









by Achille Felicetti (Università degli Studi di Firenze)
Natural language processing and machine learning technologies have acquired considerable importance, especially in disciplines where the main information is contained in free text documents rather than in relational databases. TEXTCROWD is an advanced cloud based tool developed within the framework of EOSCpilot project for processing textual archaeological reports. The tool has been boosted and made capable of browsing big online knowledge repositories, educating itself on demand and used for producing semantic metadata ready to be integrated with information coming from different domains, to establish an advanced machine learning scenario.
In recent years, great interest has arisen around the new technologies related to natural language processing and machine learning, which have suddenly acquired considerable importance, especially in disciplines such as archaeology, where the main information is contained in free text documents rather than in relational databases or other structured datasets [1]. Recently, the Venice Time Machine project [L1], aimed at (re)writing the history of the city by means of “stories automatically extracted from ancient manuscripts”, has greatly contributed to feeding this interest and rendering it topical.
Reading the documents: machines and the “gift of tongues”
The dream of having machines capable of reading a text and understanding its innermost meaning is as old as computer science itself. Its realisation would mean acquiring information formerly inaccessible or hard to access, and this would tremendously benefit the knowledge bases of many disciplines. Today there are powerful tools capable of reading a text and deciphering its linguistic structure. They can work with most major world languages to perform complex operations, including language detection, parts of speech (POS) recognition and tagging, and grasping grammatical, syntactic and logical relationships. To a certain extent, they can also speculate, in very general terms, on the meaning of each single word (e.g., whether a noun refers to a person, a place or an event). Named entities resolution (NER) and disambiguation techniques are the ultimate borderline of NLP, beyond which we can start to glimpse the actual possibility of making the machines aware of the meaning of a text.
Searching for meanings: asking the rest of the world
However, at present no tool is capable of carrying out NER operations on a text without adequate (and intense!) training. This is because tools have no previous knowledge of the context in which they operate unless a human instructs them. Usually, each NLP tool can be trained for a specific domain by feeding it hundreds of specific terms and concepts from annotated documents, thesauri, vocabularies and other linguistic resources available for that domain. Once this training is over, the tool is fully operational, but it remains practically unusable in other contexts unless a new training pipeline is applied. Fortunately, this situation is about to change thanks to the web, big data and the cloud, which offer a rich base of resources in order to overcome this limitation: services like BabelNet [L2] and OpenNER [L3] are large online aggregators of entities that provide immense quantities of named entities ready to be processed by linguistic tools in a cloud context. NLP tools, once deployed as cloud services, will be able to tune into a widely distributed and easily accessible resource network, thus reducing the training needs and making the mechanism flexible and performant.
TEXTCROWD and the European Open Science Cloud
The above is what TEXTCROWD [L4] seeks to achieve. TEXTCROWD is one of the pilot tools developed under EOSCpilot [L5], an initiative aimed “to develop a number of demonstrators working as high-profile pilots that integrate services and infrastructures to show interoperability and its benefits in a number of scientific domains, including archaeology”. The pilot developed by VAST-LAB/PIN (University of Florence, Prato) under the coordination of Franco Niccolucci and in collaboration with the University of South Wales, is intended to build a cloud service capable of reading excavation reports, recognising relevant archaeological entities and linking them to each other on linguistic bases [2]. TEXTCROWD was initially trained on a set of vocabularies and a corpus of archaeological excavation reports (Figure 1). Subsequently, thanks to the cloud technology on which it is built, it has been made capable of browsing all the major online NER archives, which means it can also discover entities “out of the corpus” (i.e., non-archaeological ones) and educate itself on demand so that it can be employed in different domains in an advanced machine learning scenario (Figure 2). Another important feature concerns the output produced by the tool: TEXTCROWD is actually able to generate metadata encoding the knowledge extracted from the documents into a language understandable by a machine, an actual “translation” from a (natural) language to another (artificial) one. The syntax and semantics of the latter are provided by one of the main ontologies developed for the cultural heritage domain: CIDOC CRM [L6], an international standard that is very popular in digital humanities.
