









by Ioanna Antoniou-Kritikou, Voula Giouli, George Tsoulouhas and Constandina Economou (ATHENA Research Centre)
Our research is aimed at employing Large Language Models (LLMs) to build a multi-dimensional paraphrase tool in view of enhancing reading comprehension and writing skills of learners of Greek as mother tongue, second or foreign language (L1, L2/FL). The idea is to integrate ChatGPT into classroom settings, thus turning Generative AI from a threat to an assistant.
Today, Generative Artificial Intelligence (AI) and LLMs have a significant impact in various industries and domains like healthcare, entertainment, customer services, content creation, etc. Education is one of the areas it has generated enormous impact, both positive and negative. We report on ongoing research conducted at the Institute for Language and Speech Processing/ATHENA Research Center aimed at exploring new ways to incorporate Generative AI technologies in reading comprehension and writing pedagogy applications.
More particularly, our research is aimed at building a multi-dimensional paraphrase evaluation system that aids the enhancement of reading comprehension and writing skills of users of Greek as L1, L2/FL. In doing so, we seek to investigate new ways to integrate LLMs in AI-driven language learning and assessment applications focusing on Modern Greek and in a way that ethical considerations surrounding Generative AI in education [L1] are considered. Ultimately, instead of confronting Generative AI as a threat to educational settings, we integrate it into a language learning application in an innovative way.
Paraphrasing is a demanding task that is relevant not only to writing but also – and primarily – to reading comprehension. It involves the restating of other authors’ ideas using one’s own words, keeping, however, the meaning of the initial text intact. Studies have highlighted the need for research on paraphrasing as both an academic writing skill and a textual borrowing skill at diverse levels. In the Greek secondary school curriculum, paraphrasing is being neglected and, in this respect, our system can be used to enhance research on this topic and prepare students for tertiary education.
So far, paraphrase evaluation is treated either as a binary task or – at best – as a task of assigning a score on a scale using known metrics mainly adopted from Machine Translation. Our approach is different in that the system evaluates paraphrased text at various levels (word, phrase, sentence) and by taking various parameters into account [1]. The starting point is text generated either by ChatGPT (using predefined prompts) or by humans (Source); users are asked to produce a paraphrase of this text (Target). The Source and Target texts are fed as input to a Paraphrase Evaluation module trained on LLMs to validate the paraphrase produced; the system also spots segments that possibly need to be further worked on along with the operations (changes) that can be applied in view of increasing the paraphrase score. Based on this output, a textual feedback generation module provides a set of suggestions that can be used as hints helping users to improve their paraphrase. Multiple iterations/repetitions of the procedure are feasible so that users revise their text based on the score and the hints they receive from the system; users decide when to stop this recursive process.
System Architecture
The Paraphrase Evaluation module consists of two different subsystems. The first one takes the Source and Target texts as input. We employ an algorithm that uses standard NLP techniques (part-of-speech tagging, lemmatisation, dependency parsing, named entity recognition) coupled with a set of knowledge sources and semantic similarity metrics to analyse the Source and Target text segments and measure their similarity. These knowledge sources comprise a set of manually crafted paraphrase rules that identify the surface modifications applied to the Source [2], and semantic lexica in the form of knowledge graphs. The system keeps track of these modifications and identifies the total possible changes that could have been made, according to the rules. Therefore, the output of the paraphrase evaluation system for a Source and Target text is an array that includes (a) a “paraphrase score” calculated by taking into account the lexical and structural divergence (Div) of the two texts against their semantic similarity (Sim), and (b) a list of tokens and token groups (phrases) of the Target that could be improved. This JSON-encoded list also contains the lexical changes that the user can use on each of the tokens to improve the paraphrase.
To further enhance our Paraphrase Evaluation module, we also take advantage of a machine learning model using the Greek edition of BERT pre-trained Language Model [3] and a dataset that comprises a manually annotated corpus modelling paraphrase at various levels (lexical, phrasal, textual). Then, a classifier trained on the pre-trained model and the paraphrase corpus takes the Source and Target texts and returns a value that corresponds to the quality and complexity of the paraphrase.
