









by Ilias Iliadis (IBM Research – Zurich Laboratory)
A huge and rapidly growing amount of information needs to be stored on storage devices and on the cloud. Cloud users expect fast, error-free service. Cloud suppliers want to achieve this high quality of service efficiently to minimise cost. Redundancy, in particular erasure coding, is widely used to enhance the reliability of storage systems and protect data from device and media failures. An efficient system design is key for optimising operation.
Today’s storage systems must store an enormous amount of data across multiple storage units. Regardless of the quality of the storage technology, errors will occur. It is therefore possible that one of these storage unit could fail in its entirety. To further protect data from being lost and to improve the reliability of the data storage system, replication-based storage systems spread replicas corresponding to data stored on each storage device across several other storage devices. This is done in a way that allows the data to be recovered even if a whole storage unit fails. To improve the efficiency of the replication schemes, “erasure coding” schemes that provide a high data reliability as well as high storage efficiency are deployed.
User data is divided into blocks (or symbols) of a fixed size (e.g., sector size of 512 bytes) and complemented with parity symbols to form codewords. From these codewords, the original data can be restored. Also, these codewords can be placed on the available devices in different ways, which affects the reliability level achieved. The two basic placement schemes, clustered and declustered, are shown in Figure 1. The clustered placement scheme stores data and its associated parities in a set of devices with the number of devices being equal to the codeword length whereas the declustered placement spreads data and its associated parities across a larger number of devices.
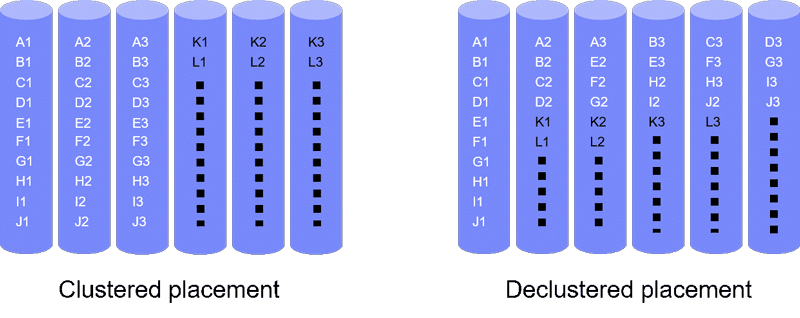
Figure 1: Clustered and declustered placement of codewords of length three on six devices. X1, X2, X3 represents a codeword (X = A, B, C, . . . , L).
When storage devices fail, codewords lose some of their symbols, and this leads to a reduction in data redundancy. The system attempts to maintain its redundancy by reconstructing the lost codeword symbols using the surviving symbols of the affected codewords. When a clustered placement scheme is used, the lost symbols are reconstructed directly in a spare device, as shown in Figure 2.
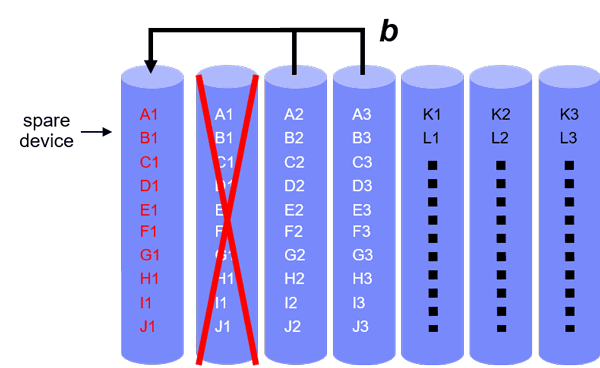
Figure 2: Rebuild under clustered placement.
When a declustered placement scheme is used, as shown in Figure 3, spare space is reserved on each device to temporarily store the reconstructed codeword symbols before they are transferred to a new replacement device. The rebuild bandwidth available on all surviving devices is used to rebuild the lost symbols in parallel, which results in smaller vulnerability windows compared to the clustered placement scheme.
The redundancy in the block-coding scheme and in the replication over several storage units, adds to the cost of the system. Another cost is the transmission capacity required between the storage units for block recovery. An additional performance cost is incurred by the update operations associated with the redundancy scheme.
