









by Matteo Abrate, Angelica Lo Duca, Andrea Marchetti (IIT-CNR)
The “Clavius on the Web Project” [L1] is an initiative involving the National Research Council in Pisa and the Historical Archives of the Pontifical University in Rome. The project aims to create a web platform for the input, analysis and visualisation of digital objects, i.e., letters sent to Christopher Clavius, a famous scientist of the 17th Century.
In the field of digital humanities, cultural assets can be valued and preserved at different levels, and whether or not an object is considered a knowledge resource depends on its peculiarity and richness. Within the Clavius on the Web Project we mainly consider two kinds of knowledge resources: contextual resources associated to digitised documents and manual annotations of cultural assets. We implemented a different software for each of these resource types: the Web Metadata Editor for contextual resources and the Knowledge Atlas to support manual annotation.
Semi-automated enrichment of catalogues: the Web Metadata Editor
In recent years, a great effort has been made within the field of digital humanities to digitise documents and catalogues in different formats, such as PDF, XML, plain texts and images. These documents are often stored either in digital libraries or big digital repositories in the form of books and catalogues. The process of cataloguing also requires the creation of a knowledge base, which contains contextual resources associated to documents of the catalogue, such as the authors of the documents and places where documents were written. Information contained in the knowledge base can be used to enrich document details, such as metadata associated to documents. Most of the existing tools for catalogue creation allow the knowledge base to be built manually. This process is often tedious, because it requires known information about a document, such as the author’s name and date of birth, to be edited. It is also a repetitive process because many documents are written by the same author and in the same place thus requiring the same information to be written twice or more. In general there are three main disadvantages of this manual effort, compared to an automated system: (i) there is a higher probability of introducing errors; (ii) the process is slower; (iii) the entered information is isolated, i.e., not connected to the rest of the web.
In order to mitigate these disadvantages in the context of the project, we developed the Web Metadata Editor (WeME) [1], a user-friendly web application for building a knowledge base associated to a catalogue of digital documents. Figure 1 shows a snapshot of WeME. While the application is envisaged for archivists/librarians, it may also be useful for others. WeME helps archivists to enrich their catalogues with resources extracted from two kinds of web sources: Linked Data (DBpedia GeoNames) and traditional web sources (VIAF).

Figure 1: A snapshot of WeME.
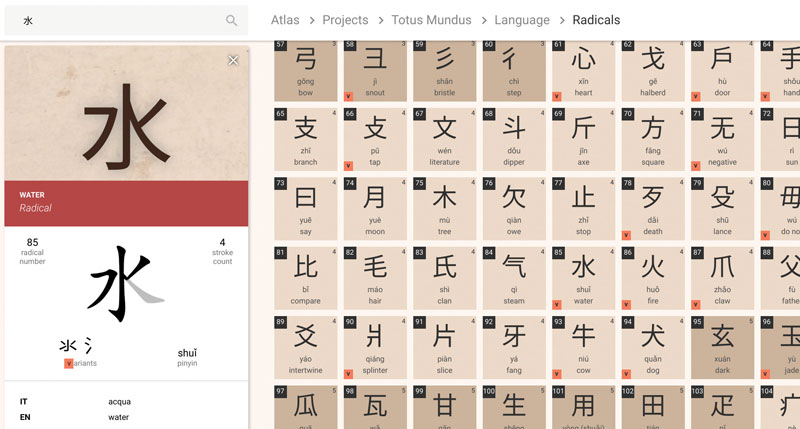
Figure 2: A screenshot of Knowledge Atlas showing information about a Chinese radical.
WeME, which is published as an open source software on GitHub [L2], was tested by 31 users, 45.2% of whom were female and 54.8% male. Almost half (48.8%) of the testers were older than 35 years. In a scale ranging from poor (1) to excellent (5), the scores given to WeME were: 4 (by 50% of testers), 5 (by 20%), 3 (by 23.3%) and 1 or 2 by the remaining testers. Tests indicate that WeME is a promising solution for reducing the repetitive, often tedious work of archivists.
Visual exploration of knowledge: Knowledge Atlas
Creating a catalogue and digitising assets from the archive, while fundamental, soon proved insufficient to convey the richness of the knowledge within the archive. We thus started the development of Knowledge Atlas [L3], a user interface designed with the following principles:
- Visualisation and interaction – Content presentation should take advantage of the visual expressiveness and interactivity of modern web technologies. For example, the interactive recreation of volvellae, instruments made of rotating wheels of paper, which enables scholars to investigate their purpose without risking damage to the original artefacts.
- Depth and detail – Content presentation should explicitly show many different layers of analysis and highlight interesting points. For example, a representation of the Kunyu Wanguo Quantu Chinese map is displayed with highlighted toponyms and cartouches, with which the user can interact to read Chinese transcriptions and Italian translations. Each text can then be further explored to access information about specific Chinese graphemes (Figure 2).
- Context and links – The main content should be complemented with contextual information. Such presentations should enable navigation from content to context and vice versa. For example, senders, recipients and cited historical characters related to the figure of Christophorus Clavius [2] constitute a graph of correspondents, which can be navigated by itself or starting from a specific passage of a letter. Other examples include: the set of evolving mathematical or astronomical conceptualisations and the related lexical terms in Latin, Italian or Greek [3].
- Divulgation and correctness – The presentation of content should feature specific design choices aimed at capturing the attention of students or casual readers, by leveraging powerful visual languages and a systematic organisation. The power of providing a structured and intuitive overview should be used as a gateway to lead to the most complete and correct information available. As an example, the representation of the context of the aforementioned letters by Galilei about the model of our solar system is a visual diagram making use of a distorted scale. The actual distances and sizes of the objects can be appreciated by accessing detailed data.
Our current platform, in active and open development on Github, implements this design without being too tied to the specificity of the content. By following this methodology, we believe that our software will prove to be useful in contexts beyond the projects discussed here. We are already experimenting with other content, such as more maps, books, and paintings, but also with models of buildings and complex structured data about the internet.
Links:
[L1] http://claviusontheweb.it
[L2] https://kwz.me/hkj
[L3] http://atlasofknowledge.it
References:
[1] A. Lo Duca et. al.: “Web Metadata Editor: a Web Application to Build a Knowledge Base Based on Linked Data”, Third Int. Workshop on Semantic Web for Scientific Heritage, Portoroz, Slovenia, 2017.
[2] M. Abrate et al.: “The Clavius on the Web Project: Digitization, Annotation and Visualization of Early Modern Manuscripts”, AIUCD Annual Conference, 2014.
[3] S.Piccini et al.: “When Traditional Ontologies are not Enough: Modelling and Visualizing Dynamic Ontologies in Semantic-Based Access to Texts”, DH 2016.
Please contact
Andrea Marchetti, IIT-CNR, Italy

