









by Gerhard Chroust (Johannes Kepler University Linz) and Georg Neubauer (Austrian Institute of Technology)
Effective and efficient communication and cooperation needs a semantically precise terminology, especially in disaster management, owing to the inherent urgency, time pressure, stress and often cultural differences of interventions. The European project Driver+ aims to measure the similarities between different countries’ terminologies surrounding disaster management. Each definition is characterised by a set of “descriptors” selected from a predefined anthology (the “bag-of-words”). The number of identical/different descriptors serves as a measure of the semantic similarity/difference of individual definitions and is translated into a numeric “degree of similarity”. The translation considers logical and intuitive aspects. Human judgment and mechanical derivation in the process are clearly separated and identified. By exchanging the ontology this method will also be applicable to other domains.
Clear, unambiguous and semantically precise terminology is one of the keys to effective and efficient communication, cooperation and decision making, especially in view of automation and computer support. This is highly relevant for disaster management because urgency, time pressure, stress and often cultural differences create additional complications.
The European project Driver+ (FP7-Project 607798: “DRiving InnoVation in crisis management for European Resilience”, May 2014 – April 2020) [L1] aims at “a shared understanding in Crisis Management across Europe”. Its objective is “to cope with current and future challenges due to increasingly severe consequences of natural disasters and terrorist threats, by the development and uptake of innovative solutions that are addressing the operational needs of practitioners dealing with Crisis Management”.
The DRIVER+ consortium brings together dedicated multi-national practitioners, relief agencies, policy makers, technology suppliers and researchers, representing 14 countries. One of the partners is the Austrian Institute of Technology (AIT). It has ten years’ experience in the development and validation of technological solutions for crisis prevention, interoperable systems, and for management of volunteers, together with theoretical and practical research with a focus on the software domain. It is deeply involved in the research on the similarity problem of definitions.
An essential step to an unambiguous terminology is understanding and measuring the similarity of existing definitions (Cregan, 2005) appearing in different documents such as standards, norms and instruction manuals. The measuring process should be easily understood and applied. The result should be compatible with the intuitive notion of similarity and should also fulfil the precision needs of practitioners in disaster management.
It is important to note that our notion of similarity differs from that of literary texts. Definitions require (as far as possible) precise description and/or identification of objects or processes, whilst literary texts evaluate similarity with respect to aesthetics, type of expressions, contents and readability.
Research offers several different methods for measuring the semantic similarity of definitions (Slimani, 2013): For our part of the project the “bag of words” method has been chosen (see Figure 1): A chosen set of parameters is applied to each definition (e.g. size of the disaster, type of actors). For each parameter a set of descriptive concepts is defined (the “bag-of-words”). The similarity between two definitions is computed from the number of concepts which occur in both definitions compared to the number of concepts that only occur in one definition.
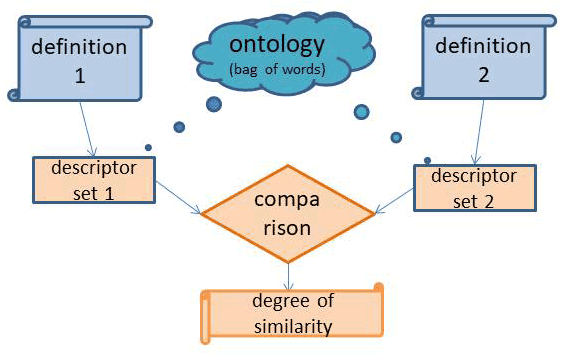
Figure 1: Basic comparison process.
As simple as this scheme looks, the difficulties – as usual – lie in the details, some of which include:
- Which concepts are to be included in the “bag of words”,
- which parameters are chosen to represent different aspects of a definition,
- how to express and consider synonyms, hierarchies of concepts, and sematic dependencies between concepts,
- how to convert the agreements/differences of concepts into numerical values (Lin, 1998).
The appeal of this method, however, is that, once established, it lends itself to application in other domains: It is “only” necessary to exchange the parameters and the associated bags-of- words.
Link: [L1] www.driver-project.eu/
References:
[1] A. M. Cregan: “Towards a science of definition”, in Proc. of the AOW ‘05, vol. 58, p. 25–32, Australian Computer Society, Inc., 2005
[2] D. Lin,: “An information-theoretic definition of similarity”, in Proc. of ICML 98, p. 296–304, 1998.
[3] T. Slimani: “Description and evaluation of semantic similarity measures approaches”, Intl. J. of Computer Applications 80(10), October 2013, p 25–33, 2013.
Please contact:
Georg Neubauer
Austrian Institute of Technology GmbH
+43 50 5500 2807,

