









by Yo Joong Choe (INSEAD) and Sebastian Arnold (CWI)
New research develops novel statistical methodology, based on e-values, for monitoring whether one uncertain prospect (say, a new investment option) has an upside over another (say, the current investment). These e-values can flexibly and effectively test for multiple notions of upside over time, as defined by the decision-maker’s preferences, and they come with a direct monetary interpretation that guides the decision (say, whether to invest in the new option).
Imagine you are presented with two recurring “bets” whose outcomes are uncertain. One of these bets is the financial asset that you currently invest in, say a government bond; the other is a riskier asset that you were keeping your eye on, say a lesser-known stock that you think may have an upside. Quick research tells you that the average historical returns of these two assets have been nearly identical. Unsure what to do, you decide to monitor these prospects over time to answer the question: is there enough evidence that there is an upside to this new “bet” over the old one?
This upside question, over a pair of uncertain prospects, is not just relevant to financial decision-making. We could also compare the performance of a new football player over a comparable player on the squad; the carbon offset levels of a new policy over an existing one for a business; or even the efficacy of a newly approved drug over an existing one across different subpopulations. While the alternatives in the latter scenarios may not initially look like “bets,” they are, in reality, uncertain prospects whose relative upsides need to be monitored carefully before we commit to a decision.
In a recent work [1], together with Marco Scarsini and Ilia Tsetlin, we found that various forms of this upside question can be answered effectively using e-values [2] as our measure of statistical evidence. The first key benefit of using e-values is that, instead of a binary decision at a fixed sample size, we can compute a sequentially accumulating evidence measure for the relative upside of a prospect. The resulting test permits continuous monitoring – a procedure that invalidates classical p-values – allowing the decision-maker (DM) to make informed decisions at any time point.
Another benefit of e-values is that it naturally comes with an intuitive monetary interpretation. Consider the simplest form of the upside question: is the new financial asset more likely to yield a positive return than the old one? Now, suppose that a bookmaker offers us a hypothetical betting game. For every euro we invest, we win an extra euro if the new prospect nets a positive return while the old prospect yields a negative return; we lose the euro if the opposite happens. (It is a “push” if both go positive or both go negative.) The rules of this “bet on bets” hint at the bookmaker’s implicit hypothesis: the new prospect is not more likely to yield a positive return than the old one.
This betting game reveals a key insight underlying e-values. If we were to start with a euro and repeatedly bet a fraction of our money on this hypothetical gamble, then we can only expect to grow our wealth if the bookmaker’s hypothesis is wrong and the new prospect is indeed more likely to yield a positive return than the old one. In the testing-by-betting framework [2], the amount of money we make from this gamble is our evidence against the bookmaker’s claim, and we refer to this wealth as the e-value. It would be very surprising to make, say, 100 euros in this betting game, regardless of how cleverly we make our bets, if the new prospect in fact had no upside over the old one. If needed, we can connect this notion back to classical statistics: rejecting the null hypothesis at a significance level of 1% corresponds to rejecting it after making 100 times the initial wealth.
In our work, we derive an optimal betting strategy for this game that maximizes the expected growth rate of the e-value whenever, in reality, the bookmaker’s hypothesis is incorrect. This means that, when using this strategy, we can expect to detect an upside as quickly as possible – if there is one.
What about the broader question of whether the new prospect has an upside at some threshold, say the probability of a return above X% for an unspecified X? To answer this question, we leverage the third benefit of e-values: we can flexibly combine multiple e-values for simpler questions to answer a more complex one. Now imagine playing multiple betting games across different return thresholds, but with the same initial budget of one euro. At each round, we can split our money across all these games, and we make our bet in each game with the money allocated to that game. Then, after any given round, our combined wealth quantifies accumulating evidence for the broader upside question.
The main result of our work shows that, when using optimal bets for each game, and any reasonable strategy to split money across games, our combined wealth will grow exponentially fast, eventually to infinity, whenever there is a relative upside to the new prospect at some threshold. Figure 1 illustrates this on simulated financial returns: whenever an asset has a clear upside at an unspecified threshold, its associated e-value grows exponentially fast over time.
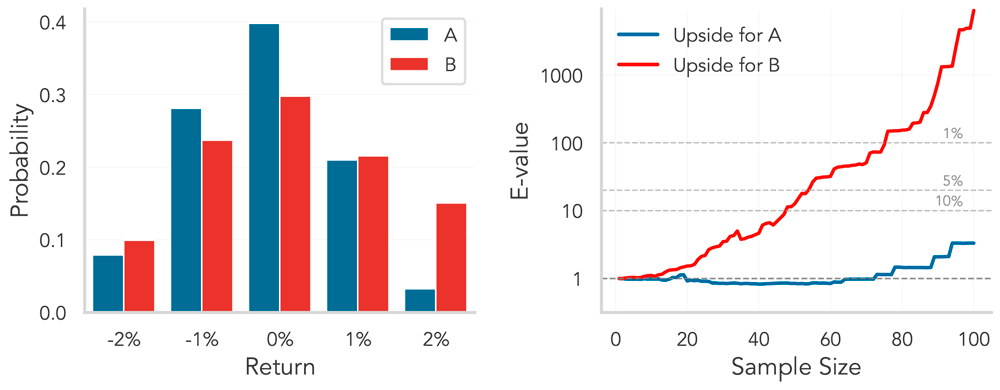
The research further makes advances on two related problems. First, it extends the methodology to other notions of upside [3], such as upsides according to risk-averse DMs. Second, it further extends the methodology to a more challenging question: can we monitor whether a new prospect has definite upside over the old one? A promising future direction is to apply these tools to monitor for upside, flexibly and in real time, across applications like online experimentation, public policy, and sports analytics.
References:
[1] S. Arnold, Y. J. Choe, M. Scarsini, and I. Tsetlin, “Betting on bets: Anytime-valid tests for stochastic dominance,” arXiv preprint arXiv:2604.21851, 2026.
[2] A. Ramdas, P. Grünwald, V. Vovk, and G. Shafer, “Game-theoretic statistics and safe anytime-valid inference,”
Statistical Science, vol. 38, no. 4, pp. 576–601, 2023.
[3] A. Müller and D. Stoyan, Comparison Methods for Stochastic Models and Risks. Hoboken, NJ, USA: Wiley, 2002.
Please contact:
Yo Joong Choe, INSEAD, Singapore
Sebastian Arnold, CWI, the Netherlands