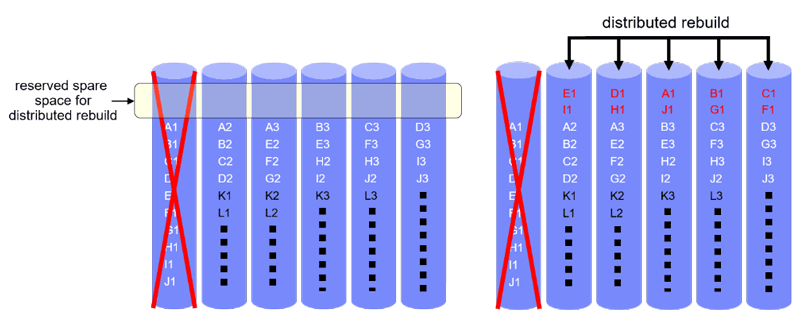
Figure 3: Rebuild under declustered placement.
Reliability is assessed via the Mean Time to Data Loss (MTTDL) and the Expected Annual Fraction of Data Loss (EAFDL) metrics. For such a storage system to operate efficiently with good quality of service, one is faced with a multi-dimensional optimisation problem. We have tackled this problem theoretically by developing a method to derive the MTTDL and EAFDL metrics analytically for various data placement schemes.
The methodology uses the direct path approximation and does not involve Markovian analysis [1]. It considers the most likely paths that lead to data loss, which are the shortest ones. It turns out that this approach agrees with the principle encountered in the probability context expressed by the phrase “rare events occur in the most likely way”. The reliability level of systems composed of highly reliable components is essentially determined by the “main event”, which is the shortest way to failure [2].
The analytical reliability expressions derived can be used to identify redundancy and recovery schemes as well as data placement configurations that can achieve high reliability. Superior reliability is achieved by a distributed data placement scheme, which spreads redundant data associated with the data stored on a given device in a declustered fashion across several devices in the system.
Contrary to general assumption, we found that increasing codeword length does not necessarily improve reliability. This is demonstrated in Figure 4, which plots reliability as a function of codeword length (m) for various storage efficiency values. It demonstrates that increasing codeword length initially improves reliability, but at some point reliability begins to degrade. This is due to two opposing effects: on the one hand, larger codeword lengths imply that codewords can tolerate more device failures, but on the other hand, they result in a higher exposure degree to failure as each of the codewords is spread across a larger number of devices. Further insights into this subtle phenomenon are offered by additional results, presented graphically in [1].
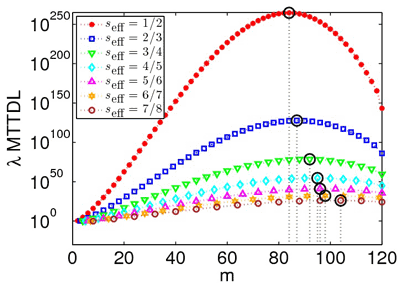
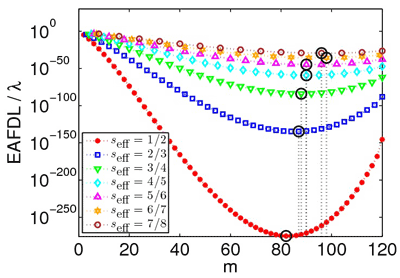
Figure 4: Reliability versus codeword length for various storage efficiency values.
The effect of successive device failures that are correlated has also been considered [3]. The existing theoretical models can be enhanced to also consider the correlation effect according to the methodology detailed in [3]. The results obtained demonstrate that correlated device failures have a negative impact on reliability.
Links:
General information about cloud storage systems:
https://www.zurich.ibm.com/cloudstorage/
References:
[1] I. Iliadis: “Reliability Evaluation of Erasure Coded Systems under Rebuild Bandwidth Constraints”, International Journal on Advances in Networks and Services, vol. 11, no. 3&4, pp. 113-142, December 2018.
[2] I. Iliadis and V. Venkatesan: “Most Probable Paths to Data Loss: An Efficient Method for Reliability Evaluation of Data Storage Systems”, International Journal on Advances in Systems and Measurements, issn 1942-261x, vol. 8, no. 3&4, pp. 178-200, December 2015.
[3] I. Iliadis, et al.: “Disk Scrubbing Versus Intradisk Redundancy for RAID Storage Systems”, ACM Trans. Storage, vol. 7, no. 2, article 5, 42 pages, July 2011.
Please contact:
Ilias Iliadis
IBM Research – Zurich Laboratory

