









by Giovanni Puccetti (CNR-ISTI), Laura Righi (University of Modena and Reggio Emilia), Ilaria Sabbatini (University of Palermo), and Andrea Esuli (CNR-ISTI)
We produced a novel dataset of 4,533 medieval Latin regesta (summaries) paired with full texts, extracted through a meticulous pipeline involving manual annotation, custom model training, text extraction, and post-processing to ensure high-quality, structured data for AI-driven summarization tasks.
The dataset enables AI-driven summarization of historical documents. We evaluated the performance of Large Language Models (LLMs) in generating Latin regesta, offering insights into the challenges and potential of AI in digital humanities.
The REVERINO dataset (REgesta generation VERsus latIN summarizatiOn) [1], developed under the ITSERR [L1] project, focuses on summarizing medieval Latin documents, particularly pontifical texts from the 13th century. Regesta, concise summaries of historical documents, are essential for scholars studying large collections of latin documents. REVERINO pairs regesta with their corresponding full texts and apparatus (i.e., bibliographic information on the source of the regestum), extracted from two collections: Epistolae saeculi XIII e regestis pontificum Romanorum selectae (MGH, 1216-1268) and Les Registres de Gregoire IX (Auvray, 1227/41).
Generating the REVERINO Dataset
The input data for the process consist of high-resolution images from the pages of the volumes in the two collections. Creating the dataset involved a four-step pipeline:
- Annotation: Manual annotation of pages by domain experts using the eScriptorium [2] platform to identify and segment text areas and lines. In this phase we simplified the work of experts requesting that they identify the main content of the page. The experts were not required to separate the different parts of the main content (i.e., regesta, apparatus, full text), as this was done automatically in post-processing.
- Training: The annotated data allowed us to train customized segmentation models for the collections. The models segment the main content, separating it from any additional content (e.g., titles, headers, footers, footnotes, line numbers). Each collection required a specific model, as the MGH collection uses a single-column format, while the Auvray collection uses a more complex two-column format, requiring additional training data to improve segmentation accuracy.
- Extraction: We used the trained models to segment and perform OCR to extract text from all pages. This step produced a continuous stream of text that includes the regesta, full texts, and apparatus, but without labels to distinguish them.
- Post-processing: We could define simple heuristics based on content and positional information, leveraging the accurate information regarding text position and size produced by the trained models, to accurately split the text into regesta, apparatus, and full texts, producing the structured information we aimed to obtain.
The final dataset comprises 2,283 pairs from the MGH collection and 2,250 from Auvray. A t-SNE analysis [F2] on the text of regesta revealed distinct clusters for each collection, highlighting their unique characteristics due to differences in topics, sources, and editorial style.
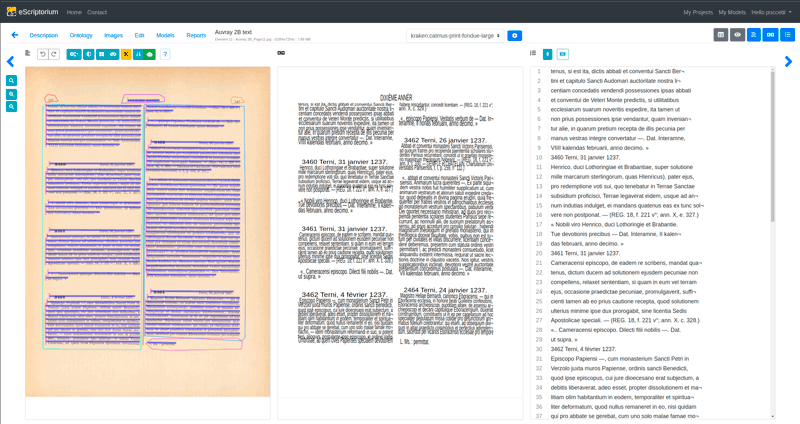
Figure 1: The annotation interface with the segmented regions and the output of the OCR process.
