









by Evaggelia Pitoura (University of Ioannina), Irini Fundulaki (FORTH) and Serge Abiteboul (Inria & ENS Cachan)
Bias in online information has recently become a pressing issue, with search engines, social networks and recommendation services being accused of exhibiting some form of bias. Here, we make the case for a systematic approach towards measuring bias. To this end, we outline the necessary components for realising a system for measuring bias in online information, and we highlight the related research challenges.
We live in an information age where the majority of our diverse information needs are satisfied online by search engines, social networks, e-shops, and other online information providers (OIPs). For every request we submit, a combination of sophisticated algorithms return the most relevant results tailored to our profile. These results play an important role in guiding our decisions (e.g., what should I buy), in shaping our opinions (e.g., who should I vote for), and in general in our view of the world.
Undoubtedly, although the various OIPs have helped us in managing and exploiting the available information, they have limited our information seeking abilities, rendering us overly dependent on them. We have come to accept such results as the “de facto” truth, immersed in the echo chambers and filter bubbles created by personalisation, rarely wondering whether the returned results represent a full range of viewpoints. Further, there are increasingly frequent reports of OIPs exhibiting some form of bias. In the recent US presidential elections, Google was accused of being biased against Donald Trump [L1] and Facebook of contributing to the post-truth politics [L2]. Google search has been accused of being sexist or racist when returning images for queries such as “nurse” [L3]. Similar accusations have been made for Flickr, Airbnb and LinkedIn.
The problem has attracted some attention in the data management community [1, 2], and is also considered a high-priority problem for machine learning algorithms [3] and AI [L4]. Here we focus on the very first step, that of defining and measuring bias, by proposing a systematic approach for addressing the problem of bias in online information. According to the Oxford English Dictionary [L5], bias is “an inclination or prejudice for or against one person or group, especially in a way considered to be unfair”, and as “a concentration on or interest in one particular area or subject”.
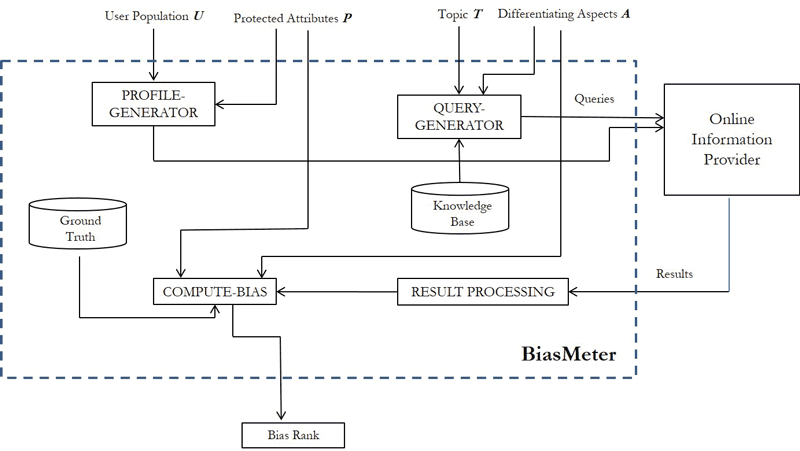
Figure 1: System Components of BiasMeter.
When it comes to bias in OIPs, we make the distinction between subject bias and object bias. Subject bias refers to bias towards the users that receive a result, and it appears when different users receive different content based on user attributes that should be protected, such as gender, race, ethnicity, or religion. On the other hand, object bias refers to biases in the content of the results for a topic (e.g., USA elections), that appears when a differentiating aspect of the topic (e.g., political party) is disproportionately represented in the results.
Let us now describe the architecture and the basic components of the proposed system BiasMeter. We treat the OIP as a black-box, accessed only through its provided interface, e.g., search queries. BiasMeter takes as input: (i) the user population U for which we want to measure the (subject) bias; (ii) the set P of the protected attributes of U; (iii) the topic T for which we want to test the (object) bias; and (iv) the set A of the differentiating aspects of the topic T. We assume that the protected attributes P of the user population and the differentiating aspects A of the topic are given as input (a more daunting task would be to infer these attributes).
Given the topic T and the differentiating aspects A, the goal of the Query Generator (supported by a knowledge base) is to produce an appropriate set of queries to be fed to OIP that best represent the topic and its aspects. The Profile Generator takes as input the user population U and the set of protected attributes P, and produces a set of user profiles appropriate for testing whether the OIP discriminates over users in U based on the protected attributes in P (e.g., gender). The Result Processing component takes as input the results from the OIP and applies machine learning and data mining algorithms such as topic modelling and opinion mining to determine the value of the differentiating aspects (e.g., if a result takes a positive stand). Central to the system is the Ground Truth module, but obtaining the ground truth is hard in practice. Finally, the Compute Bias component calculates the bias of the OIP based on the subject and object bias metrics and the ground-truth.
Since bias is multifaceted, it might be difficult to quantify it. In [L6] we propose some subject and object bias metrics. Further, obtaining the ground truth and the user population are some of the most formidable tasks in measuring bias, since it is difficult to find objective evaluators and generate large samples of user accounts for the different protected attributes. Also there are many engineering and technical challenges for the query generation and result processing components that involve knowledge representation, data integration, entity detection and resolution, sentiment detection, etc. Finally, it might be in the interest of governments to create legislation that provides access to sufficient data for measuring bias, since access to the internals of OIPs is not provided.
Links:
[L1] https://kwz.me/hLc
[L2] https://kwz.me/hLy
[L3] https://kwz.me/hLH
[L4] https://futureoflife.org/ai-principles/
[L5] https://en.oxforddictionaries.com/definition/bias
[L6] http://arxiv.org/abs/1704.05730
References:
[1] J. Stoyanovich, S. Abiteboul, and G. Miklau. Data, responsibly: Fairness, neutrality and transparency in data analysis. In EDBT, 2016.
[2] J. Kulshrestha, M. Eslami, J. Messias, M. B. Zafar, S. Ghosh, I. Shibpur, I. K. P. Gummadi, and K. Karahalios. Quantifying search bias: Investigating sources of bias for political searches in social media. In CSCW, 2017.
[3] M. B. Zafar, I. Valera, M. G. Rodriguez, and K. P. Gummadi. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In WWW, 2017.
Please contact:
Irini Fundulaki, ICS-FORTH, Greece,