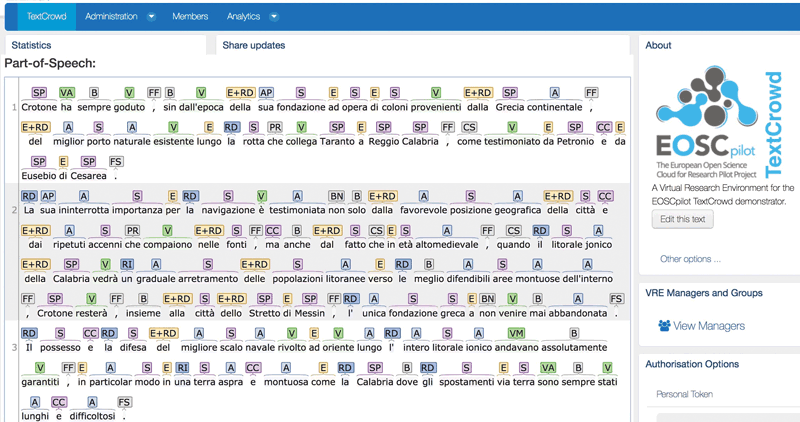
Figure 1: Part-of-speech recognition in TEXTCROWD using OpenNER framework.
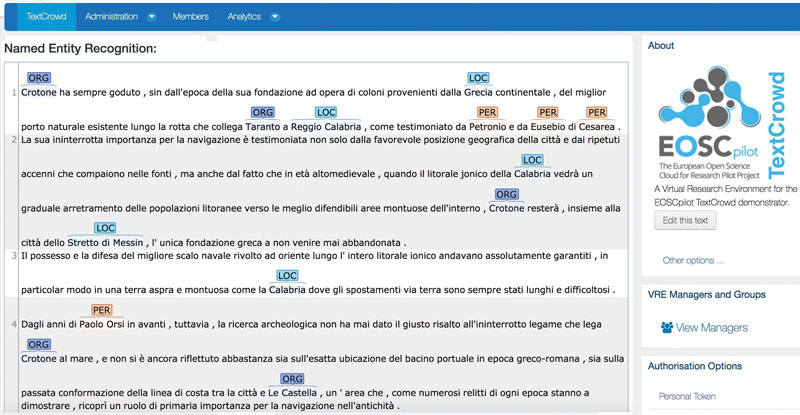 Figure 2: Named entities resolution in TEXTCROWD using DBPedia and BabelNet resources.
Figure 2: Named entities resolution in TEXTCROWD using DBPedia and BabelNet resources.
“Tell me what you have understood”
CIDOC CRM provides classes and relationships to build discourses in a formal language by means of an elegant syntax and to tell stories about the real world and its elements. In TEXTCROWD, CIDOC CRM has been used to “transcribe”, in a format readable by a machine, narratives derived from texts, narrating, for instance: the finding of an object at a given place or during a given excavation; the description of archaeological artefacts and monuments, and the reconstructive hypotheses elaborated by archaeologists after data analysis [3]. CIDOC CRM supports the encoding of such narratives in standard RDF format, allowing, at the end of the process, the production of machine-consumable stories ready for integration with other semantic knowledge bases, such as the archaeological data cloud built by ARIADNE [L7]. The dream is about to become reality, with machines reading textual documents, extracting content and making it understandable to other machines, in preparation for the digital libraries of the future.
Links:
[L1] timemachineproject.eu
[L2] babelnet.org/
[L3] www.opener-project.eu/
[L4] eoscpilot.eu/science-demos/textcrowd
[L5] eoscpilot.eu
[L6] http://cidoc-crm.org
[L7] http://ariadne-infrastructure.eu
References:
[1] F. Niccolucci et al.: “Managing Full-Text Excavation Data with Semantic Tools”, VAST 2009. The 10th International Symposium on Virtual Reality, Archaeology and Cultural Heritage, 2009.
[2] A. Vlachidis et al.: “Excavating Grey Literature: a case study on the rich indexing of archaeological documents via Natural Language Processing techniques and Knowledge Based resources”. ASLIB Proceedings Journal, 2010.
[3] A. Felicetti, F. Murano: “Scripta manent: a CIDOC CRM semiotic reading of ancient texts”, International Journal on Digital Libraries, Springer, 2016.
Please contact:
Achille Felicetti, VAST-LAB, PIN, Università degli Studi di Firenze, Italy
+39 0574 602578