Training LLM on Regesta Generation
We used REVERINO as a benchmark for evaluating the ability of LLMs to generate regesta. Three models—GPT-4, Llama 3.1 70b, and Llama 3.1 405b—were tested using two approaches:
1. Direct Summarization (format): The model generates a regestum directly from the Latin full text.
2. Translation-Summarization (backtranslate): The model first translates the Latin full text into English, generates a summary in English, and then translates it back into Latin.
Quantitative evaluation using Rouge and Bleu metrics showed that GPT-4 outperformed the Llama models, achieving a Rouge-1 score of 0.39 on the MGH part of the dataset. Llama models performed better in the backtranslate setting, suggesting that the forced translation to English exploits the better summarisation capabilities of the model in their main language.
Qualitative analysis by a domain expert revealed challenges in accurately identifying key elements that are expected in regesta, such as the Pope’s name, dates, and recipients. For example, GPT-4 correctly identified the Pope in 11 out of 20 cases and the recipient in 15, but only three dates were accurately extracted. These findings highlight the complexity of summarizing historical texts and the need for further refinement.
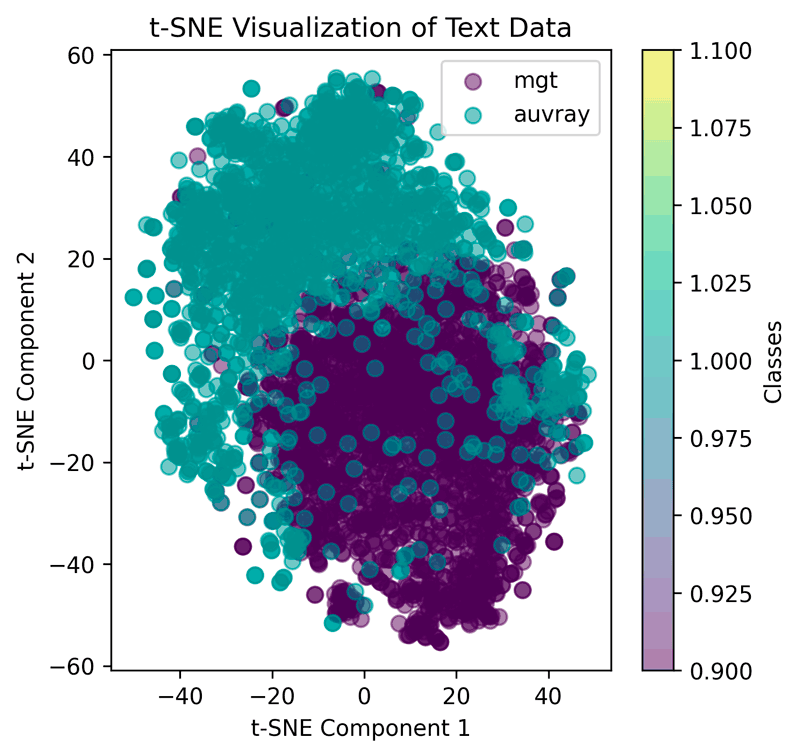
Figure 2: T-SNE plot showing the distribution of samples from the two collections MGH (dark) and Auvray (light).
Conclusions
The REVERINO dataset provides a foundation for training models to automate the summarization of Latin texts, while the evaluation of LLMs offers insights into their strengths and limitations. Future work will expand the dataset to include more collections, further improve custom model training, and refine prompt engineering to improve summarization accuracy.
The ITSERR project is funded by the European Union - NextGenerationEU (CUP B53C22001770006).
Links:
[L1] https://www.itserr.it/
[L2] https://zenodo.org/records/14971613
References:
[1] G. Puccetti et al., “REVERINO: REgesta generation VERsus latIN summarizatiOn”, IRCDL 2025.
[2] B. Kiessling, et al., “eScriptorium: an open source platform for historical document analysis”, ICDARW, 2019.
Please contact:
Giovanni Puccetti
CNR-ISTI, Italy

