









by Savvina Daniil and Laura Hollink (CWI)
Online book recommender systems are known to propagate biases that historically exist in the book market, such as unfair treatment of authors based on their sensitive characteristics. At CWI, we study the challenges that researchers face in measuring and reporting on bias, by conducting extensive experimentation and exploring the gap between theory and practice.
Recommender systems is one of the AI applications that we interact the most with in our online journeys. From music, film and streaming, to news and social media posts, one thing is common: platforms attempt to improve user experience by automatically recommending content. Even public organizations such as libraries, where traditionally the content is curated, face challenges when users expect personalization in their online tools to support them when navigating the ever expanding information space.
Other than technical requirements that are always evolving, public organizations have to be mindful of potential negative consequences of training recommender systems on user-item interactions, such as bias. Bias refers to recommender models’ tendency to find shortcuts and misinterpret the training data, and can lead to reinforcing stereotypes, malfunctioning for certain groups of people, recommending only items that are already well-known, and other effects. Bias is a valid concern in the context of library recommender systems, given known prejudices and unfair practices in the book market.
At the Human-Centered Data Analytics [L1] group of CWI and the Cultural AI Lab [L2], we wish to support KB, the National Library of the Netherlands, in their effort to adopt personalization while accounting for bias in their data. To this end, we evaluate bias propagated by frequently used recommender systems algorithms. We are specifically interested in popularity bias, the phenomenon where items that have been consumed by many users in the training data might be over-recommended and have their popularity further increase, regardless if the users actually liked them. Additionally, we pose that, given historically present biases, popularity is not random and might coincide with author sensitive characteristics such as gender, age, or nationality. In such cases, even if the system does not receive said characteristics as input, it will still over or under-recommend authors from a certain group as a direct result of popularity bias. For example, we found that in a benchmark dataset with book ratings American authors are over-represented, especially among the popular books. After preprocessing the dataset and training a set of collaborative filtering algorithms, we noticed that algorithms that propagate popularity bias also over-recommend American authors, as seen in Figure 1 [1].
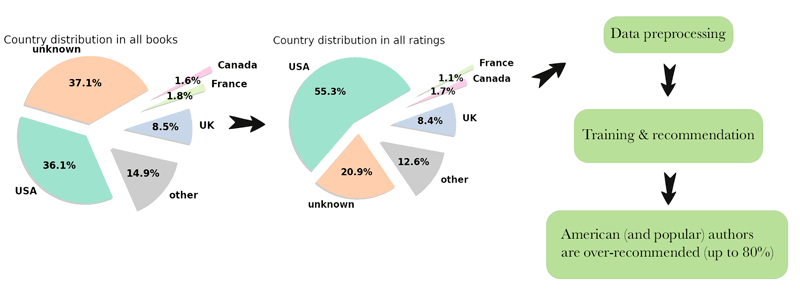
Figure 1: At CWI, we found American authors to be over-represented in a benchmark dataset with book ratings, especially among the popular books. After processing the dataset and training a set of collaborative filtering algorithms, some of them recommended up to 80% American authors.
In this process, we notice a set of challenges. For one, bias is a complex term, and while it is somewhat standardized when it comes to recommender systems, there are still critical decisions to make when measuring it. Given the inherently application-based character of recommendation, building on the rich output of library and information science can provide guidance in these decisions. Bridging theoretical and applied studies, while necessary, is ambitious. Differences such as divergent terminology obfuscate the process of accessing the right material from outside one’s field: when computer scientists say ‘bias’, library and information scientists may say ‘unjust treatment’, ‘marginalization’, ‘erasure’ etc. For this reason, bias in book recommender systems research often lacks strong theoretical background, continuity, and even applicability in the real world. We are currently working on a survey paper in book recommendation that highlights this issue.
Another challenge with estimating bias is the dependence of the result on design and implementation details that often go unnoticed in research. The field of recommender systems is known to suffer from reproducibility issues, which also harm continuity. In our extensive reproduction work, we evaluated popularity bias propagation by a set of collaborative filtering methods such as Nearest Neighbor-based, Matrix Factorization, and Neural Network-based. We found that studies that measure popularity bias in different domains and attempt to reproduce each other adopt different evaluation strategies that ultimately lead to divergence in reported bias [2]. In addition to evaluation strategy, through data synthesis and simulation we found that implicit dataset properties interact with algorithm configurations that differ between widely used recommender systems frameworks and produce different conclusions regarding whether an algorithm or dataset is prone to exhibiting popularity bias [3]. We conclude that researchers have to be careful when simulating a system, as well as be specific and avoid generalized conclusions outside the boundaries of their studies.
Bias estimation is a valuable and necessary step in the development and adoption of complex learning-based systems. As a next step, we intend to move on from simulations and benchmark datasets to evaluating bias in the loaning patterns of users of the public libraries in the Netherlands and Denmark, in collaboration with DBC Digital. We hope that the knowledge we’ve built will support the effort for effective communication and interdisciplinary dialogue between researchers and library practitioners to ensure that AI systems benefit society.
Links:
[L1] https://kwz.me/hxy
[L2] https://www.cultural-ai.nl/
References:
[1] S. Daniil, et al., “Hidden author bias in book recommendation,” arXiv preprint arXiv:2209.00371, 2022.
[2] S. Daniil, et al., “Reproducing popularity bias in recommendation: The effect of evaluation strategies,” ACM Transactions on Recommender Systems, vol. 2, no. 1, pp. 1–39, 2024.
[3] S. Daniil, et al., “On the challenges of studying bias in Recommender Systems: The effect of data characteristics and algorithm configuration,” Information Retrieval Research, vol. 1, no. 1, pp. 3–27, 2025.
Please contact:
Savvina Daniil, CWI, The Netherlands
Laura Hollink, CWI, The Netherlands

