









by Christian Kühnert (Fraunhofer IOSB), Johannes Sailer (Fraunhofer IOSB) and Patrick Weiß (Fraunhofer ICT)
Deep Learning algorithms usually need a large amount of data. Still, when analysing measurements from manufacturing processes, informative data in sufficient quantities is rather rare, making the task more complex. Therefore, the development of so-called few shot learning algorithms, focusing especially on the analysis of small data sets, is one of the current research topics of the Fraunhofer Cluster of Excellence.
Production processes, especially in manufacturing, must meet high standards for quality, efficiency and productivity in order to remain competitive. Owing to increasing process complexity and frequent plant conversions, however, production is often not performed efficiently. One way to increase plant efficiency is a systematic data evaluation, including data management and analysis of historical and streaming process data. For data analysis, machine learning (ML) and artificial intelligence (AI) have undergone rapid development and are currently at the centre of technical innovations. In applications with very large amounts of data available, e.g. in speech recognition or image analysis, deep neural networks are currently the state of the art.
In contrast to image analysis or speech recognition, the use of machine learning methods to analyse production data is a little more complex because even extensive production data often contains comparatively little information. For example, in a plant configured for serial production, process parameters are usually kept constant, leading to the point that always the same data set is delivered. On the other hand, data with a high information content but in small quantities, is generated during commissioning or after major modifications of the plant. An example is the use of new raw material where parameters or process control strategies have to be changed and adapted several times to achieve the desired results.
Hence, one current research topic in the Fraunhofer Cluster of Excellence Machine Learning is to make ML methods applicable for this type of data. ML methods, suitable for small data sets, are referred to as one-shot or few-shot learning and were first presented in 2006 [1]. Recent examples where one-shot learning showed good results are in the area of classifying images [2] and detecting the road profile for autonomous cars [3].
In a current use case, a method called Siamese Network [2] is used to predict the product quality of insulation panels produced on a foam moulding machine. A Siamese network, sketched in Figure 1, is a neural network architecture in which two convolutional neural networks with the same weights work in parallel. Each network takes a different input vector, in this case the process data from two different productions, returning two comparable output vectors. From these two output vectors a distance measure is calculated, making Siamese networks feasible for classification tasks if one of the two input vectors is labelled. To validate the performance of Siamese networks on this type of production data, different recipes were carried out on the moulding machine and the quality of the resulting plates was measured. The resulting insulation plates were evaluated in terms of their welding degree, compressive strength and bending strength and separated into five classes: (1) Good quality, (2) brittle, (3) burned, (4) bent and (5) low compression. In summary, 130 experiments were conducted.
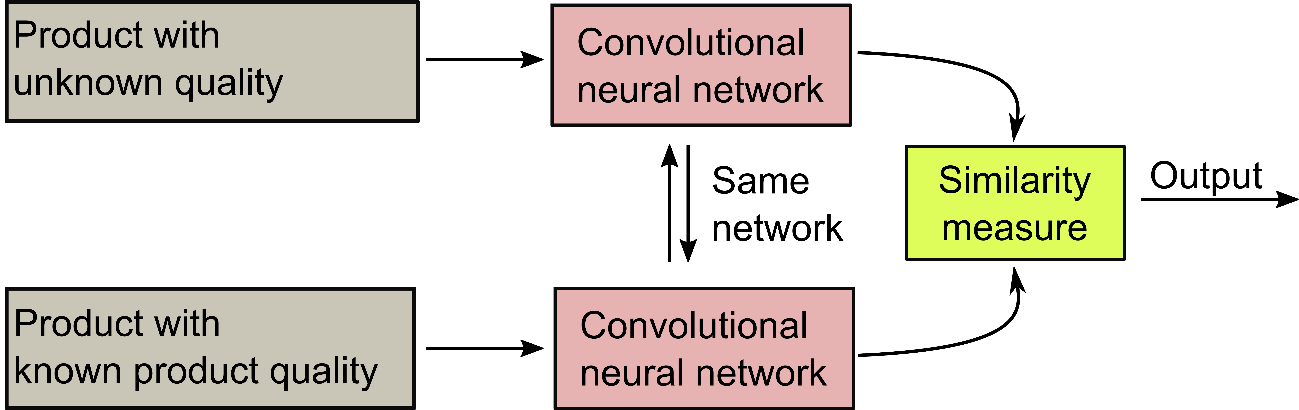
Figure 1: rincipal design of a Siamese Network. Both convolutional neural networks share the same weights. Process data from a product with unknown quality is fed into one network and compared to a product with known quality. Depending on a defined distance measure (e.g. L2-norm) the similarity of the two products is calculated and a prediction of the quality can be made.
As a first step, the Siamese network was tested on the binary problem meaning to classify if a plate is of good or bad quality. For comparison and to validate the performance, a K-Nearest Neighbour algorithm (KNN) was taken as a baseline. Results showed that for the one-shot case, meaning only one good and one bad production was used for training, the Siamese network achieved on the average an accuracy of 83.2 % while the KNN ended up on 80.1 %, meaning the Siamese network outperformed the KNN by about 3 %. When taking the complete data set with a separation of 70 % training and 30 % test data, on average the network ended up with a 97.6 % classification accuracy, outperforming the KNN by about 2%.
For the classification of five classes, the network achieved a decent 52.3 % accuracy for the one-shot problem (keep in mind that 20 % chance would be a random guess) and finishing on an accuracy of 88.7 % for the whole data set. As for the binary case, KNN was outperformed by around 3 %.
In general, the results showed that even for small data sets ML methods are appropriate to analyse process data. Specifically, Siamese networks and the K-Nearest-Neighbour approach already show good results for one-shot learning in the classification of isolation plates for quality control. As expected, in a few-shot scenario, with more data available, the classification accuracy could be substantially increased. In all cases the Siamese network led to a better performance compared to the KNN.
References:
[1] L. Fei-Fei, et.al.: “One-shot learning of object categories”, IEEE transactions on pattern analysis and machine intelligence, 2006
[2] G. Koch, et.al.: “Siamese neural networks for one-shot image recognition.” ICML Deep Learning Workshop, 2015
[3] L. Huafeng et. al.: “Deep Representation Learning for Road Detection through Siamese Network”, Computer Vision and Pattern Recognition, 2019
Please contact:
Christian Kühnert
Fraunhofer IOSB, Germany

