









by Alexander Schindler and Sven Schlarb (AIT Austrian Institute of Technolog)
Conversational systems allow us to interact with computational and robotic systems. Such approaches are often deliberately limited to the context of a given task. We apply audio analysis to either broaden or to adaptively set this context based on identified surrounding acoustic scenes or events.
Research on conversational systems dates back to the 1950s when a chatbot called ELIZA was intended to emulate a psycho-therapist. These early systems were generally based on pattern matching where input text messages are mapped to a predefined dictionary of keywords. Using associated response rules, these keywords are mapped to response templates which are used to create the system’s answer. While pattern matching is still one of the most used technologies in chatbots, dialog systems extensively harness advances from research fields which are now associated with the domain of artificial intelligence – in particular, natural language processing tasks such as sentence detection, part of speech tagging, named entity recognition and intent recognition. In these tasks, new approaches based on deep neural networks have shown outstanding improvements. Additional advances in speech recognition systems brought conversational systems into our homes and daily lives with virtual personal assistants such as Amazon Echo, Google Home, Microsoft Cortana and Apple Homepod.
Although these systems are highly optimised to excel as a product, their degree of complexity is limited to simple patterns of user commands. The components of such systems often include: speech recognition (speech to text), natural language processing (NLP), including the sub-tasks part-of-speech detection (PoS), named entity recognition (NER) and recognition of intent, as well as components for dialog management, answer generation and vocalisation (text to speech). Based on the identified intents and involved entities, the dialog manager decides, commonly based on a set of rules, which actions to take (e.g., query for information, execute a task) and uses templates to generate the answer. Recent systems use recurrent neural networks (RNN) to generate sequences of words embedded into a statistical representation of words generated from a large corpus of related question answer pairs. Most state-of-the-art approaches and products are restricted to the context of the intended use-case and the user needs to learn and use a limited vocabulary with a predefined syntax.
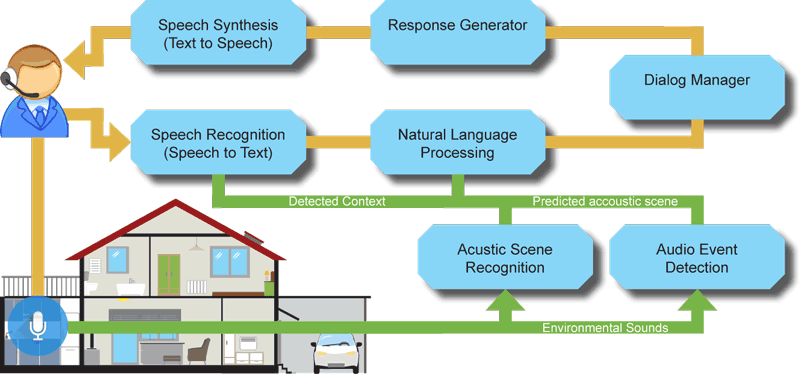
Figure 1: Illustration of the processing pipeline. Predictions of domestic soundscapes and acoustic events are added as contextual information to the conversational workflow. This context directly influences the models for speech recognition and the semantic interpretation of recognized words.
Beyond voice commands
To enable a system to interact with its environment – especially in human robot interaction (HRI) for the purposes of entertainment, teaching, comfort and assistance – reacting to voice commands is not sufficient. Conversational commands are frequently related to environmental events and the execution of tasks may depend on environmental states. Thus, we research combined multi-modal approaches to conversational systems where we add audio analysis to the language processing stack.
We analyse the surrounding acoustic scene to add this information as context to the conversational system. We apply a custom neural network architecture using parallel stacks of Convolutional Neural Network (CNN) layers which captures timbral and rhythmic patterns and adapts well to small datasets [1]. These models were developed and evaluated in the context of the annual evaluation campaign Detection and Classification of Acoustic Scenes and Events (DCASE). By identifying acoustic scenes such as Home, Office, Kitchen, Bathroom or Restaurant, the semantic scope of the conversational system can be adaptively reduced to the environmental context. Additionally we apply audio event detection to identify acoustic events such as our task leading contribution to domestic audio tagging (DCASE 2016) to identify acoustic events such as child or adult/male/ female speech, percussive sound (e.g., knock, footsteps) but also Page Turning to assess the presence of individuals.
This research was successfully applied in cultural heritage projects Europeana Sounds [L1] as well as the security related projects FLORIDA [L2], VICTORIA [L3] to identify acoustic events such as gunshots or explosions. Our work on natural language processing will be applied and extended in the upcoming security related project COPKIT (H2020). For future work we intend to further extend the range of contexts to our other research tasks such as identifying environmental acoustic events [2] or emotion expressed by music or speakers [3]. Finally we intend to extend this approach to include further modalities based on our experience in audio-visual analytics [4] to provide even more contextual input.
Links:
[L1] http://www.eusounds.eu/
[L2] http://www.florida-project.de/
[L3] https://www.victoria-project.eu/
References:
[1] A. Schindler, T. Lidy and A. Rauber: “Multi-Temporal Resolution Convolutional Neural Networks for Acoustic Scene Classification”, in Proc. of DCASE 2017, 2017.
[2] B. Fazekas, et al: “A multi-modal deep neural network approach to bird-song identification”, LifeCLEF 2017 working notes, Dublin, Ireland
[3] T. Lidy and A. Schindler: “Parallel convolutional neural networks for music genre and mood classification”, Technical report, MIREX 2016, 2016.
[4] A. Schindler and A. Rauber: “Harnessing Music related Visual Stereotypes for Music Information Retrieval”, ACM Transactions on Intelligent Systems and Technology (TIST) 8.2 (2016): 20.
Please contact:
Alexander Schindler
AIT Austrian Institute of Technology
Sven Schlarb
AIT Austrian Institute of Technology

