









by Javier Cámara, Javier Troya and Lola Burgueño (ITIS Software / Universidad de Málaga)
There is a growing body of work assessing the capabilities of Large Language Models (LLMs) for writing code. Comparatively, the analysis of the current state of LLMs with respect to software modeling has received little attention. Are LLMs capable of generating useful software models? What factors determine the quality of such models? The work we are conducting at ITIS-UMA investigates the capabilities and main shortcomings of current LLMs in software modeling.
The Institute for Software Engineering and Software Technology (ITIS) at the University of Málaga is positioning itself at the forefront of research concerning the impact of LLMs on various aspects of the modern world, most notably in the field of software development. In a recent publication, we delved into the realm of software modeling, investigating the potential of LLMs, like ChatGPT, in changing the way software is created and managed.
This work [1], which was openly published in the Software and Systems Modeling journal (SoSyM), explores the current capabilities and limitations of ChatGPT in the context of software modeling. Through a series of experiments and analyses, we sought to understand the extent to which LLMs could assist modelers in their work, as well as the potential pitfalls and challenges that may arise in the process.
One of the primary objectives of the study was to establish whether ChatGPT can generate both syntactically and semantically correct unified modeling language (UML) models. Through a range of tests, we found that while ChatGPT can indeed produce generally accurate UML models, there are still some notable shortcomings in terms of semantic correctness and consistency.
The sensitivity of ChatGPT to context and the domain of the problem at hand was another aspect that we investigated in our study. The findings are aligned with the common functioning of neural networks, i.e. the more data ChatGPT has been exposed to regarding a particular domain, the more accurate the generated models are likely to be (Figure 1). Conversely, when there is a lack of information or context, the models produced by ChatGPT tend to be less reliable.
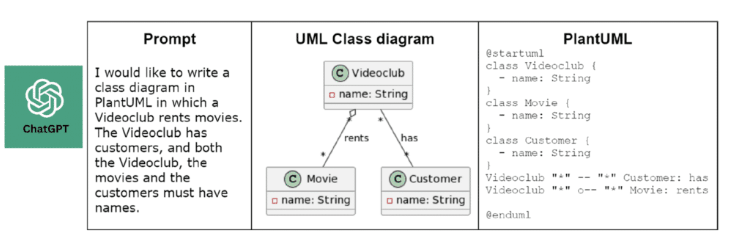
Prompt provided to ChatGPT and UML domain model generated from the prompt.
The size of the models that ChatGPT can handle was another area that we delved into. According to our observations, there are noticeable limitations when it comes to dealing with larger models, with the system struggling to handle models consisting of more than 10–12 classes. This limitation not only affects the accuracy of the models produced but also the time and effort required to generate them.
In addition to these areas of investigation, we analysed the capability of ChatGPT in utilising various modeling concepts and mechanisms, such as Object Constraint Language (OCL) constraints, associations, aggregations and compositions, among others. The findings indicated a high degree of variability in how ChatGPT manages these different concepts, with the system demonstrating reasonable proficiency in some areas but falling short in others.
The study also looked at the impact of prompt variability and different usage strategies on the quality and correctness of the generated models. We observed that the variability in ChatGPT’s responses often necessitates starting conversations anew to obtain better results. Moreover, the limitations in the size of the models that ChatGPT can handle in a single query mean that the modeling process becomes an iterative one, where the modeler must progressively add details to the model.
In conclusion, while we acknowledge the potential of LLMs in revolutionising the field of software development, we also emphasise the need for improvements in terms of consistency, reliability and scalability. By addressing these challenges, we believe that LLMs like ChatGPT can play a prominent role in the future of model-based systems engineering (MBSE), ultimately making software modeling more accessible, personalised and efficient.
Reference:
[1] J. Cámara, J. Troya, L. Burgueño and A. Vallecillo, “On the assessment of generative AI in modeling tasks: an experience report with ChatGPT and UML,” Softw. Syst. Model., vol. 22, no. 3, pp. 781–793, 2023.
Please contact:
Javier Cámara, ITIS Software / Universidad de Málaga, Spain

