









by Gianluigi Folino, Francesco Sergio Pisani (ICAR-CNR) and Carla Otranto Godano (HFactor Security)
In the field of cybersecurity, it is of great interest to analyse user logs in order to prevent data breach issues caused by user behaviour (human factor). A scalable framework based on the Elastic Stack (ELK) to process and store log data coming from digital footprints of different users and from applications is proposed. The system exploits the scalable architecture of ELK by running on top of a Kubernetes platform, and adopts ensemble-based machine learning algorithms to classify user behaviour and to eventually detect anomalies in behaviour.
In recent years, the number of cybersecurity attacks has been increasing and generating ever-larger amounts of data, often compromising computer networks by exploiting user weaknesses. An average organisation is targeted by over 700 social engineering attacks in one year, due to human behaviour [L1]. Often, the detection of these behaviours or of the consequent vulnerabilities happen when the attack has already occurred; on the contrary, a proactive solution, which prevents vulnerabilities from being enabled, is necessary. In addition, in order to operate with the security weaknesses derived from the human factor, a number of critical aspects, such as profiling users for better and more focused actions, analysing large logs in real-time, and working efficiently in the case of missing data, are needed.
According to an industrial report [L2], phishing continues to be the top threat action used in successful breaches (it nearly doubled in frequency from 2019 to 2020) linked to social engineering, with login credentials stolen in 85% of these breaches. However, a security awareness training program can significantly reduce these risks (i.e., from 31.4% to 16.4%, with a limited training period of three months). Analysing user behaviour, to identify homogenous categories or for detecting anomalies, can be a winning strategy to plan a focused training program. However, this task requires processing very large datasets and the sources of user behaviour are heterogeneous and can be missing.
To cope with these issues, a joint collaboration between ICAR-CNR and a cybersecurity startup, HFactor Security [L3], which supplied the ELK-based platform and the data coming from real users, permitted the design of a scalable framework [1]. The framework adopts a distributed ensemble-based evolutionary algorithm [2] to classify the user behaviour and to eventually detect anomalies in their behaviour. The framework (i) operates even with missing sources of data, (ii) works in an incremental way and with streaming data, and (iii) uses a scalable ELK architecture for processing real, large logs.
In more detail, to analyse the user behaviour, three main sources of data are processed: keyboard usage (storing only the zones of the keyboards for privacy reasons), mouse usage (considering only the subarea of the screen in which the user clicks or moves the mouse), and the main application/categories in which the user spends time. These data can be stored in an efficient and scalable architecture, based on a kubernetes ELK cluster, illustrated in Figure 1.

Figure 1: The software architecture of the Kubernetes-based ELK cluster.
On the left of this architecture, a number of agents (installed on the PCs of the users) collect information concerning different sources of information and/or monitoring tools (i.e., generally automatic software analysing the actions and the behaviours of the users). These data are collected and usually stored in log files, which are sent to the cluster by using Filebeat agents.
On the right side of the figure is illustrated the ELK cluster architecture running on top of a Kubernetes platform. The components are Kubernetes Service and they can be replicated to fulfil load demands. The Logstash Service processes the data coming from the Beats agents by applying some specific filtering and transformation rules. Note that the multi-source logs are gathered by Logstash and opportunely grouped into homogenous types (i.e., the data concerning the output of the keyboard or the process usage of the different users). Then, the data are transmitted to the Elastic services that store them on the elastic indexes placed on a persistent volume, managed with a distributed file system.
When these data are stored, the Kibana service and the Model Builder components can have access to this information for visualisation and computation. The flexibility and user-friendly Kibana online data visualisation platform is designed to serve as an end-point for querying and access the amount of user-mined data gathered through the Elasticsearch indexes. Indeed, the latter is responsible of the machine learning tasks, and of ingesting and storing the large-scale data in an automated manner. In addition, the information extracted from the real user logs will be stored for further analysis, i.e., the classification task and the detection in real-time of suspect behaviours and anomalies.
The ML component of the architecture is capable of training and executing classification models to detect anomaly behaviours. The goal is to detect extraneous activities of users belonging to pre-defined group, each one defined as a cluster of users that exhibit the same behaviours. The ML models enrich the collected data, helping the operators to detect and mitigate risk in their organisation. The anomaly detection task was reformulated as a combination of user/group identification tasks, following the principle that the lower the probability that a digital footprint belongs to its corresponding user/group, the more its behaviour is anomalous.
Finally, by using Kibana, the information about these anomalies is processed and plotted with several histograms and charts. In Figure 2, the dashboard showing an example of visualisation of the anomalies, user and group, and the class of risk for a specific time range defined by the Data Protection Officer (DPO) is shown.
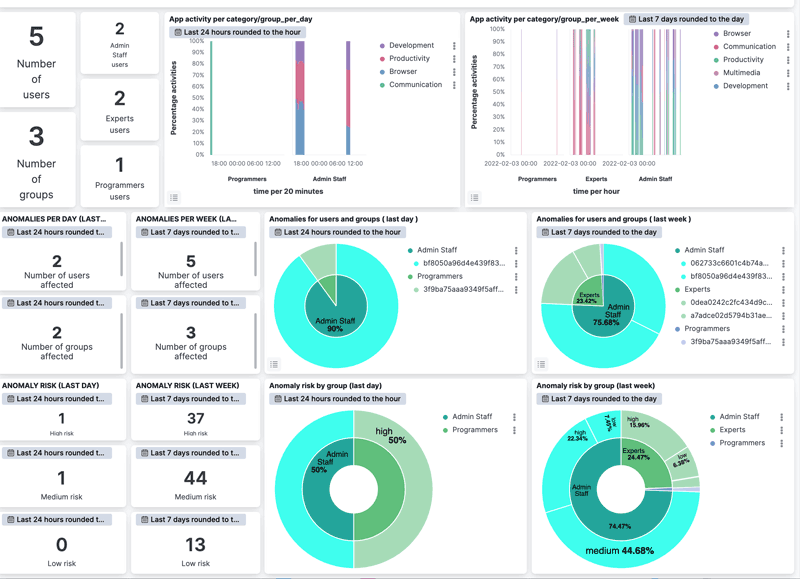
Figure 2: Kibana overview dashboard (anomalies, and class of risk for groups and users).
Experimental results, conducted using a benchmark dataset and real users, show that the framework is effective, even in the case of missing data, in classifying the behaviour of different users and in detecting the anomalies inside the user/group behaviour, with a low number of false alarms. For future works, the solution will be tested on a real scenario with logs coming from many hundreds of real users.
Links:
[L1] https://www.barracuda.com/spearphishing-vol6
[L2] https://info.knowbe4.com/phishing-by-industry-benchmarking-report
[L3] http://www.hfactorsec.com/
References:
[1] G. Folino, C. Otranto Godano, F. S. Pisani: “A Scalable Architecture Exploiting Elastic Stack and Meta Ensemble of Classifiers for Profiling User Behaviour”, 30th Euromicro Int. Conf. on Parallel, Distributed, and Network-Based Processing, IEEE, 2022.
[2] G. Folino, F. S. Pisani: “Evolving Meta-Ensemble of Classifiers for Handling Incomplete and Unbalanced Datasets in the Cyber security Domain”, Applied Soft Computing, Elsevier, pp. 179-190, Vol. 47, October 2016.
Please contact:
Francesco Sergio Pisani and Gianluigi Folino, ICAR-CNR, Italy