At the last stage, the system provides feedback to the user based on the output of the Paraphrase. Evaluation module in the form of a paraphrase score and (optionally) hints to improve paraphrasing. The latter appears in the system’s UI in the form of a popover over the highlighted text segments (as shown in Figure 1).
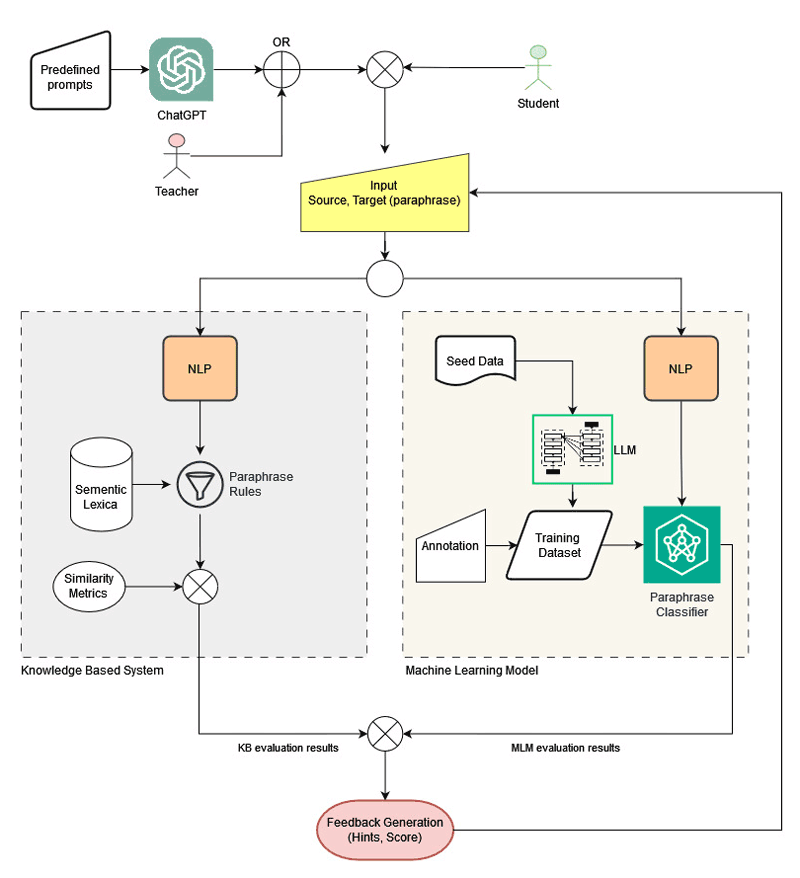
Figure 1: The flowchart diagram of the system.
The outcome of our research is manyfold: (a) multi-dimensional system that can be used in both self-learning and class settings, (b) a suite of NLP tools (classifier, feedback generation tool), and (c) the relevant paraphrase dataset. As this is ongoing research, the intrinsic validation of the system is still pending, whereas the extrinsic evaluation is due after implementing the system in classroom settings.
Future extensions have already been envisaged towards incorporating other functionalities that are relevant to downstream NLP tasks such as summarisation, text simplification and text classification. We also envisage further fine-tuning the system towards adapting the feedback provided by the system based on the users’ level of language proficiency in Greek.
References:
[1] P.M. McCarthy et al., “The components of paraphrase evaluations,” Behavior Research
Methods, vol. 41, pp. 682–690, 2009. https://doi.org/10.3758/BRM.41.3.682
[2] R. Bhagat and E. Hovy, “What Is a Paraphrase?,” Computational Linguistics, vol. 39, no. 3, pp. 463–472, 2013.
[3] J. Koutsikakis et al., “GREEK-BERT: The Greeks visiting Sesame Street,” In 11th Hellenic
Conf. on Artificial Intelligence (SETN 2020). ACM, 110–117, 2020. https://doi.org/10.1145/3411408.3411440
Please contact:
Ioanna Antoniou-Kritikou, Institute for Language and Speech Processing, ATHENA Research Centre, Greece

