









by Rafael Kuffner dos Anjos, Carla Fernandes (FCSH/UNL) and João Madeiras Pereira (INESC-ID)
Viewpoint-free visualisation using sequences of point clouds can capture previously lost concepts in a contemporary dance performance.
The BlackBox project aims to develop a model for a web-based collaborative platform dedicated to documenting the compositional processes used by choreographers of contemporary dance and theatre. BlackBox is an interdisciplinary project spanning contemporary performing arts, cognition and computer science.
Traditionally, performing arts such as dance are taught either by example or by looking at individual artist-driven scores on paper. With different dance movements emerging during the composition of a new choreography, and the difficulty of creating a controlled vocabulary of movements to compose a score, watching videos of previous performances or of rehearsals is often the way to learn a specific dance. However, an ordinary video is not sufficient to communicate what is envisioned by the choreographer [1] since a video is restricted to a single point of view. This introduces ambiguity when occlusions occur between different dancers or props within the performance.
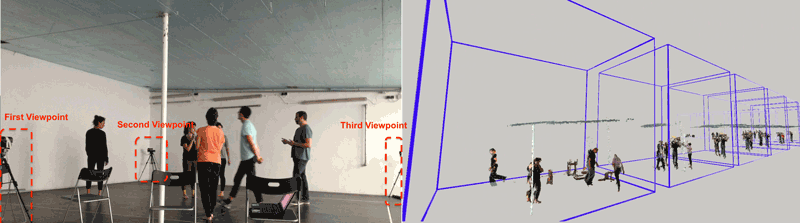
Figure 1: Example of our capture setup (left), and timeline visualisation of a recorded improvisation session.
Previously published work on three-dimensional motion capture for dance has resorted to markers in the dancer’s bodies for skeletal reconstruction, or happened in a controlled environment such as a laboratory. These approaches are not viable for our goal of capturing the creative process of a choreographer. The creation of a play happens in a very timely restricted schedule and is in constant evolution. To capture the transient concepts in the studio, our setup must be mobile, and capture not only skeletal information, but also more context about the rehearsal space.
We are developing an application, called 3D Flashback, which captures a sequence of point clouds using a Kinect-based wide-baseline capture setup, then uses this data to create a viewpoint-free visualisation of a given performance without the restrictions of previous systems.
We developed a network-based synchronisation and calibration software in collaboration with the Visualisation and Intelligent Multimodal Interfaces (VIMMI) group from INESC-ID. It allows us to quickly deploy and grossly calibrate our Kinect-based capture setup using the human skeleton tracking feature from Kinect, which can be refined on more challenging scenarios by matching different views of a streamed point cloud.
Our early approach was applied to a contemporary dance improvisation scenario, where a simple visualizer was developed to show annotations made on a 2D video on a 3D point cloud sequence [2]. An existing annotator was extended to correctly assign 3D coordinates to the point cloud. The length of recording constraint imposed by a naive representation was a problem, since each improvisation session lasted for twenty minutes.
Currently the main research challenges are the representation and compression of the recorded point cloud datasets, and their visualisation. We are focused on further developing current image-based representations for video-based rendering, so they can be efficiently applied in a wide-baseline scenario. Regarding visualisation, we are working on improving current surface splatting techniques for better results on close-ups, and faster rendering which takes advantage of an image-based representation.
The BlackBox project is funded by the European Research Council (Ref. 336200) and hosted at FCSH-UNL, Lisbon, Portugal and runs from 2014 to 2019. During this five year period we will be collaborating with three different choreographers. These realistic scenarios will be used to validate our developed system and solution for video-based rendering and build upon our previous prototype for a video annotation application. The web-based collaborative platform will contain the results of our studies, where users will be able to browse annotated three-dimensional videos explaining the respective authoral creative processes and specific concepts underlying the performances.
Link:
http://blackbox.fcsh.unl.pt/
References:
[1] A. Hutchinson Guest: “Dance notation: The process of recording movement on paper”, New York: Dance Horizons, 1984.
[2] C. Ribeiro, R. Kuffner, C. Fernandes, J. Pereira: “3D Annotation in Contemporary Dance: Enhancing the Creation-Tool Video Annotator”, in Proc. of MOCO ‘16, ACM, New York, NY, USA, Article 41, 2016. DOI: http://dx.doi.org/10.1145/ 2948910.2948961
Please contact:
Rafael Kuffner dos Anjos,
Carla Fernandes
The Faculty of Social Sciences and Humanities, Universidade Nova de Lisboa, Portugal
João Madeiras Pereira
INESC-ID, Portugal

