









by Eneko Agirre (UPV/EHU), Sarah Marchand (Synapse Développement), Sophie Rosset (LIMSI), Anselmo Peñas (UNED) and Mark Cieliebak (ZHAW)
Dialogue systems are a crucial component when robots have to interact with humans in natural language. In order to improve these interactions over time, the system needs to be able to learn from its experience, its mistakes and the user’s feedback. This process – fittingly called lifelong learning – is the focus of LIHLITH, an EU project funded by CHIST-ERA.
Artificial Intelligence is a field that is progressing rapidly in many areas, including dialogues with machines and robots. Examples include speaking to a gadget to request simple tasks like turning on the radio or asking for the weather, but also more complex settings where the machine calls a restaurant to make a reservation [L1], or where a robot assists customers in a shop. LIHLITH [L2] is a project focusing on human-machine dialogues. It aims to improve the self-learning capabilities of an artificial intelligence. More specifically, LIHLITH will devise dialogue systems which learn to improve themselves based on their interactions with humans.
LIHLITH (“Learning to Interact with Humans by Lifelong Interaction with Humans”) is a three-year high risk / high impact project funded by CHIST-ERA [L3] that started in January 2018. Participating partners (Figure 1) are researchers from University of the Basque Country (UPV/EHU), Computer Science Laboratory for Mechanics and Engineering Sciences (LIMSI), Universidad Nacional de Educación a Distancia in Spain (UNED), Zurich University of Applied Sciences (ZHAW), and Synapse Développement in France.
Current industrial chatbots are based on rules which need to be hand-crafted carefully for each domain of application. Alternatively, systems based on machine learning use manually annotated data from the domain to train the dialogue system. In both cases, producing rules or training data for each dialogue domain is very time consuming, and limits the quality and widespread adoption of chatbots. In addition, companies need to monitor the performance of the dialogue system after being deployed, and re-engineer it to respond to user needs. Throughout the project, LIHLITH will explore the paradigm of life-long learning in human-machine dialogue systems with the aim of improving their quality, lowering the cost of maintenance, and reducing efforts for deployment in new domains.
Main goal: continuous improvement of dialogue systems
The main goal of life-long learning systems [1] is to continue to learn after being deployed. In the case of LIHLITH, the dialogue system will be developed as usual, but it will include machinery to continue to improve its capabilities based on its interaction with users. The key idea is that dialogues will be designed to get feedback from users, while the system will be designed to learn from this continuous feedback. This will allow the system to keep improving during its lifetime, quickly adapting to domain shifts that occur after deployment.
LIHLITH will focus on goal-driven question-answering dialogues, where the user has an information need and the system will try to satisfy this need as it chats with the user. The project has been structured in three research areas: lifelong learning for dialogue; lifelong learning for knowledge induction and question answering; and evaluation of dialogue improvement. All modules will be designed to learn from available feedback using deep learning techniques.
The goal regarding lifelong learning for dialogue will be to obtain a method to produce a dialogue management module that learns from previous dialogues. The project will explore autonomous reconfiguration of dialogue strategies based on user feedback. We will also give proactive capabilities to the system, which will be used to ask the user for new knowledge and for performance feedback. This will be triggered, for instance, when the past reactions have been rejected, when the user interaction is too ambiguous, when the possible answers are too numerous, or if they have too similar confidence scores.
Regarding knowledge induction and question answering, the goal is to improve the domain knowledge, which includes the representation of utterances and the question answering performance based on the dialogue feedback obtained by the dialogue management module. The representation of utterances and knowledge base will be based on low-dimensional representations. The question answering system will leverage both the information in background texts and domain ontologies. The feedback will be used to provide supervised signal in these learning systems, and thus tune the parameters of the underlying deep learning systems.
Evaluation of dialogue systems is still challenging, with reproducibility and comparability issues. LIHLITH will produce benchmarks for lifelong learning in dialogue systems, which will be applied in an international shared task to explore capabilities of existing solutions. In addition, the research in LIHLITH will be transferred to the industrial dialogue system of Synapse.
To carry out this research, LIHLITH combines machine learning, knowledge representation and linguistic expertise. The project will build on recent advances in a number of research disciplines, including natural language processing, deep learning, knowledge induction, reinforcement learning and dialogue evaluation, to explore their applicability to lifelong learning.
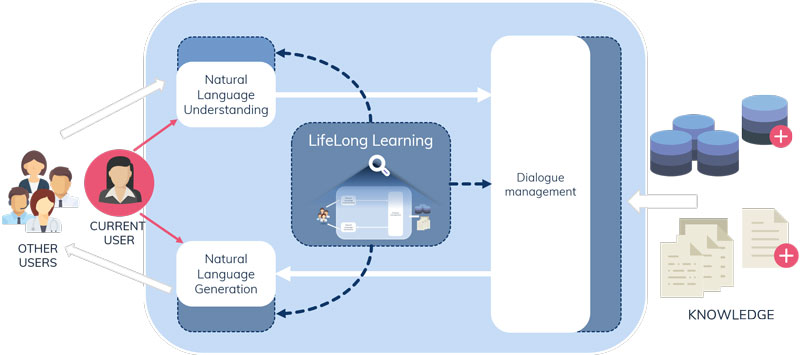
Figure 1: Schema of a standard dialogue system in white boxes. The innovative lifelong learning module is able to improve all modules (in blue) based on past interactions and the interaction with the current user, updating the domain knowledge accordingly.
Links:
[L1] https://kwz.me/htg
[L] http://ixa2.si.ehu.es/lihlith/
[L3] http://www.chistera.eu/
Reference:
[1] Z. Chen and B. Liu. Lifelong Machine Learning. Morgan Clayton. 2016
Please contact:
Eneko Agirre
University of the Basque Country (UPV/EHU), Spain

