









by Giovanni Puccetti (CNR-ISTI), Vincenzo Roberto Imperia (University of Palermo), and Andrea Esuli (CNR-ISTI)
An interdisciplinary project leverages AI to automatically annotate legal references in the Liber Extra’s Ordinary Gloss, creating a valuable index for researchers in Legal History and Religious Studies. Using efficient machine learning techniques, we achieved near-perfect accuracy in automatically identifying and linking thousands of legal references. The resulting open-source workflow offers a replicable solution for similar tasks in the humanities.
The study of medieval legal texts, such as the Liber Extra’s Ordinary Gloss [1], is crucial for understanding the evolution of legal and religious thought. These texts contain “allegationes”, legal references, i.e., link to a norm that support the interpretation of another norm, that form the backbone of medieval legal argumentation. Manually annotating these references is a labor-intensive process, requiring highly specialised domain expertise and significant time. In this context we proved that machine learning can provide a scalable and efficient solution, enabling the automatic extraction and annotation of these references with high accuracy.
This project [3], part of the ITSERR initiative [L1], developed an automatic annotation system for legal references in the Liber Extra’s Ordinary Gloss. The Liber Extra, a cornerstone of medieval canon law, is accompanied by the Glossa Ordinaria, a commentary that includes thousands of legal references. These references are essential for understanding the interpretative framework of the text but are challenging to navigate due to their volume and complexity. By combining expert manual annotation with machine learning, we created an index of 41,784 legal references, linking each to specific lemmas, chapters, and titles in the Liber Extra.
The process began with a domain expert annotating a subset of the text using INCEpTION [2], a collaborative annotation platform designed for efficient text annotation. The expert annotated 12 out of 185 titles, resulting in 4,578 annotations. These annotations served as the training data for a machine learning model, which was then applied to the entire text.
We tested two machine learning approaches: Conditional Random Fields (CRF), a traditional statistical method, and transformer-based models such as BERT and Latin BERT. CRF models, which excel at sequence labelling tasks, achieved 97.8% accuracy in identifying legal references, outperforming the transformer-based models. The CRF model’s success can be attributed to its ability to capture the contextual dependencies in the text, such as the specific abbreviations and numbering conventions used in medieval legal citations. In contrast, while Latin BERT performed better than the original BERT due to its specialisation in Latin, it still fell short (-5.4%) of the CRF model’s accuracy.
The CRF model’s efficiency was another advantage. CRF uses the CPU of a desktop computer for training, making it accessible to small research teams with limited computational resources. In contrast, training transformer-based models demanded significant – and much more costly - GPU resources, highlighting the practicality of CRF for similar projects in the humanities. Another term of comparison in favor of CRF is the size of the trained model, which is just 1 MB for CRF compared to the 423 MB of Latin BERT.
Once trained, the CRF model was used to annotate the entire Liber Extra’s Ordinary Gloss, identifying 41,784 legal references. Each reference was linked to a specific lemma, chapter, and title in the Liber Extra, creating a comprehensive index, which was further validated by the domain expert, showing a very high accuracy [L2]. The index not only facilitates navigation but also enables new forms of analysis. For example, researchers can now compute the frequency of use in references of any norm, their distribution in text, supporting the exploration of their role and significance in medieval legal thought. The CRF model also found a few cases of non-legal references, such as citations to Gospel passages, highlighting the complexity of medieval legal texts.
The index is thus a valuable resource for researchers in Legal History and Religious Studies, enabling the exploration of connections between legal norms and their interpretations, shedding light on the intellectual context of medieval jurists.
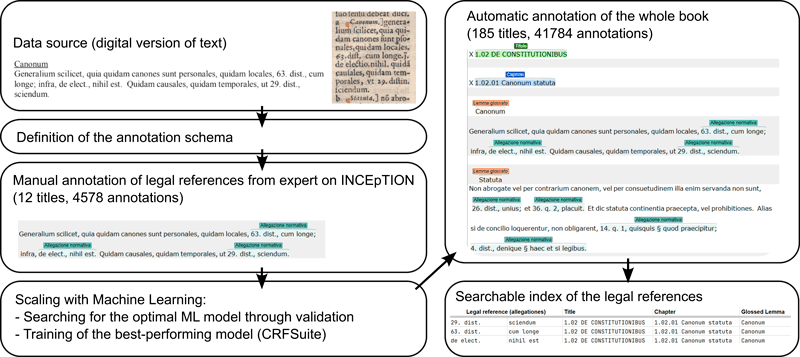
Figure 1: An illustration of the process that led to construction of the index of all the legal references in the Liber Extra’s Glossa Ordinaria.
This project highlights the transformative potential of AI in the study of historical texts, providing tools that make vast corpora accessible and analysable. The creation of coordinated and interconnected databases of normative texts and their commentaries could significantly impact the field, enabling large-scale comparative studies and the development of advanced retrieval systems.
By combining domain expertise with machine learning, we created a resource that not only supports current research but also paves the way for future discoveries. The index and code [L3] are publicly available, to be used as tools and as guidelines for similar projects in the humanities.
The ITSERR project is funded by the European Union - NextGenerationEU (CUPB53C22001770006).
Links:
[L1] https://www.itserr.it/
[L2] https://doi.org/10.5281/zenodo.14381709
[L3] https://github.com/aesuli/CIC_annotation
References:
[1] E. Reno, “The Digital Decretals”, 2024.
[2] J.-C. Klie et al., “The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation,” 2018.
[3] A. Esuli et al., “Automatic Annotation of Legal References (Allegationes) in the Liber Extra’s Ordinary Gloss”, IRCDL 2024
Please contact:
Giovanni Puccetti
CNR-ISTI, Pisa, Italy

