









by Michele Dolfi, Christoph Auer, Peter W J Staar and Costas Bekas (IBM Research Zurich)
Over recent decades, the number of scientific articles and technical publications have been increasing exponentially, and as a consequence there is a great need for systems that can ingest these documents at scale and make their content discoverable. Unfortunately, both the format of these documents (e.g. the PDF format or bitmap images) as well as the presentation of the data (e.g. complex tables) make the extraction of qualitative and quantitative data extremely challenging. We have developed a platform to ingest documents at scale which is powered by machine learning techniques and allows the user to train custom models on document collections.
There are roughly 2.5 trillion PDFs in circulation, such as scientific publications, manuals, reports, contracts and more. However, content encoded in PDF is by its nature reduced to streams of printing instructions purposed to faithfully present a visual layout. The task of automatic content reconstruction and conversion of PDF documents into structured data files has been an outstanding problem for over three decades. We have developed a solution to the problem of document conversion, which at its core, uses trainable, machine learning algorithms. The central idea is that we avoid heuristic or rule-based conversion algorithms, using instead generic machine learning algorithms, which produce models based on gathered ground-truth data. In this way, we eliminate the continuous tweaking of conversion rules and let the solution simply learn how to correctly convert documents by providing enough training data. This approach is in stark contrast to current state-of-the-art conversion systems (both open-source and proprietary), which are all rule-based.
While a machine learning approach might appear very natural in the current era of AI, it has serious consequences with regard to the design of such a solution. First, one should think at the level of a whole document collection (or a corpus of documents) as opposed to individual documents, since an ML model for a single document is not very useful. Second, one needs efficient tools to gather ground-truth via human annotation. These annotations can then be used to train the ML models. Hence, one has to provide the ability to store a collection of documents, annotate these documents, store the annotations, train models and ultimately apply these models to unseen documents. This implies that our solution cannot be a monolithic application, rather it was built as a cloud-based platform, which consists of micro-services that execute the previously mentioned tasks in an efficient and scalable way. We call this platform Corpus Conversion Service (CCS).
Using a micro-services architecture, the CCS platform implements the pipeline depicted in Figure 1. The micro-services are grouped into five components: (1) the parsing of documents, (2) applying the ML model(s), (3) assembling the document(s) into a structured data format, and additionally it provides the (optional) lower branch which allows (4) annotating the parsed documents and (5) training the models from these annotations. If a trained model is available, only the first three components are needed to convert the documents.
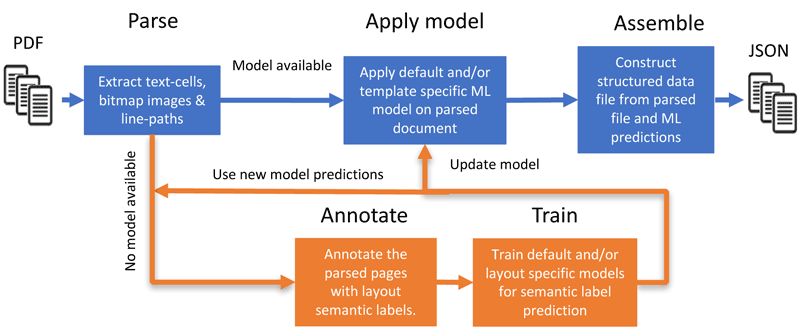
Figure 1: A sketch of the Corpus Conversion Service platform for document conversion. The main conversion pipeline is depicted in blue and allows you to process and convert documents at scale into a structured data format. The orange section is (optionally) used for training new models based on human annotation.
In the parsing phase of the pipeline, we focus on the following straightforward but non-trivial task: Find the bounding boxes of all text-snippets (named cells) that appear on each pdf-page. In Figure 2 we show the cells obtained from the title-page of a paper. The job of the subsequent components is to associate certain semantic classes (called labels) to these cells, e.g. we want to identify the cells that belong to the same paragraph, or that constitute a table. More examples of labels are: Title, Abstract, Authors, Subtitle, Text, Table, Figure, etc.
Figure 2: The annotated cells obtained for a published paper. Here, the title, authors, affiliation, subtitle, main-text, caption and picture labels are represented respectively as red, green, purple, dark-red, yellow, orange and ivory.
The annotation and training components are what differentiates our method from traditional, rule-based document conversion solutions. They allow the user to obtain a highly accurate and very customisable output, for instance some users want to identify authors and affiliations, whilst others will discard these labels.
This level of customisation is obtained thanks to the possibility of enriching the ML models by introducing custom human annotations in the training set. The page annotator visualises one PDF page at the time on which the (human) annotator is requested to paint the text cells with the colour representing a certain label. This is a visual and very intuitive task; hence it is suited for large annotation campaigns that can be performed by non-qualified personnel. Various campaigns have demonstrated that the average annotation time per document was reduced by at least one order of magnitude, corresponding to a ground-truth annotation rate of 30 pages per minute.
Once enough ground-truth has been collected, one can train ML models on the CCS platform. We have the ability to train two types of models: default models, which use state-of-the-art deep neural networks [1, 2] and customised models using random forest [3] in combination with the default models. The aim of the default models is to detect objects on the page such as tables, images, formulas, etc. The customised ML models are classification models, which assign/predict a label for each cell on the page. In these customised models, we typically use the predictions of the default models as additional features to our annotation-derived features.
The approach taken for the CCS platform has proven to scale in a cloud environment and to provide accuracies above 98 % with a very limited number of annotated pages. Further details on the cloud architecture and the ML models are available in our paper for the ACM KDD’18 conference [4].
Link:
https://www.zurich.ibm.com
References:
[1] Ross Girshick, Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV) (ICCV ‘15). IEEE Computer Society, Washington, DC, USA, 1440–1448, 2015. https://doi.org/10.1109/ICCV.2015.169
[2] Joseph Redmon, et al., You Only Look Once: Unified, Real-Time Object Detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016), 779–788, 2016.
[3] Leo Breiman, Random Forests. In Machine Learning 45, 1 (01 Oct 2001), 5–32, 2001. https://doi.org/10.1023/A:1010933404324
[4] P. Staar et al., Corpus Conversion Service: A machine learning platform to ingest documents at scale. In KDD ‘18, ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018. https://doi.org/10.1145/3219819.3219834
Please contact:
Michele Dolfi, IBM Research Zurich, Switzerland

