









by Cristóbal Barba-González, José F. Aldana-Montes, and Ismael Navas-Delgado (ITIS, University of Málaga)
This article presents TITAN, a platform designed to enable the creation and execution of Big Data analytics workflows. Using semantic technologies, TITAN ensures the integration, validation, and reusability of data-driven components, empowering researchers and industries to handle large-scale data challenges more effectively. Through real-world case studies, we demonstrate its potential in transforming data processing workflows across various domains.
Processing, analyzing, and deriving valuable insights from large datasets is more critical than ever in today’s data-driven society. Thus, large-scale data management, processing, and value extraction are significant challenges for organisations due to the exponential expansion of data generated by connected devices, businesses, and customers. However, conventional analytics techniques frequently find handling Big Data’s volume, speed, and complexity to be challenging. Therefore, creating platforms that offer adaptable, scalable, and semantically rich Big Data analytics solutions is crucial to overcoming these obstacles.
TITAN [1] is a platform designed to support the creation, management, and deployment of data science workflows for Big Data analytics. What sets TITAN apart from other platforms is its innovative use of semantic technologies, which enables the definition and orchestration of complex workflows. The core of TITAN is the BIGOWL ontology [2], which provides formal definitions to annotate all workflow components semantically. Furthermore, these semantics enable consistent and interpretable definitions of each component. Hence, this semantic layer ensures that workflows are correctly defined and facilitates automatic validation of component compatibility, which is crucial in large-scale environments.
TITAN’s design focuses on making Big Data workflows accessible, flexible, and reproducible. Its architecture allows for the modularisation of data processing tasks [L1], such as data loading, transformation, analysis, and storage. Each task within a workflow can be seen as a self-contained component that can be reused across different workflows. Based on Docker containers, this modular approach benefits researchers, data scientists, and organisations that must adapt their analytics pipelines to diverse use cases without rebuilding components from scratch (Figure 1).
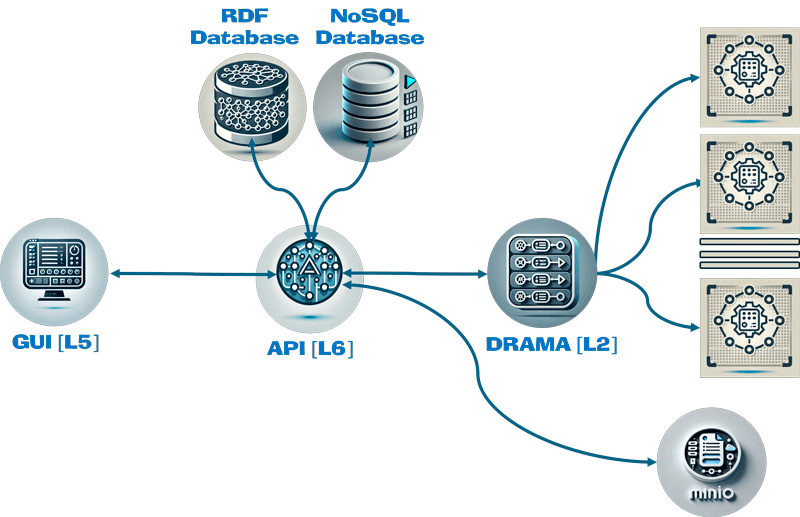
Figure 1: TITAN architecture. The users interact with a GUI that enables the creation of workflows using the available components in its RDF repository. Executing the workflows requires using the needed data and a set of workers to perform data analysis. This is orchestrated by DRAMA using a NoSQL database to track workflow execution and a MinIO distributed data storage to manage the input and output data of each component.
A key feature of TITAN is its ability to integrate and process data from multiple sources, enabling end-to-end analytics workflows that span data collection, processing, and visualization. Additionally, the platform supports popular tools and frameworks for Big Data processing, such as Apache Spark, Kafka, and TensorFlow, ensuring seamless integration with existing infrastructures. This capability is valuable for dealing with large volumes of real-time or streaming data.
