatre archive’s content but also enables more nuanced and complex searches, setting a new standard in how we access and explore historical data in cultural heritage and the arts.
Large Language Models (LLMs) like GPT-3 are not just skilled in understanding and generating human-like text; they also hold immense potential in enhancing database utilisation and management, particularly in structured data querying using SQL. This capability is especially transformative for the GNT digital archive. The archive contains a plethora of information on plays, performances, actors, directors, costumes, sets, and multimedia elements. However, accessing this data traditionally requires specific technical know-how. With the integration of LLM technology, however, this wealth of information becomes far more accessible to a broader audience, significantly simplifying the process of extracting valuable insights from this extensive source of knowledge.
The chatbot employed at the GNT digital archive is more than just a digital assistant; it’s an intelligent conversational system integrating state-of-the-art AI technologies. Users interact with the archive through a specialised widget within the web application of the GNT digital archive. They can type queries in natural language about performances, actors and other relevant topics, receiving precise answers linked to the digital content in the archive. The LLM, with tailored prompting, translates user natural language queries into SQL, fetches results, and presents them in natural language. This dual conversion process not only makes information retrieval intuitive but also allows for complex queries, such as searching for specific plays or performances featuring certain actors within a certain time period. For instance:
User: “Which actor has had the most leading roles?”
Assistant: “The actor who has starred the most is Alexis Minotis, with 26 leading roles.”
User: “I want to see photos from performances after 1970 in which Minotis has acted.”
Assistant: “I found the following performances after 1970 in which Minotis has acted:
- Oedipus at Colonus (1989)
- The Sacrifice of Abraham (1989–1990)
- The Phoenician Women (1988)
- The Father (1987–1989)
- Endgame - Act Without Words (1986–1987)
- The Cardinal of Spain (1981–1982)
- Happy Days - Endgame (1979–1987)
- Prometheus Bound (1979–1981)
- Buddha (1978)
- The Phoenician Women (1978–1981).”
In this scenario, as depicted in Figure 1, the chatbot enriches its response by providing links, allowing the user to further explore the play’s webpage for additional information. In collaboration with the theatre’s dramaturge, we have developed various such scenarios to ensure that a wide range of potential user inquiries could be addressed. These scenarios include simple searches like finding a specific performance, detailed information about a work, personnel involved, and multimedia material from performances. There are also complex searches, such as finding performances with common attributes, like international tours or specific actors, within a certain time frame. The chatbot’s “persona” is a theatre enthusiast, knowledgeable about the entire digital archive, offering users a unique and engaging way to explore theatrical history.
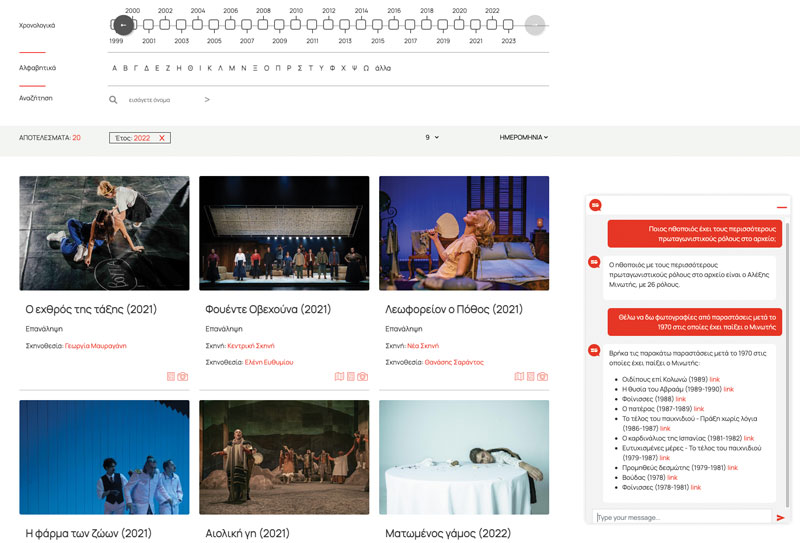
Figure 1: The Greek National Theatre archive interface featuring the chatbot widget, displaying results related to the above scenario in Greek.
While this technology marks a significant advancement, it is not without challenges. The accuracy and complexity of queries depend on the chatbot’s understanding and the database’s structure; there is an upper limit to the complexity of the database, after which we observe hallucinations and incomplete queries. Additionally, ensuring the chatbot’s personality remains engaging and informative without overwhelming the user is crucial.
The application of an intelligent conversational system based on LLMs for accessing information from a theatrical digital archive is a pioneering example of how AI can enhance cultural heritage content. This approach could be replicated in other fields, opening new avenues for interacting with historical and educational archives. The future may see further advancements in LLMs and Text2SQL technologies, leading to even more sophisticated and intuitive user experiences. This approach not only enhances visual interaction but also deepens the users’ engagement with the rich history of theatrical arts, making it more accessible and enjoyable for everyone.
Please contact:
Chara Tsoukala, Institute for Language and Speech Processing, Athena Research Center, Greece

