









by Benoît Choffin (LRI), Fabrice Popineau (LRI) and Yolaine Bourda (LRI)
Current adaptive and personalised spacing algorithms can help improve students’ long-term memory retention for simple pieces of knowledge, such as vocabulary in a foreign language. In real-world educational settings, however, students often need to apply a set of underlying and abstract skills for a long period. At the French Laboratoire de Recherche en Informatique (LRI), we developed a new student learning and forgetting statistical model to build an adaptive and personalised skill practice scheduler for human learners.
Forgetting is a ubiquitous phenomenon of human cognition that not only prevents students from remembering what they have learnt before but also hinders future learning, as the latter often builds on prior knowledge. Fortunately, cognitive scientists have uncovered simple yet robust learning strategies that help improve long-term memory retention: for instance, spaced repetition. Spacing one’s learning means to temporally distribute learning episodes instead of learning in a single “massed” session, i.e., cramming. Furthermore, carefully selecting when to schedule the subsequent reviews of a given piece of knowledge has a significant impact on its future recall probability [1].
On the other hand, concerns about the “one-size-fits-all” human learning paradigm have given rise to the development of adaptive learning technologies that tailor instruction to suit the learner’s needs. In particular, recent research effort has been put into developing adaptive and personalised spacing schedulers for improving long-term memory retention of simple pieces of knowledge. These tools sequentially decide which item (or question, exercise) to ask the student at any time based on her past study and performance history. By focusing on weaker items, they show substantial improvement of the learners’ retention at immediate and delayed tests compared to fixed review schedules. Some popular flashcard learning tools, such as Anki and Mnemosyne, use this type of algorithm.
However, adaptive spacing schedulers have historically focused on pure memorisation of single items, such as foreign language words or historical facts. Yet, in real-world educational settings, students also need to acquire and apply a set of skills for a long period (e.g., in mathematics). In this case, single items potentially involve several skills at the same time and are practiced by the students to master these underlying skills. With this ongoing research project, we aim at developing skill review schedulers that will recommend the right item at the right time to maximise the probability that the student will correctly apply these skills in future items. An example skill reviewing policy from an adaptive spacing algorithm is given in Figure 1.
To address this issue, we chose to follow a model-based approach: a student learning and forgetting model should help us to accurately infer the impact on memory decay of selecting any skill or combination of skills at a given timestamp. Previous work from Lindsey et al. [2] had similarly chosen to select the item whose recall probability was closest to a given threshold: in other words, recommending the item that is on the verge of being forgotten. Unfortunately, no student model from the scientific literature was able to infer skill mastery state and dynamics when items involve multiple skills.
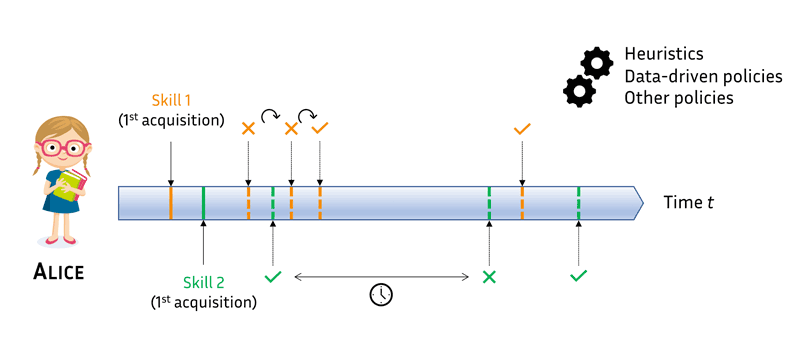
Figure 1: Example skill reviewing schedule from an adaptive spacing algorithm. Solid line indicates the first acquisition of a skill and the dashed line, the subsequent reviews of that skill. Alice is trying to master two skills (resp. in orange and green) with an adaptive spacing tool. She first reviews skill 1 but either because she already forgot it or because she did not master it in the first place, she fails to recall it and is rapidly recommended to review it again. The situation is different for skill 2: her first attempt is a win and the algorithm makes her wait longer before reviewing it again. Diverse methods can be used to personalize spacing: heuristics, data-driven reviewing policies, etc.
To bridge this gap, we developed a new student learning and forgetting statistical model called DAS3H [3]. DAS3H builds on the DASH model from Lindsey et al. [2]. DASH represents past student practice history (item attempts and binary correctness outcomes) within a set of time windows to predict future student performance and is inspired by two major cognitive models of human memory, ACT-R and MCM. Most importantly, DASH has been used in a real-world experiment [2] to optimise reviewing schedules for Spanish vocabulary learning in an American middle school. Compared to a fixed review scheduler, the personalised DASH-based algorithm achieved a 10% improvement at a cumulative exam at the end of semester. Our model DAS3H extends DASH by incorporating item-skills relationships information inside the model structure. The goal was both to improve model performance when prior information is at hand and to use the model estimates of skill mastery state and memory dynamics it encapsulates to prioritise item recommendation.
To evaluate our model’s potential use in an adaptive and personalised spacing algorithm for reviewing skills, it was necessary to first compare its predictive power to that of other student models on real-world data. Thus, we tested DAS3H on three large educational datasets against four state-of-the-art student models from the educational data mining literature. We split the student population into five disjoint groups, trained all models each time on four groups and predicted unknown student binary outcomes on the fifth group. On every dataset, DAS3H showed substantially higher predictive performance than its counterparts, suggesting that incorporating prior information about item-skills relationships and the forgetting effect improves over models that consider one or the other. Our Python code has been made public on GitHub: see [L1].
Besides its performance, our model DAS3H has the advantage of being suited to the adaptive skill practice and review scheduling problem that we are trying to address. For instance, it could be used at any timestamp to predict the impact of making the student review each skill and then to select the most promising skill or combination of skills. In future research, we intend to investigate heuristics and data-driven policies for selecting items to maximise long-term memory retention on a set of underlying skills.
Link:
[L1] https://kwz.me/hKt
References:
[1] N. J. Cepeda et al.: “Spacing effects in learning: A temporal ridgeline of optimal retention”, Psychological science, 19(11), 2008
[2] R. V. Lindsey et al.: “Improving students’ long-term knowledge retention through personalized review”, Psychological science, 25(3), 2014
[3] B. Choffin et al.: “DAS3H: Modeling Student Learning and Forgetting for Optimally Scheduling Distributed Practice of Skills”, Educational Data Mining, 2019
Please contact:
Benoît Choffin
Laboratoire de Recherche en Informatique (LRI), France