Another benefit is TITAN’s ability to track data lineage through its semantic model. Using RDF (Resource Description Framework) triples, TITAN provides a transparent record of data’s origins, transformations, and final outputs. This transparency is critical in ensuring data quality and reproducibility, especially in complex analytical scenarios involving multiple stakeholders or regulatory requirements. This feature makes it easy to publish the workflow results as FAIR data.
TITAN was initially applied to three case studies across various domains to demonstrate its versatility and power:
- Iris Flower Classification (Machine Learning): The first case study uses a classic machine learning problem—classifying different species of the Iris flower based on attributes such as petal and sepal length. TITAN enables the workflow to comprise several modular tasks, such as dataset loading, data splitting, model training, and validation. Each task is semantically annotated, ensuring the components are compatible and data flows seamlessly. By leveraging TITAN, building and validating a machine learning model becomes more streamlined and efficient.
- Human Activity Recognition (Deep Learning): In this case, TITAN handles large-scale data generated by wearable devices (30 TB of accelerometer data). The workflow includes training deep learning models (such as ConvNet and LSTM) for activity classification. TITAN integrates with Apache Spark to manage the massive volume of data, while its semantic layer ensures that the components used in the workflow are correctly configured and compatible. This case highlights TITAN’s ability to support real-time data processing, scalability, and complex model training in Big Data environments.
- Automatic Monitoring of Earth Observation Satellite Images: The third case study involves classifying regions of interest in satellite images captured by the Sentinel-2 constellation. The workflow includes downloading satellite data, preprocessing images, training a support vector machine (SVM) model, and testing the model. Through TITAN, each step is defined as a task with precise inputs, outputs, and parameters, which are semantically validated. This case illustrates TITAN’s potential for environmental monitoring, showcasing its flexibility in handling spatial data and complex analytical pipelines.
TITAN is an actively evolving tool successfully applied in various real-world scenarios, driving continuous improvement. Its core validation and evaluation framework, Drama [L2], has progressed into the more advanced DramaX [L3], enabling enhanced workflow support. This evolution has allowed TITAN to underpin the development of innovative infrastructures for scientific data analysis, including applications in environmental data processing [L4]. Notably, TITAN has facilitated the creation of impactful workflows for European environmentalists, such as a predictive model for pollen levels [3].
TITAN represents a significant step forward in Big Data analytics, offering a semantically enriched platform for building, deploying, and managing complex data workflows. TITAN makes creating scalable, reusable, and interoperable data pipelines easier through its modular architecture, semantic validation, and support for various data processing tools. Furthermore, TITAN ensures data quality and reproducibility by tracking data lineage through its semantic model. By supporting diverse case studies across different industries, TITAN demonstrates its versatility and potential to transform the way Big Data analytics are conducted, making it a valuable tool for researchers and industries.
Links:
[L1] https://github.com/KhaosResearch/TITAN-dockers
[L2] https://github.com/KhaosResearch/drama
[L3] https://github.com/KhaosResearch/dramaX
[L4] https://ercim-news.ercim.eu/en135/special/advancing-climate-change-resilience-through-ecosystems-and-biodiversity-monitoring-and-analysis
[L5] https://github.com/KhaosResearch/TITAN-GUI
[L6] https://github.com/KhaosResearch/TITAN-API
References:
[1] A. Benítez-Hidalgo, et al., “TITAN: A knowledge-based platform for Big Data workflow management,” Knowledge-Based Systems, vol. 232, p. 107489, 2021, doi: 10.1016/j.knosys.2021.107489.
[2] C. Barba-González, et al., “BIGOWL: Knowledge centered Big Data analytics,” Expert Systems with Applications, vol. 115, pp. 543-556, 2019, doi: 10.1016/j.eswa.2018.08.026.
[3] S. Hurtado, et al., “e-Science workflow: A semantic approach for airborne pollen prediction,” Knowledge-Based Systems, vol. 284, p. 111230, 2024, doi: 10.1016/j.knosys.2023.111230.
Please contact:
Ismael Navas Delgado
ITIS Software, University of Málaga, Spain

