









by Stéphane P.A. Bordas, Sundararajan Natarajan, and Andreas Zilian (University of Luxembourg)
To work with digital twins, researchers must have the skills to select and adapt mathematical models to data as it is being acquired. Luxembourg’s National Research Fund (FNR) finances the first pan-Luxembourg Doctoral Training Centre in Data-DRIVEN Modelling and Discovery [L1], bridging artificial intelligence with modelling from first principles. The Centre will train the next generation researchers at the interface between computational and data science and application areas ranging from social inequalities to neurodegenerative diseases, through psychology and the science of science. These researchers will lay the foundations enabling digital twinning in a variety of application areas.
Why Computational and Data Sciences: opportunities and challenges
By enabling virtual experiments and computer simulations, scientific computing has become the third pillar of scientific investigation and is central to innovation in most domains of our lives (Rüde et al., 2018). It underpins the majority of today’s technological, economic and societal feats.
An upcoming challenge is to harvest the fruits borne by computational sciences in research fields which have not yet benefited from its full potential, e.g. biology, health, the social and behavioural sciences as well as art. Our strategy to achieve this is to leverage the mathematical, procedural and algorithmic commonality between apparently disparate research fields. Achieving this aim will require ever-increasing amounts of data to be harnessed (Ley and Bordas, 2017).
Data-Driven Discovery
Understanding the world, which generates data at an increasing rate, relies on the ability to construct models. To be predictive, or even descriptive, these models must be able to adapt to new information (science model selection, aggregation and adaptation).
We are therefore experiencing a change in paradigm from traditional, hypothesis-driven mathematical models to adaptive data-driven models, which are inherent to the concept of digital twins.
Data-driven discovery will become the fourth pillar of science, and the integration of hypothesis-driven and data-driven science concepts is the future of scientific discovery and knowledge generation, by improving decision-making at all levels.
Discovery through data requires integrated data mining, data exploration (interrogation and association), predictive modelling, sensitivity and uncertainty quantification and incorporation of feedback from new or higher quality data.
Methods
Machine learning and statistical analysis are fundamental to address the above issues and enable mapping input to output (supervised) and discovering the structure of input data (unsupervised learning).
Concepts like support vector machines and random forests can be used for pattern recognition. Similar objects are automatically grouped into sets with clustering using k-means, mean-shift or spectral clustering and thereby help with patient cohort segmentation or grouping experimental results. Continuous-valued attributes associated with an object or person can be predicted with regression algorithms like lasso, ridge regression or Gaussian processes. Model selection methods improve predictive models by enabling the comparison, validation and selection of models and parameters using grid search or cross validation.
Methods of dimensionality reduction help to unveil characteristic information hidden in large and/or high-dimensional data sets via principal component analysis, manifold learning or feature selection. Deep learning describes hierarchical learning from data representations by capturing various abstraction levels.
Scientific Outcomes and Orientation of the Project
DRIVEN’s scientific outcomes are expected to lead to strong novel results in each application domain. Yet, the most exciting scientific achievement brought forward by DRIVEN will be the design of novel multi-disciplinary methodologies. Moreover, the trained research students will become the first interdisciplinary translators able to fuel the third industrial revolution.
Challenges Ahead and Future Activities
The variety and power of machine learning and artificial intelligence techniques are steadily growing. While their ability to describe reality and discover unforeseen patterns in data is clear, our ability to critically evaluate uncertainty and the limitations of these approaches lags behind. More often than not, they are used as black boxes, delivering answers that cannot be easily understood. DRIVEN will investigate these issues by focusing on a few well-chosen fundamental problems in data classification, regression, model reduction and selection.
Ethics
DRIVEN’s research directions not only take into account shared technical or methodological similarities of research activities but also the implied ethical and philosophical issues related to the large-scale utilisation of data science techniques. This adds the important ethics co-dimension to the treatment of the addressed research questions and contributes to provoke the intellectual discussion between researchers across the fields by questioning and reflecting on the role of artificial intelligence in law, human labour and social equity.
Partners and ERCIM Collaborators
DRIVEN is led by Computational Engineering and Sciences (Zilian) at the University of Luxembourg in collaboration with Interdisciplinary Centres and the Luxembourgish research centres (LIST and LISER). The team will be provided with supplementary training provided through leading partners including U. Ghent, Inria (France) and ICES (University of Texas at Austin), through a Horizon 2020 TWINNING project (DRIVEN TWINNING).
DRIVEN reinforces complementary initiatives such as Digital Lëtzebuerg and the HPC project of common European interest (PCEI) and Big Data Enabled Applications and reaches out to the European Materials Modelling Council by contributing to the creation of data exchange mechanisms for “digital materials.”
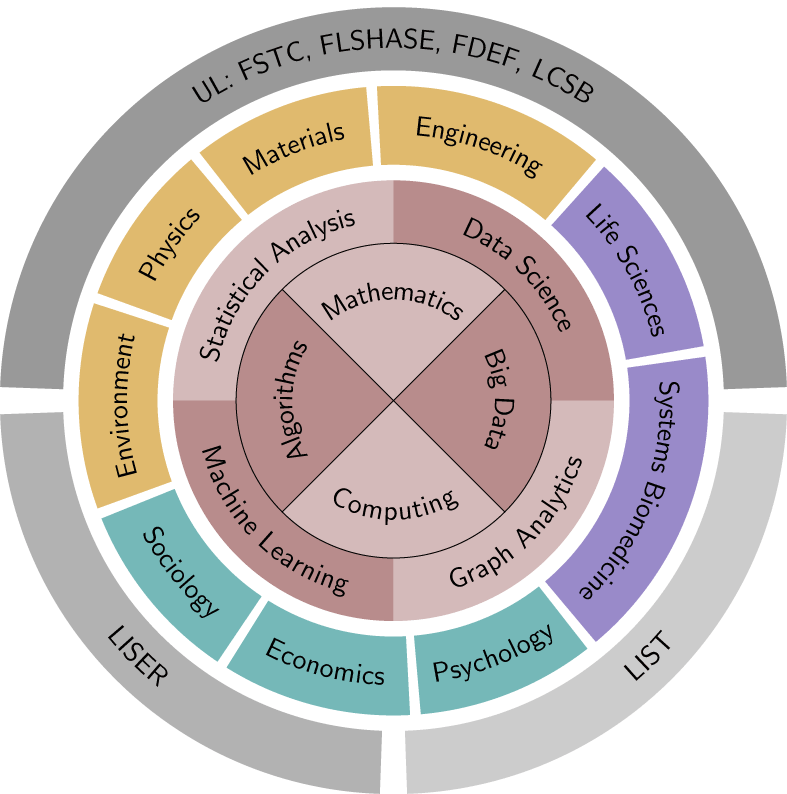
Computational and Data Sciences represent the methodological core common to a variety of data-driven applications targeted by DRIVEN‘s scientists at leading research institutions in Luxembourg.
Link:
[L1] https://driven.uni.lu
References:
[1] Ley C., SPA Bordas: “What makes Data Science different? A discussion involving Statistics 2.0 and Computational Sciences”, International Journal of Data Science and Analytics, 1-9, 2017.
[2] U. Rüde, et al.: “Research and education in computational science and engineering”, SIAM Review. 2018 Aug 8;60(3):707-54.
Please contact:
Stéphane Bordas
University of Luxembourg

