









by Mohammed Salah Al-Radhi and Géza Németh (Budapest University of Technology and Economics, TMIT-VIK, Budapest, Hungary)
How can brain activity be turned into clear, intelligible speech? An ambitious research initiative in Hungary is addressing this question by developing cutting-edge methods to decode neural signals into speech, aiming to restore communication for individuals with severe speech disorders.
Speech disorders caused by neurological conditions can shatter lives, cutting individuals off from their loved ones and the world. A pioneering Hungarian project (EKÖP-24-4-II-BME-197), funded by NKFI [L1] and ENFIELD [L2], is tackling this crisis by developing revolutionary brain-to-speech technologies, aiming to restore voices to those who have lost them.
The project centres on decoding speech envelopes—patterns of neural activity that convey essential information about speech articulation. These envelopes represent the rhythm and amplitude of speech, capturing the dynamic features necessary for intelligible and natural communication. By using state-of-the-art signal processing and advanced machine learning techniques, the research team is unlocking the potential of brain-computer interfaces for real-time communication restoration. The goal is ambitious but deeply impactful: to enable individuals with severe speech disorders to express themselves again.
Our team has introduced novel prosody-aware feature engineering methods and a transformer-based speech synthesis model to enhance Brain-to-Speech reconstruction. The developed pipeline begins with preprocessing raw neural data (e.g., EEG) using wavelet denoising and time-frequency analysis. This ensures the preservation of critical neural features such as intonation, pitch, and rhythm—elements essential for natural speech synthesis [1]. Unlike traditional pipelines, our approach prioritizes prosodic features, improving the emotional and expressive quality of reconstructed speech. At the core of the system lies our transformer encoder architecture, specifically designed to decode speech envelopes from neural signals. This model integrates attention mechanisms [2], enabling it to dynamically focus on the most relevant neural patterns. By incorporating prosodic features into the decoding process, the model achieves superior intelligibility and expressiveness compared to baseline methods such as bidirectional RNNs and Griffin-Lim vocoders [3]. Once the speech envelope is decoded, the final step involves synthesizing synthesising the predicted speech signals into intelligible and natural-sounding audio. This is achieved through cutting-edge neural vocoders such as AutoVocoder and BigVGAN [L3]. These vocoders are engineered to convert the decoded speech envelopes into high-fidelity waveforms with precise control over pitch, tone, rhythm, and even emotional expressiveness.
Figure 1 illustrates the system’s journey from raw neural signals to intelligible speech. It highlights the sequential processes of signal preprocessing, time-frequency analysis, neural decoding, and speech synthesis. The visualization underscores the complex pipeline that transforms noisy EEG recordings into clear, meaningful speech. By leveraging these advanced synthesis tools, the system not only achieves technical accuracy but also ensures that the reconstructed speech conveys the nuances necessary for effective and engaging communication. This technology offers a lifeline for individuals affected by ALS (amyotrophic lateral sclerosis), strokes, traumatic brain injuries, or other conditions that impair speech. It restores their ability to communicate, bringing autonomy and connection back into their lives. For individuals unable to speak due to neurological disorders, even a few words can rebuild bridges to loved ones, healthcare providers, and society.
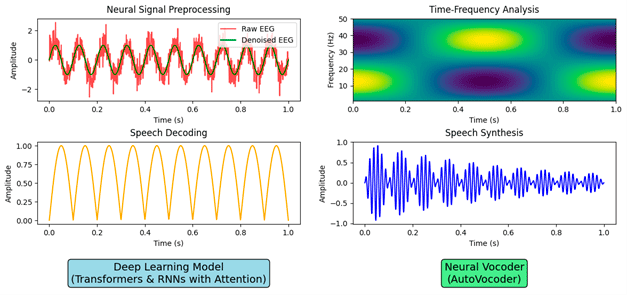
Figure 1: The neural decoding and speech synthesis pipeline. The figure illustrates the process of transforming raw neural signals (EEG) into intelligible speech. Starting with raw and denoised EEG signals, the system performs time-frequency analysis to extract key neural features. These features are then decoded using advanced deep learning models (Transformers and RNNs with attention mechanisms), which predict speech envelopes. Finally, the predicted speech envelopes are synthesized into audible speech using neural vocoders, ensuring both accuracy and expressivity.
From a scientific perspective, the project breaks new ground in neuroprosthetics and brain-computer interfaces (BCIs), providing a foundation for future assistive technologies. The methodologies developed here could extend to broader applications, such as neural control of robotics and virtual assistants. However, significant challenges remain on the path to bringing this technology into everyday use. One key difficulty is making the system work in real-time. While the current models are highly accurate, they require substantial computing power, which makes instant processing difficult. The team is refining these models to run faster and more efficiently without losing accuracy, a crucial step for practical applications. Another challenge lies in tailoring the system to each user. Everyone’s brain is unique, with differences in structure, neural activity, and how speech disorders affect them. To address this, the researchers are developing ways for the system to “learn” and adapt to each individual’s brain patterns. This personalized approach will ensure that the technology works well for people of all backgrounds and needs.
The vision for the future is a brain-to-speech system that is as easy to use as current assistive devices, enabling people to speak their thoughts naturally and effortlessly. By combining innovations in neuroscience, artificial intelligence, and signal processing, this project is breaking down the barriers of silence, offering a voice to those who need it most.
Links:
[L1] https://www.bme.hu/EKOP
[L2] https://www.enfield-project.eu/
[L3] https://github.com/NVIDIA/BigVGAN
References:
[1] Verwoert, M., Ottenhoff, M.C., Goulis, S. et al., “Dataset of Speech Production in intracranial Electroencephalography,” Nature Scientific Data, 9, 434,2022. https://doi.org/10.1038/s41597-022-01542-9
[2] D. Soydaner, “Attention mechanism in neural networks: where it comes and where it goes”, Neural Comput & Applic 34, 13371–13385,2022. https://doi.org/10.1007/s00521-022-07366-3
[3] M.S. Al-Radhi, G. Németh, “Brain-to-Speech: Prosody Feature Engineering and Transformer-Based Reconstruction”, Book Chapter: Artificial Intelligence, Data and Robotics: Foundations, Transformations, and Future Directions, under preparation, 2025.
Please contact:
Mohammed Salah Al-Radhi,
Budapest University of Technology and Economics, Budapest, Hungary

